※推薦台中搬家公司優質服務,可到府估價
台中搬鋼琴,台中金庫搬運,中部廢棄物處理,南投縣搬家公司,好幫手搬家,西屯區搬家
| 好看請贊,養成習慣
現陸續將Demo代碼和技術文章整理在一起 Github實踐精選 ,方便大家閱讀查看,本文同樣收錄在此,覺得不錯,還請Star
寫在前面
進入源碼階段了,寫了十幾篇的 併發系列 知識鋪墊終於要派上用場了。相信很多人已經忘了其中的一些理論知識,別擔心,我會在源碼環節帶入相應的理論知識點幫助大家回憶,做到理論與實踐相結合,另外這是超長圖文,建議收藏,如果對你有用還請點贊讓更多人看到
Java SDK 為什麼要設計 Lock
曾幾何時幻想過,如果 Java 併發控制只有 synchronized 多好,只有下面三種使用方式,簡單方便
public class ThreeSync {
private static final Object object = new Object();
public synchronized void normalSyncMethod(){
//臨界區
}
public static synchronized void staticSyncMethod(){
//臨界區
}
public void syncBlockMethod(){
synchronized (object){
//臨界區
}
}
}
如果在 Java 1.5之前,確實是這樣,自從 1.5 版本 Doug Lea 大師就重新造了一個輪子 Lock
我們常說:“避免重複造輪子”,如果有了輪子還是要堅持再造個輪子,那麼肯定傳統的輪子在某些應用場景中不能很好的解決問題
不知你是否還記得 Coffman 總結的四個可以發生死鎖的情形 ,其中【不可剝奪條件】是指:
線程已經獲得資源,在未使用完之前,不能被剝奪,只能在使用完時自己釋放
要想破壞這個條件,就需要具有申請不到進一步資源就釋放已有資源的能力
很顯然,這個能力是 synchronized 不具備的,使用 synchronized ,如果線程申請不到資源就會進入阻塞狀態,我們做什麼也改變不了它的狀態,這是 synchronized 輪子的致命弱點,這就強有力的給了重造輪子 Lock 的理由
顯式鎖 Lock
舊輪子有弱點,新輪子就要解決這些問題,所以要具備不會阻塞的功能,下面的三個方案都是解決這個問題的好辦法(看下面表格描述你就明白三個方案的含義了)
| 特性 |
描述 |
API |
| 能響應中斷 |
如果不能自己釋放,那可以響應中斷也是很好的。Java多線程中斷機制 專門描述了中斷過程,目的是通過中斷信號來跳出某種狀態,比如阻塞 |
lockInterruptbly() |
| 非阻塞式的獲取鎖 |
嘗試獲取,獲取不到不會阻塞,直接返回 |
tryLock() |
| 支持超時 |
給定一個時間限制,如果一段時間內沒獲取到,不是進入阻塞狀態,同樣直接返回 |
tryLock(long time, timeUnit) |
好的方案有了,但魚和熊掌不可兼得,Lock 多了 synchronized 不具備的特性,自然不會像 synchronized 那樣一個關鍵字三個玩法走遍全天下,在使用上也相對複雜了一丟丟
Lock 使用範式
synchronized 有標準用法,這樣的優良傳統咱 Lock 也得有,相信很多人都知道使用 Lock 的一個範式
Lock lock = new ReentrantLock();
lock.lock();
try{
...
}finally{
lock.unlock();
}
既然是範式(沒事不要挑戰更改寫法的那種),肯定有其理由,我們來看一下
標準1—finally 中釋放鎖
這個大家應該都會明白,在 finally 中釋放鎖,目的是保證在獲取到鎖之後,最終能被釋放
標準2—在 try{} 外面獲取鎖
不知道你有沒有想過,為什麼會有標準 2 的存在,我們通常是“喜歡” try 住所有內容,生怕發生異常不能捕獲的
在 try{} 外獲取鎖主要考慮兩個方面:
- 如果沒有獲取到鎖就拋出異常,最終釋放鎖肯定是有問題的,因為還未曾擁有鎖談何釋放鎖呢
- 如果在獲取鎖時拋出了異常,也就是當前線程並未獲取到鎖,但執行到 finally 代碼時,如果恰巧別的線程獲取到了鎖,則會被釋放掉(無故釋放)
不同鎖的實現方式略有不同,範式的存在就是要避免一切問題的出現,所以大家盡量遵守範式
Lock 是怎樣起到鎖的作用呢?
如果你熟悉 synchronized,你知道程序編譯成 CPU 指令后,在臨界區會有 moniterenter 和 moniterexit 指令的出現,可以理解成進出臨界區的標識
從範式上來看:
那 Lock 是怎麼做到的呢?
這裏先簡單說明一下,這樣一會到源碼分析時,你可以遠觀設計輪廓,近觀實現細節,會變得越發輕鬆
其實很簡單,比如在 ReentrantLock 內部維護了一個 volatile 修飾的變量 state,通過 CAS 來進行讀寫(最底層還是交給硬件來保證原子性和可見性),如果CAS更改成功,即獲取到鎖,線程進入到 try 代碼塊繼續執行;如果沒有更改成功,線程會被【掛起】,不會向下執行
但 Lock 是一個接口,裏面根本沒有 state 這個變量的存在:
它怎麼處理這個 state 呢?很顯然需要一點設計的加成了,接口定義行為,具體都是需要實現類的
Lock 接口的實現類基本都是通過【聚合】了一個【隊列同步器】的子類完成線程訪問控制的
那什麼是隊列同步器呢? (這應該是你見過的最強標題黨,聊了半個世紀才入正題,評論區留言罵我)
隊列同步器 AQS
隊列同步器 (AbstractQueuedSynchronizer),簡稱同步器或AQS,就是我們今天的主人公
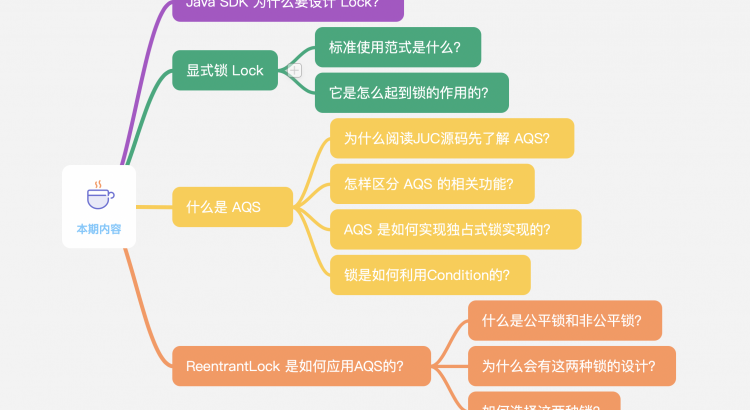
問:為什麼你分析 JUC 源碼,要從 AQS 說起呢?
答:看下圖
相信看到這個截圖你就明白一二了,你聽過的,面試常被問起的,工作中常用的
ReentrantLockReentrantReadWriteLockSemaphore(信號量)CountDownLatch公平鎖非公平鎖ThreadPoolExecutor (關於線程池的理解,可以查看 為什麼要使用線程池? )
都和 AQS 有直接關係,所以了解 AQS 的抽象實現,在此基礎上再稍稍查看上述各類的實現細節,很快就可以全部搞定,不至於查看源碼時一頭霧水,丟失主線
上面提到,在鎖的實現類中會聚合同步器,然後利同步器實現鎖的語義,那麼問題來了:
為什麼要用聚合模式,怎麼進一步理解鎖和同步器的關係呢?
我們絕大多數都是在使用鎖,實現鎖之後,其核心就是要使用方便
從 AQS 的類名稱和修飾上來看,這是一個抽象類,所以從設計模式的角度來看同步器一定是基於【模版模式】來設計的,使用者需要繼承同步器,實現自定義同步器,並重寫指定方法,隨後將同步器組合在自定義的同步組件中,並調用同步器的模版方法,而這些模版方法又回調用使用者重寫的方法
我不想將上面的解釋說的這麼抽象,其實想理解上面這句話,我們只需要知道下面兩個問題就好了
- 哪些是自定義同步器可重寫的方法?
- 哪些是抽象同步器提供的模版方法?
同步器可重寫的方法
同步器提供的可重寫方法只有5個,這大大方便了鎖的使用者:
按理說,需要重寫的方法也應該有 abstract 來修飾的,為什麼這裏沒有?原因其實很簡單,上面的方法我已經用顏色區分成了兩類:
自定義的同步組件或者鎖不可能既是獨佔式又是共享式,為了避免強制重寫不相干方法,所以就沒有 abstract 來修飾了,但要拋出異常告知不能直接使用該方法:
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
暖暖的很貼心(如果你有類似的需求也可以仿照這樣的設計)
表格方法描述中所說的同步狀態就是上文提到的有 volatile 修飾的 state,所以我們在重寫上面幾個方法時,還要通過同步器提供的下面三個方法(AQS 提供的)來獲取或修改同步狀態:
而獨佔式和共享式操作 state 變量的區別也就很簡單了
所以你看到的 ReentrantLock ReentrantReadWriteLock Semaphore(信號量) CountDownLatch 這幾個類其實僅僅是在實現以上幾個方法上略有差別,其他的實現都是通過同步器的模版方法來實現的,到這裡是不是心情放鬆了許多呢?我們來看一看模版方法:
同步器提供的模版方法
上面我們將同步器的實現方法分為獨佔式和共享式兩類,模版方法其實除了提供以上兩類模版方法之外,只是多了響應中斷和超時限制 的模版方法供 Lock 使用,來看一下
先不用記上述方法的功能,目前你只需要了解個大概功能就好。另外,相信你也注意到了:
上面的方法都有 final 關鍵字修飾,說明子類不能重寫這個方法
看到這你也許有點亂了,我們稍微歸納一下:
程序員還是看代碼心裏踏實一點,我們再來用代碼說明一下上面的關係(注意代碼中的註釋,以下的代碼並不是很嚴謹,只是為了簡單說明上圖的代碼實現):
package top.dayarch.myjuc;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* 自定義互斥鎖
*
* @author tanrgyb
* @date 2020/5/23 9:33 PM
*/
public class MyMutex implements Lock {
// 靜態內部類-自定義同步器
private static class MySync extends AbstractQueuedSynchronizer{
@Override
protected boolean tryAcquire(int arg) {
// 調用AQS提供的方法,通過CAS保證原子性
if (compareAndSetState(0, arg)){
// 我們實現的是互斥鎖,所以標記獲取到同步狀態(更新state成功)的線程,
// 主要為了判斷是否可重入(一會兒會說明)
setExclusiveOwnerThread(Thread.currentThread());
//獲取同步狀態成功,返回 true
return true;
}
// 獲取同步狀態失敗,返回 false
return false;
}
@Override
protected boolean tryRelease(int arg) {
// 未擁有鎖卻讓釋放,會拋出IMSE
if (getState() == 0){
throw new IllegalMonitorStateException();
}
// 可以釋放,清空排它線程標記
setExclusiveOwnerThread(null);
// 設置同步狀態為0,表示釋放鎖
setState(0);
return true;
}
// 是否獨佔式持有
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 後續會用到,主要用於等待/通知機制,每個condition都有一個與之對應的條件等待隊列,在鎖模型中說明過
Condition newCondition() {
return new ConditionObject();
}
}
// 聚合自定義同步器
private final MySync sync = new MySync();
@Override
public void lock() {
// 阻塞式的獲取鎖,調用同步器模版方法獨佔式,獲取同步狀態
sync.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
// 調用同步器模版方法可中斷式獲取同步狀態
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
// 調用自己重寫的方法,非阻塞式的獲取同步狀態
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
// 調用同步器模版方法,可響應中斷和超時時間限制
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
@Override
public void unlock() {
// 釋放鎖
sync.release(1);
}
@Override
public Condition newCondition() {
// 使用自定義的條件
return sync.newCondition();
}
}
如果你現在打開 IDE, 你會發現上文提到的 ReentrantLock ReentrantReadWriteLock Semaphore(信號量) CountDownLatch 都是按照這個結構實現,所以我們就來看一看 AQS 的模版方法到底是怎麼實現鎖
AQS實現分析
從上面的代碼中,你應該理解了lock.tryLock() 非阻塞式獲取鎖就是調用自定義同步器重寫的 tryAcquire() 方法,通過 CAS 設置state 狀態,不管成功與否都會馬上返回;那麼 lock.lock() 這種阻塞式的鎖是如何實現的呢?
有阻塞就需要排隊,實現排隊必然需要隊列
CLH:Craig、Landin and Hagersten 隊列,是一個單向鏈表,AQS中的隊列是CLH變體的虛擬雙向隊列(FIFO)——概念了解就好,不要記
隊列中每個排隊的個體就是一個 Node,所以我們來看一下 Node 的結構
Node 節點
AQS 內部維護了一個同步隊列,用於管理同步狀態。
- 當線程獲取同步狀態失敗時,就會將當前線程以及等待狀態等信息構造成一個 Node 節點,將其加入到同步隊列中尾部,阻塞該線程
- 當同步狀態被釋放時,會喚醒同步隊列中“首節點”的線程獲取同步狀態
為了將上述步驟弄清楚,我們需要來看一看 Node 結構 (如果你能打開 IDE 一起看那是極好的)
乍一看有點雜亂,我們還是將其歸類說明一下:
上面這幾個狀態說明有個印象就好,有了Node 的結構說明鋪墊,你也就能想象同步隊列的接本結構了:
前置知識基本鋪墊完畢,我們來看一看獨佔式獲取同步狀態的整個過程
獨佔式獲取同步狀態
故事要從範式lock.lock() 開始
public void lock() {
// 阻塞式的獲取鎖,調用同步器模版方法,獲取同步狀態
sync.acquire(1);
}
進入AQS的模版方法 acquire()
public final void acquire(int arg) {
// 調用自定義同步器重寫的 tryAcquire 方法
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
首先,也會嘗試非阻塞的獲取同步狀態,如果獲取失敗(tryAcquire返回false),則會調用 addWaiter 方法構造 Node 節點(Node.EXCLUSIVE 獨佔式)並安全的(CAS)加入到同步隊列【尾部】
private Node addWaiter(Node mode) {
// 構造Node節點,包含當前線程信息以及節點模式【獨佔/共享】
Node node = new Node(Thread.currentThread(), mode);
// 新建變量 pred 將指針指向tail指向的節點
Node pred = tail;
// 如果尾節點不為空
if (pred != null) {
// 新加入的節點前驅節點指向尾節點
node.prev = pred;
// 因為如果多個線程同時獲取同步狀態失敗都會執行這段代碼
// 所以,通過 CAS 方式確保安全的設置當前節點為最新的尾節點
if (compareAndSetTail(pred, node)) {
// 曾經的尾節點的後繼節點指向當前節點
pred.next = node;
// 返回新構建的節點
return node;
}
}
// 尾節點為空,說明當前節點是第一個被加入到同步隊列中的節點
// 需要一個入隊操作
enq(node);
return node;
}
private Node enq(final Node node) {
// 通過“死循環”確保節點被正確添加,最終將其設置為尾節點之後才會返回,這裏使用 CAS 的理由和上面一樣
for (;;) {
Node t = tail;
// 第一次循環,如果尾節點為 null
if (t == null) { // Must initialize
// 構建一個哨兵節點,並將頭部指針指向它
if (compareAndSetHead(new Node()))
// 尾部指針同樣指向哨兵節點
tail = head;
} else {
// 第二次循環,將新節點的前驅節點指向t
node.prev = t;
// 將新節點加入到隊列尾節點
if (compareAndSetTail(t, node)) {
// 前驅節點的後繼節點指向當前新節點,完成雙向隊列
t.next = node;
return t;
}
}
}
}
你可能比較迷惑 enq() 的處理方式,進入該方法就是一個“死循環”,我們就用圖來描述它是怎樣跳出循環的
有些同學可能會有疑問,為什麼會有哨兵節點?
哨兵,顧名思義,是用來解決國家之間邊界問題的,不直接參与生產活動。同樣,計算機科學中提到的哨兵,也用來解決邊界問題,如果沒有邊界,指定環節,按照同樣算法可能會在邊界處發生異常,比如要繼續向下分析的 acquireQueued() 方法
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// "死循環",嘗試獲取鎖,或者掛起
for (;;) {
// 獲取當前節點的前驅節點
final Node p = node.predecessor();
// 只有當前節點的前驅節點是頭節點,才會嘗試獲取鎖
// 看到這你應該理解添加哨兵節點的含義了吧
if (p == head && tryAcquire(arg)) {
// 獲取同步狀態成功,將自己設置為頭
setHead(node);
// 將哨兵節點的後繼節點置為空,方便GC
p.next = null; // help GC
failed = false;
// 返回中斷標識
return interrupted;
}
// 當前節點的前驅節點不是頭節點
//【或者】當前節點的前驅節點是頭節點但獲取同步狀態失敗
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
獲取同步狀態成功會返回可以理解了,但是如果失敗就會一直陷入到“死循環”中浪費資源嗎?很顯然不是,shouldParkAfterFailedAcquire(p, node) 和 parkAndCheckInterrupt() 就會將線程獲取同步狀態失敗的線程掛起,我們繼續向下看
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 獲取前驅節點的狀態
int ws = pred.waitStatus;
// 如果是 SIGNAL 狀態,即等待被佔用的資源釋放,直接返回 true
// 準備繼續調用 parkAndCheckInterrupt 方法
if (ws == Node.SIGNAL)
return true;
// ws 大於0說明是CANCELLED狀態,
if (ws > 0) {
// 循環判斷前驅節點的前驅節點是否也為CANCELLED狀態,忽略該狀態的節點,重新連接隊列
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 將當前節點的前驅節點設置為設置為 SIGNAL 狀態,用於後續喚醒操作
// 程序第一次執行到這返回為false,還會進行外層第二次循環,最終從代碼第7行返回
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
到這裏你也許有個問題:
這個地方設置前驅節點為 SIGNAL 狀態到底有什麼作用?
保留這個問題,我們陸續揭曉
如果前驅節點的 waitStatus 是 SIGNAL狀態,即 shouldParkAfterFailedAcquire 方法會返回 true ,程序會繼續向下執行 parkAndCheckInterrupt 方法,用於將當前線程掛起
private final boolean parkAndCheckInterrupt() {
// 線程掛起,程序不會繼續向下執行
LockSupport.park(this);
// 根據 park 方法 API描述,程序在下述三種情況會繼續向下執行
// 1. 被 unpark
// 2. 被中斷(interrupt)
// 3. 其他不合邏輯的返回才會繼續向下執行
// 因上述三種情況程序執行至此,返回當前線程的中斷狀態,並清空中斷狀態
// 如果由於被中斷,該方法會返回 true
return Thread.interrupted();
}
被喚醒的程序會繼續執行 acquireQueued 方法里的循環,如果獲取同步狀態成功,則會返回 interrupted = true 的結果
程序繼續向調用棧上層返回,最終回到 AQS 的模版方法 acquire
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
你也許會有疑惑:
程序已經成功獲取到同步狀態並返回了,怎麼會有個自我中斷呢?
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
如果你不能理解中斷,強烈建議你回看 Java多線程中斷機制
到這裏關於獲取同步狀態我們還遺漏了一條線,acquireQueued 的 finally 代碼塊如果你仔細看你也許馬上就會有疑惑:
到底什麼情況才會執行 if(failed) 裏面的代碼 ?
if (failed)
cancelAcquire(node);
這段代碼被執行的條件是 failed 為 true,正常情況下,如果跳出循環,failed 的值為false,如果不能跳出循環貌似怎麼也不能執行到這裏,所以只有不正常的情況才會執行到這裏,也就是會發生異常,才會執行到此處
查看 try 代碼塊,只有兩個方法會拋出異常:
-
node.processor() 方法
※台中搬家公司教你幾個打包小技巧,輕鬆整理裝箱!
還在煩惱搬家費用要多少哪?台中大展搬家線上試算搬家費用,從此不再擔心「物品怎麼計費」、「多少車才能裝完」
-
自己重寫的 tryAcquire() 方法
先看前者:
很顯然,這裏拋出的異常不是重點,那就以 ReentrantLock 重寫的 tryAcquire() 方法為例
另外,上面分析 shouldParkAfterFailedAcquire 方法還對 CANCELLED 的狀態進行了判斷,那麼
什麼時候會生成取消狀態的節點呢?
答案就在 cancelAcquire 方法中, 我們來看看 cancelAcquire到底怎麼設置/處理 CANNELLED 的
private void cancelAcquire(Node node) {
// 忽略無效節點
if (node == null)
return;
// 將關聯的線程信息清空
node.thread = null;
// 跳過同樣是取消狀態的前驅節點
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// 跳出上面循環后找到前驅有效節點,並獲取該有效節點的後繼節點
Node predNext = pred.next;
// 將當前節點的狀態置為 CANCELLED
node.waitStatus = Node.CANCELLED;
// 如果當前節點處在尾節點,直接從隊列中刪除自己就好
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
int ws;
// 1. 如果當前節點的有效前驅節點不是頭節點,也就是說當前節點不是頭節點的後繼節點
if (pred != head &&
// 2. 判斷當前節點有效前驅節點的狀態是否為 SIGNAL
((ws = pred.waitStatus) == Node.SIGNAL ||
// 3. 如果不是,嘗試將前驅節點的狀態置為 SIGNAL
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
// 判斷當前節點有效前驅節點的線程信息是否為空
pred.thread != null) {
// 上述條件滿足
Node next = node.next;
// 將當前節點有效前驅節點的後繼節點指針指向當前節點的後繼節點
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 如果當前節點的前驅節點是頭節點,或者上述其他條件不滿足,就喚醒當前節點的後繼節點
unparkSuccessor(node);
}
node.next = node; // help GC
}
看到這個註釋你可能有些亂了,其核心目的就是從等待隊列中移除 CANCELLED 的節點,並重新拼接整個隊列,總結來看,其實設置 CANCELLED 狀態節點只是有三種情況,我們通過畫圖來分析一下:
至此,獲取同步狀態的過程就結束了,我們簡單的用流程圖說明一下整個過程
獲取鎖的過程就這樣的結束了,先暫停幾分鐘整理一下自己的思路。我們上面還沒有說明 SIGNAL 的作用, SIGNAL 狀態信號到底是干什麼用的?這就涉及到鎖的釋放了,我們來繼續了解,整體思路和鎖的獲取是一樣的, 但是釋放過程就相對簡單很多了
獨佔式釋放同步狀態
故事要從 unlock() 方法說起
public void unlock() {
// 釋放鎖
sync.release(1);
}
調用 AQS 模版方法 release,進入該方法
public final boolean release(int arg) {
// 調用自定義同步器重寫的 tryRelease 方法嘗試釋放同步狀態
if (tryRelease(arg)) {
// 釋放成功,獲取頭節點
Node h = head;
// 存在頭節點,並且waitStatus不是初始狀態
// 通過獲取的過程我們已經分析了,在獲取的過程中會將 waitStatus的值從初始狀態更新成 SIGNAL 狀態
if (h != null && h.waitStatus != 0)
// 解除線程掛起狀態
unparkSuccessor(h);
return true;
}
return false;
}
查看 unparkSuccessor 方法,實際是要喚醒頭節點的後繼節點
private void unparkSuccessor(Node node) {
// 獲取頭節點的waitStatus
int ws = node.waitStatus;
if (ws < 0)
// 清空頭節點的waitStatus值,即置為0
compareAndSetWaitStatus(node, ws, 0);
// 獲取頭節點的後繼節點
Node s = node.next;
// 判斷當前節點的後繼節點是否是取消狀態,如果是,需要移除,重新連接隊列
if (s == null || s.waitStatus > 0) {
s = null;
// 從尾節點向前查找,找到隊列第一個waitStatus狀態小於0的節點
for (Node t = tail; t != null && t != node; t = t.prev)
// 如果是獨佔式,這裏小於0,其實就是 SIGNAL
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
// 解除線程掛起狀態
LockSupport.unpark(s.thread);
}
有同學可能有疑問:
為什麼這個地方是從隊列尾部向前查找不是 CANCELLED 的節點?
原因有兩個:
第一,先回看節點加入隊列的情景:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
節點入隊並不是原子操作,代碼第6、7行
node.prev = pred;
compareAndSetTail(pred, node)
這兩個地方可以看作是尾節點入隊的原子操作,如果此時代碼還沒執行到 pred.next = node; 這時又恰巧執行了unparkSuccessor方法,就沒辦法從前往後找了,因為後繼指針還沒有連接起來,所以需要從后往前找
第二點原因,在上面圖解產生 CANCELLED 狀態節點的時候,先斷開的是 Next 指針,Prev指針並未斷開,因此這也是必須要從后往前遍歷才能夠遍歷完全部的Node
同步狀態至此就已經成功釋放了,之前獲取同步狀態被掛起的線程就會被喚醒,繼續從下面代碼第 3 行返回執行:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
繼續返回上層調用棧, 從下面代碼15行開始執行,重新執行循環,再次嘗試獲取同步狀態
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
到這裏,關於獨佔式獲取/釋放鎖的流程已經閉環了,但是關於 AQS 的另外兩個模版方法還沒有介紹
獨佔式響應中斷獲取同步狀態
故事要從lock.lockInterruptibly() 方法說起
public void lockInterruptibly() throws InterruptedException {
// 調用同步器模版方法可中斷式獲取同步狀態
sync.acquireInterruptibly(1);
}
有了前面的理解,理解獨佔式可響應中斷的獲取同步狀態方式,真是一眼就能明白了:
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 嘗試非阻塞式獲取同步狀態失敗,如果沒有獲取到同步狀態,執行代碼7行
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
繼續查看 doAcquireInterruptibly 方法:
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 獲取中斷信號后,不再返回 interrupted = true 的值,而是直接拋出 InterruptedException
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
沒想到 JDK 內部也有如此相近的代碼,可響應中斷獲取鎖沒什麼深奧的,就是被中斷拋出 InterruptedException 異常(代碼第17行),這樣就逐層返回上層調用棧捕獲該異常進行下一步操作了
趁熱打鐵,來看看另外一個模版方法:
獨佔式超時限制獲取同步狀態
這個很好理解,就是給定一個時限,在該時間段內獲取到同步狀態,就返回 true, 否則,返回 false。好比線程給自己定了一個鬧鐘,鬧鈴一響,線程就自己返回了,這就不會使自己是阻塞狀態了
既然涉及到超時限制,其核心邏輯肯定是計算時間間隔,因為在超時時間內,肯定是多次嘗試獲取鎖的,每次獲取鎖肯定有時間消耗,所以計算時間間隔的邏輯就像我們在程序打印程序耗時 log 那麼簡單
nanosTimeout = deadline – System.nanoTime()
故事要從 lock.tryLock(time, unit) 方法說起
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
// 調用同步器模版方法,可響應中斷和超時時間限制
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
來看 tryAcquireNanos 方法
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
是不是和上面 acquireInterruptibly 方法長相很詳細了,繼續查看來 doAcquireNanos 方法,看程序, 該方法也是 throws InterruptedException,我們在中斷文章中說過,方法標記上有 throws InterruptedException 說明該方法也是可以響應中斷的,所以你可以理解超時限制是 acquireInterruptibly 方法的加強版,具有超時和非阻塞控制的雙保險
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
// 超時時間內,為獲取到同步狀態,直接返回false
if (nanosTimeout <= 0L)
return false;
// 計算超時截止時間
final long deadline = System.nanoTime() + nanosTimeout;
// 以獨佔方式加入到同步隊列中
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
// 計算新的超時時間
nanosTimeout = deadline - System.nanoTime();
// 如果超時,直接返回 false
if (nanosTimeout <= 0L)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
// 判斷是最新超時時間是否大於閾值 1000
nanosTimeout > spinForTimeoutThreshold)
// 掛起線程 nanosTimeout 長時間,時間到,自動返回
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上面的方法應該不是很難懂,但是又同學可能在第 27 行上有所困惑
為什麼 nanosTimeout 和 自旋超時閾值1000進行比較?
/**
* The number of nanoseconds for which it is faster to spin
* rather than to use timed park. A rough estimate suffices
* to improve responsiveness with very short timeouts.
*/
static final long spinForTimeoutThreshold = 1000L;
其實 doc 說的很清楚,說白了,1000 nanoseconds 時間已經非常非常短暫了,沒必要再執行掛起和喚醒操作了,不如直接當前線程直接進入下一次循環
到這裏,我們自定義的 MyMutex 只差 Condition 沒有說明了,不知道你累了嗎?我還在堅持
Condition
如果你看過之前寫的 併發編程之等待通知機制 ,你應該對下面這個圖是有印象的:
如果當時你理解了這個模型,再看 Condition 的實現,根本就不是問題了,首先 Condition 還是一個接口,肯定也是需要有實現類的
那故事就從 lock.newnewCondition 說起吧
public Condition newCondition() {
// 使用自定義的條件
return sync.newCondition();
}
自定義同步器重封裝了該方法:
Condition newCondition() {
return new ConditionObject();
}
ConditionObject 就是 Condition 的實現類,該類就定義在了 AQS 中,只有兩個成員變量:
/** First node of condition queue. */
private transient Node firstWaiter;
/** Last node of condition queue. */
private transient Node lastWaiter;
所以,我們只需要來看一下 ConditionObject 實現的 await / signal 方法來使用這兩個成員變量就可以了
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 同樣構建 Node 節點,並加入到等待隊列中
Node node = addConditionWaiter();
// 釋放同步狀態
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
// 掛起當前線程
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
這裏注意用詞,在介紹獲取同步狀態時,addWaiter 是加入到【同步隊列】,就是上圖說的入口等待隊列,這裏說的是【等待隊列】,所以 addConditionWaiter 肯定是構建了一個自己的隊列:
private Node addConditionWaiter() {
Node t = lastWaiter;
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// 新構建的節點的 waitStatus 是 CONDITION,注意不是 0 或 SIGNAL 了
Node node = new Node(Thread.currentThread(), Node.CONDITION);
// 構建單向同步隊列
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
這裡有朋友可能會有疑問:
為什麼這裡是單向隊列,也沒有使用CAS 來保證加入隊列的安全性呢?
因為 await 是 Lock 範式 try 中使用的,說明已經獲取到鎖了,所以就沒必要使用 CAS 了,至於是單向,因為這裏還不涉及到競爭鎖,只是做一個條件等待隊列
在 Lock 中可以定義多個條件,每個條件都會對應一個 條件等待隊列,所以將上圖豐富說明一下就變成了這個樣子:
線程已經按相應的條件加入到了條件等待隊列中,那如何再嘗試獲取鎖呢?signal / signalAll 方法就已經排上用場了
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
Signal 方法通過調用 doSignal 方法,只喚醒條件等待隊列中的第一個節點
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
// 調用該方法,將條件等待隊列的線程節點移動到同步隊列中
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
繼續看 transferForSignal 方法
final boolean transferForSignal(Node node) {
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
// 重新進行入隊操作
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
// 喚醒同步隊列中該線程
LockSupport.unpark(node.thread);
return true;
}
所以我們再用圖解一下喚醒的整個過程
到這裏,理解 signalAll 就非常簡單了,只不過循環判斷是否還有 nextWaiter,如果有就像 signal 操作一樣,將其從條件等待隊列中移到同步隊列中
private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
不知你還是否記得,我在併發編程之等待通知機制 中還說過一句話
沒有特殊原因盡量用 signalAll 方法
什麼時候可以用 signal 方法也在其中做了說明,請大家自行查看吧
這裏我還要多說一個細節,從條件等待隊列移到同步隊列是有時間差的,所以使用 await() 方法也是範式的, 同樣在該文章中做了解釋
有時間差,就會有公平和不公平的問題,想要全面了解這個問題,我們就要走近 ReentrantLock 中來看了,除了了解公平/不公平問題,查看 ReentrantLock 的應用還是要反過來驗證它使用的AQS的,我們繼續吧
ReentrantLock 是如何應用的AQS
獨佔式的典型應用就是 ReentrantLock 了,我們來看看它是如何重寫這個方法的
乍一看挺奇怪的,怎麼裏面自定義了三個同步器:其實 NonfairSync,FairSync 只是對 Sync 做了進一步劃分:
從名稱上你應該也知道了,這就是你聽到過的 公平鎖/非公平鎖了
何為公平鎖/非公平鎖?
生活中,排隊講求先來後到視為公平。程序中的公平性也是符合請求鎖的絕對時間的,其實就是 FIFO,否則視為不公平
我們來對比一下 ReentrantLock 是如何實現公平鎖和非公平鎖的
其實沒什麼大不了,公平鎖就是判斷同步隊列是否還有先驅節點的存在,只有沒有先驅節點才能獲取鎖;而非公平鎖是不管這個事的,能獲取到同步狀態就可以,就這麼簡單,那問題來了:
為什麼會有公平鎖/非公平鎖的設計?
考慮這個問題,我們需重新回憶上面的鎖獲取實現圖了,其實上面我已經透露了一點
主要有兩點原因:
原因一:
恢復掛起的線程到真正鎖的獲取還是有時間差的,從人類的角度來看這個時間微乎其微,但是從CPU的角度來看,這個時間差存在的還是很明顯的。所以非公平鎖能更充分的利用 CPU 的時間片,盡量減少 CPU 空閑狀態時間
原因二:
不知你是否還記得我在 面試問,創建多少個線程合適? 文章中反覆提到過,使用多線程很重要的考量點是線程切換的開銷,想象一下,如果採用非公平鎖,當一個線程請求鎖獲取同步狀態,然後釋放同步狀態,因為不需要考慮是否還有前驅節點,所以剛釋放鎖的線程在此刻再次獲取同步狀態的幾率就變得非常大,所以就減少了線程的開銷
相信到這裏,你也就明白了,為什麼 ReentrantLock 默認構造器用的是非公平鎖同步器
public ReentrantLock() {
sync = new NonfairSync();
}
看到這裏,感覺非公平鎖 perfect,非也,有得必有失
使用公平鎖會有什麼問題?
公平鎖保證了排隊的公平性,非公平鎖霸氣的忽視這個規則,所以就有可能導致排隊的長時間在排隊,也沒有機會獲取到鎖,這就是傳說中的 “飢餓”
如何選擇公平鎖/非公平鎖?
相信到這裏,答案已經在你心中了,如果為了更高的吞吐量,很顯然非公平鎖是比較合適的,因為節省很多線程切換時間,吞吐量自然就上去了,否則那就用公平鎖還大家一個公平
我們還差最後一個環節,真的要挺住
可重入鎖
到這裏,我們還沒分析 ReentrantLock 的名字,JDK 起名這麼有講究,肯定有其含義,直譯過來【可重入鎖】
為什麼要支持鎖的重入?
試想,如果是一個有 synchronized 修飾的遞歸調用方法,程序第二次進入被自己阻塞了豈不是很大的笑話,所以 synchronized 是支持鎖的重入的
Lock 是新輪子,自然也要支持這個功能,其實現也很簡單,請查看公平鎖和非公平鎖對比圖,其中有一段代碼:
// 判斷當前線程是否和已佔用鎖的線程是同一個
else if (current == getExclusiveOwnerThread())
仔細看代碼, 你也許發現,我前面的一個說明是錯誤的,我要重新解釋一下
重入的線程會一直將 state + 1, 釋放鎖會 state – 1直至等於0,上面這樣寫也是想幫助大家快速的區分
總結
本文是一個長文,說明了為什麼要造 Lock 新輪子,如何標準的使用 Lock,AQS 是什麼,是如何實現鎖的,結合 ReentrantLock 反推 AQS 中的一些應用以及其獨有的一些特性
獨佔式獲取鎖就這樣介紹完了,我們還差 AQS 共享式 xxxShared 沒有分析,結合共享式,接下來我們來閱讀一下 Semaphore,ReentrantReadWriteLock 和 CountLatch 等
最後,也歡迎大家的留言,如有錯誤之處還請指出。我的手酸了,眼睛幹了,我去準備擼下一篇…..
靈魂追問
-
為什麼更改 state 有 setState() , compareAndSetState() 兩種方式,感覺後者更安全,但是鎖的視線中有好多地方都使用了 setState(),安全嗎?
-
下面代碼是一個轉賬程序,是否存在死鎖或者鎖的其他問題呢?
class Account {
private int balance;
private final Lock lock
= new ReentrantLock();
// 轉賬
void transfer(Account tar, int amt){
while (true) {
if(this.lock.tryLock()) {
try {
if (tar.lock.tryLock()) {
try {
this.balance -= amt;
tar.balance += amt;
} finally {
tar.lock.unlock();
}
}//if
} finally {
this.lock.unlock();
}
}//if
}//while
}//transfer
}
參考
- Java 併發實戰
- Java 併發編程的藝術
- https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※台中搬家公司教你幾個打包小技巧,輕鬆整理裝箱!
還在煩惱搬家費用要多少哪?台中大展搬家線上試算搬家費用,從此不再擔心「物品怎麼計費」、「多少車才能裝完」