前言
上篇文章我們演示了為Configuration添加Etcd數據源,並且了解到為Configuration擴展自定義數據源還是非常簡單的,核心就是把數據源的數據按照一定的規則讀取到指定的字典里,這些都得益於微軟設計的合理性和便捷性。本篇文章我們將一起探究Configuration源碼,去了解Configuration到底是如何工作的。
ConfigurationBuilder
相信使用了.Net Core或者看過.Net Core源碼的同學都非常清楚,.Net Core使用了大量的Builder模式許多核心操作都是是用來了Builder模式,微軟在.Net Core使用了許多在傳統.Net框架上並未使用的設計模式,這也使得.Net Core使用更方便,代碼更合理。Configuration作為.Net Core的核心功能當然也不例外。
其實並沒有Configuration這個類,這隻是我們對配置模塊的代名詞。其核心是IConfiguration接口,IConfiguration又是由IConfigurationBuilder構建出來的,我們找到IConfigurationBuilder源碼大致定義如下
public interface IConfigurationBuilder
{
IDictionary<string, object> Properties { get; }
IList<IConfigurationSource> Sources { get; }
IConfigurationBuilder Add(IConfigurationSource source);
IConfigurationRoot Build();
}
Add方法我們上篇文章曾使用過,就是為ConfigurationBuilder添加ConfigurationSource數據源,添加的數據源被存放在Sources這個屬性里。當我們要使用IConfiguration的時候通過Build的方法得到IConfiguration實例,IConfigurationRoot接口是繼承自IConfiguration接口的,待會我們會探究這個接口。
我們找到IConfigurationBuilder的默認實現類ConfigurationBuilder大致代碼實現如下
public class ConfigurationBuilder : IConfigurationBuilder
{
/// <summary>
/// 添加的數據源被存放到了這裏
/// </summary>
public IList<IConfigurationSource> Sources { get; } = new List<IConfigurationSource>();
public IDictionary<string, object> Properties { get; } = new Dictionary<string, object>();
/// <summary>
/// 添加IConfigurationSource數據源
/// </summary>
/// <returns></returns>
public IConfigurationBuilder Add(IConfigurationSource source)
{
if (source == null)
{
throw new ArgumentNullException(nameof(source));
}
Sources.Add(source);
return this;
}
public IConfigurationRoot Build()
{
//獲取所有添加的IConfigurationSource里的IConfigurationProvider
var providers = new List<IConfigurationProvider>();
foreach (var source in Sources)
{
var provider = source.Build(this);
providers.Add(provider);
}
//用providers去實例化ConfigurationRoot
return new ConfigurationRoot(providers);
}
}
這個類的定義非常的簡單,相信大家都能看明白。其實整個IConfigurationBuilder的工作流程都非常簡單就是將IConfigurationSource添加到Sources中,然後通過Sources里的Provider去構建IConfigurationRoot。
Configuration
通過上面我們了解到通過ConfigurationBuilder構建出來的並非是直接實現IConfiguration的實現類而是另一個接口IConfigurationRoot
ConfigurationRoot
通過源代碼我們可以知道IConfigurationRoot是繼承自IConfiguration,具體定義關係如下
public interface IConfigurationRoot : IConfiguration
{
/// <summary>
/// 強制刷新數據
/// </summary>
/// <returns></returns>
void Reload();
IEnumerable<IConfigurationProvider> Providers { get; }
}
public interface IConfiguration
{
string this[string key] { get; set; }
/// <summary>
/// 獲取指定名稱子數據節點
/// </summary>
/// <returns></returns>
IConfigurationSection GetSection(string key);
/// <summary>
/// 獲取所有子數據節點
/// </summary>
/// <returns></returns>
IEnumerable<IConfigurationSection> GetChildren();
/// <summary>
/// 獲取IChangeToken用於當數據源有數據變化時,通知外部使用者
/// </summary>
/// <returns></returns>
IChangeToken GetReloadToken();
}
接下來我們查看IConfigurationRoot實現類ConfigurationRoot的大致實現,代碼有刪減
public class ConfigurationRoot : IConfigurationRoot, IDisposable
{
private readonly IList<IIConfigurationProvider> _providers;
private readonly IList<IDisposable> _changeTokenRegistrations;
private ConfigurationReloadToken _changeToken = new ConfigurationReloadToken();
public ConfigurationRoot(IList<IConfigurationProvider> providers)
{
_providers = providers;
_changeTokenRegistrations = new List<IDisposable>(providers.Count);
//通過便利的方式調用ConfigurationProvider的Load方法,將數據加載到每個ConfigurationProvider的字典里
foreach (var p in providers)
{
p.Load();
//監聽每個ConfigurationProvider的ReloadToken實現如果數據源發生變化去刷新Token通知外部發生變化
_changeTokenRegistrations.Add(ChangeToken.OnChange(() => p.GetReloadToken(), () => RaiseChanged()));
}
}
//// <summary>
/// 讀取或設置配置相關信息
/// </summary>
public string this[string key]
{
get
{
//通過這個我們可以了解到讀取的順序取決於註冊Source的順序,採用的是後來者居上的方式
//后註冊的會先被讀取到,如果讀取到直接return
for (var i = _providers.Count - 1; i >= 0; i--)
{
var provider = _providers[i];
if (provider.TryGet(key, out var value))
{
return value;
}
}
return null;
}
set
{
//這裏的設置只是把值放到內存中去,並不會持久化到相關數據源
foreach (var provider in _providers)
{
provider.Set(key, value);
}
}
}
public IEnumerable<IConfigurationSection> GetChildren() => this.GetChildrenImplementation(null);
public IChangeToken GetReloadToken() => _changeToken;
public IConfigurationSection GetSection(string key)
=> new ConfigurationSection(this, key);
//// <summary>
/// 手動調用該方法也可以實現強制刷新的效果
/// </summary>
public void Reload()
{
foreach (var provider in _providers)
{
provider.Load();
}
RaiseChanged();
}
//// <summary>
/// 強烈推薦不熟悉Interlocked的同學研究一下Interlocked具體用法
/// </summary>
private void RaiseChanged()
{
var previousToken = Interlocked.Exchange(ref _changeToken, new ConfigurationReloadToken());
previousToken.OnReload();
}
}
上面展示了ConfigurationRoot的核心實現其實主要就是兩點
- 讀取的方式其實是循環匹配註冊進來的每個provider里的數據,是後來者居上的模式,同名key后註冊進來的會先被讀取到,然後直接返回
- 構造ConfigurationRoot的時候才把數據加載到內存中,而且為註冊進來的每個provider設置監聽回調
ConfigurationSection
其實通過上面的代碼我們會產生一個疑問,獲取子節點數據返回的是另一個接口類型IConfigurationSection,我們來看下具體的定義
public interface IConfigurationSection : IConfiguration
{
string Key { get; }
string Path { get; }
string Value { get; set; }
}
這個接口也是繼承了IConfiguration,這就奇怪了分明只有一套配置IConfiguration,為什麼還要區分IConfigurationRoot和IConfigurationSection呢?其實不難理解因為Configuration可以同時承載許多不同的配置源,而IConfigurationRoot正是表示承載所有配置信息的根節點,而配置又是可以表示層級化的一種結構,在根配置里獲取下來的子節點是可以表示承載一套相關配置的另一套系統,所以單獨使用IConfigurationSection去表示,會顯得結構更清晰,比如我們有如下的json數據格式
{
"OrderId":"202005202220",
"Address":"銀河系太陽系火星",
"Total":666.66,
"Products":[
{
"Id":1,
"Name":"果子狸",
"Price":66.6,
"Detail":{
"Color":"棕色",
"Weight":"1000g"
}
},
{
"Id":2,
"Name":"蝙蝠",
"Price":55.5,
"Detail":{
"Color":"黑色",
"Weight":"200g"
}
}
]
}
我們知道json是一個結構化的存儲結構,其存儲元素分為三種一是簡單類型,二是對象類型,三是集合類型。但是字典是KV結構,並不存在結構化關係,在.Net Corez中配置系統是這麼解決的,比如以上信息存儲到字典中的結構就是這種
| Key | Value |
| OrderId | 202005202220 |
| Address | 銀河系太陽系火星 |
| Products:0:Id | 1 |
| Products:0:Name | 果子狸 |
| Products:0:Detail:Color | 棕色 |
| Products:1:Id | 2 |
| Products:1:Name | 蝙蝠 |
| Products:1:Detail:Weight | 200g |
如果我想獲取Products節點下的第一條商品數據直接
IConfigurationSection productSection = configuration.GetSection("Products:0")
類比到這裏的話根配置IConfigurationRoot里存儲了訂單的所有數據,獲取下來的子節點IConfigurationSection表示了訂單里第一個商品的信息,而這個商品也是一個完整的描述商品信息的數據系統,所以這樣可以更清晰的區分Configuration的結構,我們來看一下ConfigurationSection的大致實現
public class ConfigurationSection : IConfigurationSection
{
private readonly IConfigurationRoot _root;
private readonly string _path;
private string _key;
public ConfigurationSection(IConfigurationRoot root, string path)
{
_root = root;
_path = path;
}
public string Path => _path;
public string Key
{
get
{
return _key;
}
}
public string Value
{
get
{
return _root[Path];
}
set
{
_root[Path] = value;
}
}
public string this[string key]
{
get
{
//獲取當前Section下的數據其實就是組合了Path和Key
return _root[ConfigurationPath.Combine(Path, key)];
}
set
{
_root[ConfigurationPath.Combine(Path, key)] = value;
}
}
//獲取當前節點下的某個子節點也是組合當前的Path和子節點的標識Key
public IConfigurationSection GetSection(string key) => _root.GetSection(ConfigurationPath.Combine(Path, key));
//獲取當前節點下的所有子節點其實就是在字典里獲取包含當前Path字符串的所有Key
public IEnumerable<IConfigurationSection> GetChildren() => _root.GetChildrenImplementation(Path);
public IChangeToken GetReloadToken() => _root.GetReloadToken();
}
這裏我們可以看到既然有Key可以獲取字典里對應的Value了,為何還需要Path?通過ConfigurationRoot里的代碼我們可以知道Path的初始值其實就是獲取ConfigurationSection的Key,說白了其實就是如何獲取到當前IConfigurationSection的路徑。比如
//當前productSection的Path是 Products:0
IConfigurationSection productSection = configuration.GetSection("Products:0");
//當前productDetailSection的Path是 Products:0:Detail
IConfigurationSection productDetailSection = productSection.GetSection("Detail");
//獲取到pColor的全路徑就是 Products:0:Detail:Color
string pColor = productDetailSection["Color"];
而獲取Section所有子節點
GetChildrenImplementation來自於IConfigurationRoot的擴展方法
internal static class InternalConfigurationRootExtensions
{
//// <summary>
/// 其實就是在數據源字典里獲取Key包含給定Path的所有值
/// </summary>
internal static IEnumerable<IConfigurationSection> GetChildrenImplementation(this IConfigurationRoot root, string path)
{
return root.Providers
.Aggregate(Enumerable.Empty<string>(),
(seed, source) => source.GetChildKeys(seed, path))
.Distinct(StringComparer.OrdinalIgnoreCase)
.Select(key => root.GetSection(path == null ? key : ConfigurationPath.Combine(path, key)));
}
}
相信講到這裏,大家對ConfigurationSection或者是對Configuration整體的思路有一定的了解,細節上的設計確實不少。但是整體實現思路還是比較清晰的。關於Configuration還有一個比較重要的擴展方法就是將配置綁定到具體POCO的擴展方法,該方法承載在ConfigurationBinder擴展類了,由於實現比較複雜,也不是本篇文章的重點,有興趣的同學可以自行查閱,這裏就不做探究了。
總結
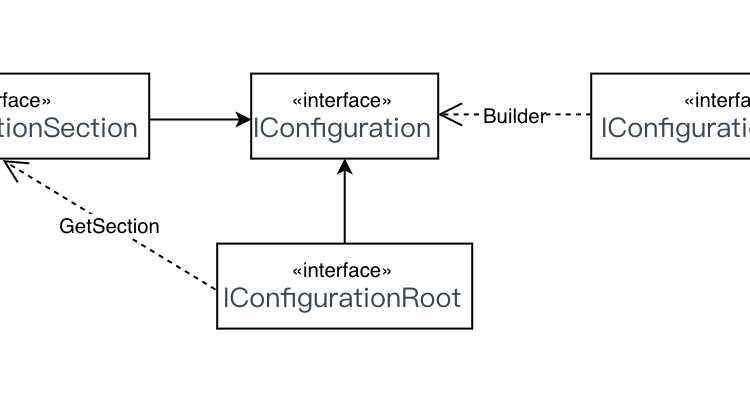
通過以上部分的講解,其實我們可以大概的將Configuration配置相關總結為兩大核心抽象接口IConfigurationBuilder,IConfiguration,整體結構關係可大致表示成如下關係
配置相關的整體實現思路就是IConfigurationSource作為一種特定類型的數據源,它提供了提供當前數據源的提供者ConfigurationProvider,Provider負責將數據源的數據按照一定的規則放入到字典里。IConfigurationSource添加到IConfigurationBuilder的容器中,後者使用Provide構建出整個程序的根配置容器IConfigurationRoot。通過獲取IConfigurationRoot子節點得到IConfigurationSection負責維護子節點容器相關。這二者都繼承自IConfiguration,然後通過他們就可以獲取到整個配置體系的數據數據操作了。
以上講解都是本人通過實踐和閱讀源碼得出的結論,可能會存在一定的偏差或理解上的誤區,但是我還是想把我的理解分享給大家,希望大家能多多包涵。如果有大家有不同的見解或者更深的理解,可以在評論區多多留言。
歡迎掃碼關注我的公眾號 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?