1.前言
回顧:認證方案之初步認識JWT
在現代Web應用程序中,即分為前端與後端兩大部分。當前前後端的趨勢日益劇增,前端設備(手機、平板、電腦、及其他設備)層出不窮。因此,為了方便滿足前端設備與後端進行通訊,就必須有一種統一的機制。所以導致API架構的流行。而RESTful API這個API設計思想理論也就成為目前互聯網應用程序比較歡迎的一套方式。
這種API架構思想的引入,因此,我們就需要考慮用一種標準的,通用的,無狀態的,與語言無關的身份認證方式來實現API接口的認證。
HTTP提供了一套標準的身份驗證框架:服務端可以用來針對客戶端的請求發送質詢(challenge),客戶端根據質詢提供應答身份驗證憑證。
質詢與應答的工作流程如下:服務端向客戶端返回401(Unauthorized,未授權)狀態碼,並在WWW-Authenticate頭中添加如何進行驗證的信息,其中至少包含有一種質詢方式。然後客戶端可以在請求中添加Authorization頭進行驗證,其Value為身份驗證的憑證信息。
在本文中,將要介紹的是以Jwt Bearer方式進行認證。
2.Bearer認證
本文要介紹的Bearer驗證也屬於HTTP協議標準驗證,它隨着OAuth協議而開始流行,詳細定義見: RFC 6570。
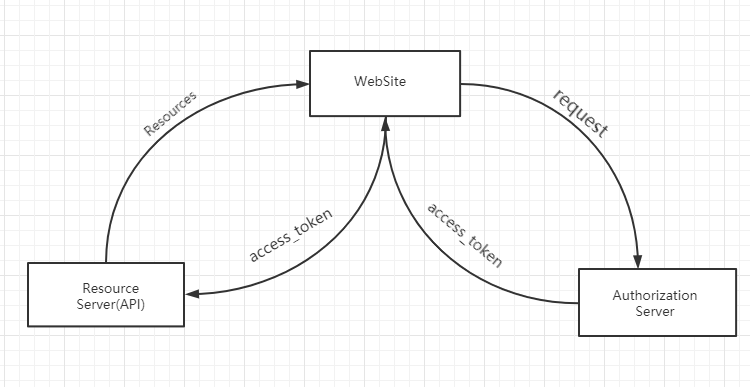
+--------+ +---------------+
| |--(A)- Authorization Request ->| Resource |
| | | Owner |
| |<-(B)-- Authorization Grant ---| |
| | +---------------+
| |
| | +---------------+
| |--(C)-- Authorization Grant -->| Authorization |
| Client | | Server |
| |<-(D)----- Access Token -------| |
| | +---------------+
| |
| | +---------------+
| |--(E)----- Access Token ------>| Resource |
| | | Server |
| |<-(F)--- Protected Resource ---| |
+--------+ +---------------+
A security token with the property that any party in possession of the token (a “bearer”) can use the token in any way that any other party in possession of it can. Using a bearer token does not require a bearer to prove possession of cryptographic key material (proof-of-possession).
因此Bearer認證的核心是Token,Bearer驗證中的憑證稱為BEARER_TOKEN,或者是access_token,它的頒發和驗證完全由我們自己的應用程序來控制,而不依賴於系統和Web服務器,Bearer驗證的標準請求方式如下:
Authorization: Bearer [BEARER_TOKEN]
那麼使用Bearer驗證有什麼好處呢?
- CORS: cookies + CORS 並不能跨不同的域名。而Bearer驗證在任何域名下都可以使用HTTP header頭部來傳輸用戶信息。
- 對移動端友好: 當你在一個原生平台(iOS, Android, WindowsPhone等)時,使用Cookie驗證並不是一個好主意,因為你得和Cookie容器打交道,而使用Bearer驗證則簡單的多。
- CSRF: 因為Bearer驗證不再依賴於cookies, 也就避免了跨站請求攻擊。
- 標準:在Cookie認證中,用戶未登錄時,返回一個
302到登錄頁面,這在非瀏覽器情況下很難處理,而Bearer驗證則返回的是標準的401 challenge。
3.JWT
上面介紹的Bearer認證,其核心便是BEARER_TOKEN,那麼,如何確保Token的安全是重中之重。一種是通過HTTPS的方式,另一種是通過對Token進行加密編碼簽名,而最流行的Token編碼簽名方式便是:JSON WEB TOKEN。
Json web token (Jwt), 是為了在網絡應用環境間傳遞聲明而執行的一種基於JSON的開放標準(RFC 7519)。該token被設計為緊湊且安全的,特別適用於分佈式站點的單點登錄(SSO)場景。JWT的聲明一般被用來在身份提供者和服務提供者間傳遞被認證的用戶身份信息,以便於從資源服務器獲取資源,也可以增加一些額外的其它業務邏輯所必須的聲明信息,該token也可直接被用於認證,也可被加密。
JWT是由.分割的如下三部分組成:
Header.Payload.Signature
還記得之前說個的一篇認證方案之初步認識JWT嗎?沒有的,可以看看,對JWT的特點和基本原理介紹,可以進一步的了解。
學習了之前的文章后,我們可以發現使用JWT的好處在於通用性、緊湊性和可拓展性。
- 通用性:因為json的通用性,所以JWT是可以進行跨語言支持的,像JAVA,JavaScript,NodeJS,PHP等很多語言都可以使用。
- 緊湊性:JWT的構成非常簡單,字節佔用很小,通過 GET、POST 等放在 HTTP 的 header 中,便於傳輸。
- 可擴展性:JWT是自我包涵的,因為有了payload部分,包含了必要的一些其他業務邏輯所必要的非敏感信息,自身存儲,不需要在服務端保存會話信息, 非常易於應用的擴展。
4.開始
1. 註冊認證服務
在這裏,我們用微軟給我們提供的JwtBearer認證方式,實現認證服務註冊 。
引入nuget包:Microsoft.AspNetCore.Authentication.JwtBearer
註冊服務,將服務添加到容器中,
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
var Issurer = "JWTBearer.Auth"; //發行人
var Audience = "api.auth"; //受眾人
var secretCredentials = "q2xiARx$4x3TKqBJ"; //密鑰
//配置認證服務
services.AddAuthentication(x =>
{
x.DefaultAuthenticateScheme = JwtBearerDefaults.AuthenticationScheme;
x.DefaultChallengeScheme = JwtBearerDefaults.AuthenticationScheme;
}).AddJwtBearer(o=>{
o.TokenValidationParameters = new TokenValidationParameters
{
//是否驗證發行人
ValidateIssuer = true,
ValidIssuer = Issurer,//發行人
//是否驗證受眾人
ValidateAudience = true,
ValidAudience = Audience,//受眾人
//是否驗證密鑰
ValidateIssuerSigningKey = true,
IssuerSigningKey = new SymmetricSecurityKey(Encoding.ASCII.GetBytes(secretCredentials)),
ValidateLifetime = true, //驗證生命周期
RequireExpirationTime = true, //過期時間
};
});
}
注意說明:
一. TokenValidationParameters的參數默認值:
1. ValidateAudience = true, ----- 如果設置為false,則不驗證Audience受眾人
2. ValidateIssuer = true , ----- 如果設置為false,則不驗證Issuer發布人,但建議不建議這樣設置
3. ValidateIssuerSigningKey = false,
4. ValidateLifetime = true, ----- 是否驗證Token有效期,使用當前時間與Token的Claims中的NotBefore和Expires對比
5. RequireExpirationTime = true, ----- 是否要求Token的Claims中必須包含Expires
6. ClockSkew = TimeSpan.FromSeconds(300), ----- 允許服務器時間偏移量300秒,即我們配置的過期時間加上這個允許偏移的時間值,才是真正過期的時間(過期時間 +偏移值)你也可以設置為0,ClockSkew = TimeSpan.Zero
調用方法,配置Http請求管道:
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseRouting();
//1.先開啟認證
app.UseAuthentication();
//2.再開啟授權
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
在JwtBearerOptions的配置中,通常IssuerSigningKey(簽名秘鑰), ValidIssuer(Token頒發機構), ValidAudience(頒發給誰) 三個參數是必須的,后兩者用於與TokenClaims中的Issuer和Audience進行對比,不一致則驗證失敗。
2.接口資源保護
創建一個需要授權保護的資源控制器,這裏我們用建立API生成項目自帶的控制器,WeatherForecastController.cs, 在控制器上使用Authorize即可
[ApiController]
[Route("[controller]")]
[Authorize]
public class WeatherForecastController : ControllerBase
{
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
private readonly ILogger<WeatherForecastController> _logger;
public WeatherForecastController(ILogger<WeatherForecastController> logger)
{
_logger = logger;
}
[HttpGet]
public IEnumerable<WeatherForecast> Get()
{
var rng = new Random();
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = rng.Next(-20, 55),
Summary = Summaries[rng.Next(Summaries.Length)]
})
.ToArray();
}
}
3. 生成Token
因為微軟為我們內置了JwtBearer驗證,但是沒有提供Token的發放,所以這裏我們要實現生成Token的方法
引入Nugets包:System.IdentityModel.Tokens.Jwt
這裏我們根據IdentityModel.Tokens.Jwt文檔給我們提供的幫助類,提供了方法WriteToken創建Token,根據參數SecurityToken,可以實例化,JwtSecurityToken,指定可選參數的類。
/// <summary>
/// Initializes a new instance of the <see cref="JwtSecurityToken"/> class specifying optional parameters.
/// </summary>
/// <param name="issuer">If this value is not null, a { iss, 'issuer' } claim will be added, overwriting any 'iss' claim in 'claims' if present.</param>
/// <param name="audience">If this value is not null, a { aud, 'audience' } claim will be added, appending to any 'aud' claims in 'claims' if present.</param>
/// <param name="claims">If this value is not null then for each <see cref="Claim"/> a { 'Claim.Type', 'Claim.Value' } is added. If duplicate claims are found then a { 'Claim.Type', List<object> } will be created to contain the duplicate values.</param>
/// <param name="expires">If expires.HasValue a { exp, 'value' } claim is added, overwriting any 'exp' claim in 'claims' if present.</param>
/// <param name="notBefore">If notbefore.HasValue a { nbf, 'value' } claim is added, overwriting any 'nbf' claim in 'claims' if present.</param>
/// <param name="signingCredentials">The <see cref="SigningCredentials"/> that will be used to sign the <see cref="JwtSecurityToken"/>. See <see cref="JwtHeader(SigningCredentials)"/> for details pertaining to the Header Parameter(s).</param>
/// <exception cref="ArgumentException">If 'expires' <= 'notbefore'.</exception>
public JwtSecurityToken(string issuer = null, string audience = null, IEnumerable<Claim> claims = null, DateTime? notBefore = null, DateTime? expires = null, SigningCredentials signingCredentials = null)
{
if (expires.HasValue && notBefore.HasValue)
{
if (notBefore >= expires)
throw LogHelper.LogExceptionMessage(new ArgumentException(LogHelper.FormatInvariant(LogMessages.IDX12401, expires.Value, notBefore.Value)));
}
Payload = new JwtPayload(issuer, audience, claims, notBefore, expires);
Header = new JwtHeader(signingCredentials);
RawSignature = string.Empty;
}
這樣,我們可以根據參數指定內容:
1. string iss = "JWTBearer.Auth"; // 定義發行人
2. string aud = "api.auth"; //定義受眾人audience
3. IEnumerable<Claim> claims = new Claim[]
{
new Claim(JwtClaimTypes.Id,"1"),
new Claim(JwtClaimTypes.Name,"i3yuan"),
};//定義許多種的聲明Claim,信息存儲部分,Claims的實體一般包含用戶和一些元數據
4. var nbf = DateTime.UtcNow; //notBefore 生效時間
5. var Exp = DateTime.UtcNow.AddSeconds(1000); //expires 過期時間
6. string sign = "q2xiARx$4x3TKqBJ"; //SecurityKey 的長度必須 大於等於 16個字符
var secret = Encoding.UTF8.GetBytes(sign);
var key = new SymmetricSecurityKey(secret);
var signcreds = new SigningCredentials(key, SecurityAlgorithms.HmacSha256);
好了,通過以上填充參數內容,進行傳參賦值得到,完整代碼如下:
新增AuthController.cs控制器:
[HttpGet]
public IActionResult GetToken()
{
try
{
//定義發行人issuer
string iss = "JWTBearer.Auth";
//定義受眾人audience
string aud = "api.auth";
//定義許多種的聲明Claim,信息存儲部分,Claims的實體一般包含用戶和一些元數據
IEnumerable<Claim> claims = new Claim[]
{
new Claim(JwtClaimTypes.Id,"1"),
new Claim(JwtClaimTypes.Name,"i3yuan"),
};
//notBefore 生效時間
// long nbf =new DateTimeOffset(DateTime.Now).ToUnixTimeSeconds();
var nbf = DateTime.UtcNow;
//expires //過期時間
// long Exp = new DateTimeOffset(DateTime.Now.AddSeconds(1000)).ToUnixTimeSeconds();
var Exp = DateTime.UtcNow.AddSeconds(1000);
//signingCredentials 簽名憑證
string sign = "q2xiARx$4x3TKqBJ"; //SecurityKey 的長度必須 大於等於 16個字符
var secret = Encoding.UTF8.GetBytes(sign);
var key = new SymmetricSecurityKey(secret);
var signcreds = new SigningCredentials(key, SecurityAlgorithms.HmacSha256);
var jwt = new JwtSecurityToken(issuer: iss, audience: aud, claims:claims,notBefore:nbf,expires:Exp, signingCredentials: signcreds);
var JwtHander = new JwtSecurityTokenHandler();
var token = JwtHander.WriteToken(jwt);
return Ok(new
{
access_token = token,
token_type = "Bearer",
});
}
catch (Exception ex)
{
throw;
}
}
注意: 1.SecurityKey 的長度必須 大於等於 16個字符,否則生成會報錯。(可通過在線隨機生成密鑰)
5. 運行
訪問獲取Token方法,獲取得到access_token:
再訪問,授權資源接口,可以發現,再沒有添加請求頭token值的情況下,返回了401沒有權限。
這次,在請求頭通過Authorization加上之前獲取的token值后,再次進行訪問,發現已經可以獲取訪問資源控制器,並返回對應的數據。
6.擴展說明
在HTTP標準驗證方案中,我們比較熟悉的是”Basic”和”Digest”,前者將用戶名密碼使用BASE64編碼後作為驗證憑證,後者是Basic的升級版,更加安全,因為Basic是明文傳輸密碼信息,而Digest是加密後傳輸。
一、Basic基礎認證
Basic認證是一種較為簡單的HTTP認證方式,客戶端通過明文(Base64編碼格式)傳輸用戶名和密碼到服務端進行認證,通常需要配合HTTPS來保證信息傳輸的安全。
客戶端請求需要帶Authorization請求頭,值為“Basic xxx”,xxx為“用戶名:密碼”進行Base64編碼後生成的值。 若客戶端是瀏覽器,則瀏覽器會提供一個輸入用戶名和密碼的對話框,用戶輸入用戶名和密碼后,瀏覽器會保存用戶名和密碼,用於構造Authorization值。當關閉瀏覽器后,用戶名和密碼將不再保存。
憑證為“YWxhzGRpbjpvcGVuc2VzYWl1”,是通過將“用戶名:密碼”格式的字符串經過的Base64編碼得到的。而Base64不屬於加密範疇,可以被逆向解碼,等同於明文,因此Basic傳輸認證信息是不安全的。
Basic基礎認證圖示:
缺陷匯總
1.用戶名和密碼明文(Base64)傳輸,需要配合HTTPS來保證信息傳輸的安全。
2.即使密碼被強加密,第三方仍可通過加密后的用戶名和密碼進行重放攻擊。
3.沒有提供任何針對代理和中間節點的防護措施。
4.假冒服務器很容易騙過認證,誘導用戶輸入用戶名和密碼。
二、Digest摘要認證
Digest認證是為了修復基本認證協議的嚴重缺陷而設計的,秉承“絕不通過明文在網絡發送密碼”的原則,通過“密碼摘要”進行認證,大大提高了安全性。
Digest認證步驟如下:
第一步:客戶端訪問Http資源服務器。由於需要Digest認證,服務器返回了兩個重要字段nonce(隨機數)和realm。
第二步:客戶端構造Authorization請求頭,值包含username、realm、nouce、uri和response的字段信息。其中,realm和nouce就是第一步返回的值。nouce只能被服務端使用一次。uri(digest-uri)即Request-URI的值,但考慮到經代理轉發后Request-URI的值可能被修改、因此實現會複製一份副本保存在uri內。response也可叫做Request-digest,存放經過MD5運算后的密碼字符串,形成響應碼。
第三步:服務器驗證包含Authorization值的請求,若驗證通過則可訪問資源。
Digest認證可以防止密碼泄露和請求重放,但沒辦法防假冒。所以安全級別較低。
Digest和Basic認證一樣,每次都會發送Authorization請求頭,也就相當於重新構造此值。所以兩者易用性都較差。
Digest認證圖示:
7.注意
- 在進行JwtBearer認證時,在生成token之後,還需要與刷新token配合使用,因為當用戶執行了退出,修改密碼等操作時,需要讓該token無效,無法再次使用,所以,會給access_token設置一個較短的有效期間,(JwtBearer認證默認會驗證有效期,通過
notBefore和expires來驗證),當access_token過期后,可以在用戶無感知的情況下,使用refresh_token重新獲取access_token,但這就不屬於Bearer認證的範疇了,但是我們可以通過另一種方式通過IdentityServer的方式來實現,在後續中會對IdentityServer進行詳細講解。 - 在生成token的時候,需要用的secret,主要是用來防止token被偽造與篡改。因為當token被劫取的時候,可以得到你的令牌中帶的一些個人不重要的信息明文,但不用擔心,只要你不在生成token里把私密的個人信息放出去的話,就算被動機不良的人得到,也做不了什麼事情。但是你可能會想,如果用戶自己隨便的生成一個 token ,帶上你的信息,那不就可以隨便訪問你的資源服務器了,因此這個時候就需要利用secret 來生成 token,來確保数字簽名的正確性。而且在認證授權資源,進行token解析的時候,通過微軟的源碼發現,已經幫我們封裝了方法,對secret進行了校驗了,確保了token的安全性,從而保證api資源的安全。
8.總結
- JwtToken在認證時,無需Security token service安全令牌服務器的參与,都是基於Claim的,默認會驗證有效期,通過
notBefore和expires來驗證,這在分佈式中提供給了極大便利。 - JwtToken與平台、無言無關,在前端也可以直接解析出Claims。
- 如果有不對的或不理解的地方,希望大家可以多多指正,提出問題,一起討論,不斷學習,共同進步。
- 後面會對認證授權方案中的授權這一塊進行說明分享。
- 本示例源碼地址
參考JwtBearer源碼
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※聚甘新