寫在前面
Spring容器中的組件默認是單例的,在Spring啟動時就會實例化並初始化這些對象,將其放到Spring容器中,之後,每次獲取對象時,直接從Spring容器中獲取,而不再創建對象。如果每次從Spring容器中獲取對象時,都要創建一個新的實例對象,該如何處理呢?此時就需要使用@Scope註解設置組件的作用域。
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
本文內容概覽
- @Scope註解概述
- 單實例bean作用域
- 多實例bean作用域
- 單實例bean作用域如何創建對象?
- 多實例bean作用域如何創建對象?
- 單實例bean注意的事項
- 多實例bean注意的事項
- 自定義Scope的實現
@Scope註解概述
@Scope註解能夠設置組件的作用域,我們先來看@Scope註解類的源碼,如下所示。
package org.springframework.context.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.core.annotation.AliasFor;
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Scope {
@AliasFor("scopeName")
String value() default "";
/**
* Specifies the name of the scope to use for the annotated component/bean.
* <p>Defaults to an empty string ({@code ""}) which implies
* {@link ConfigurableBeanFactory#SCOPE_SINGLETON SCOPE_SINGLETON}.
* @since 4.2
* @see ConfigurableBeanFactory#SCOPE_PROTOTYPE
* @see ConfigurableBeanFactory#SCOPE_SINGLETON
* @see org.springframework.web.context.WebApplicationContext#SCOPE_REQUEST
* @see org.springframework.web.context.WebApplicationContext#SCOPE_SESSION
* @see #value
*/
@AliasFor("value")
String scopeName() default "";
ScopedProxyMode proxyMode() default ScopedProxyMode.DEFAULT;
}
從源碼中可以看出,在@Scope註解中可以設置如下值。
ConfigurableBeanFactory#SCOPE_PROTOTYPE
ConfigurableBeanFactory#SCOPE_SINGLETON
org.springframework.web.context.WebApplicationContext#SCOPE_REQUEST
org.springframework.web.context.WebApplicationContext#SCOPE_SESSION
很明顯,在@Scope註解中可以設置的值包括ConfigurableBeanFactory接口中的SCOPE_PROTOTYPE和SCOPE_SINGLETON,以及WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION。這些都是什麼鬼?別急,我們來一個個查看。
首先,我們進入到ConfigurableBeanFactory接口中,發現在ConfigurableBeanFactory類中存在兩個常量的定義,如下所示。
public interface ConfigurableBeanFactory extends HierarchicalBeanFactory, SingletonBeanRegistry {
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
/*****************此處省略N多行代碼*******************/
}
沒錯,SCOPE_SINGLETON就是singleton,SCOPE_PROTOTYPE就是prototype。
那麼,WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION又是什麼鬼呢?就是說,當我們使用了Web容器來運行Spring應用時,在@Scope註解中可以設置WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION的值,而SCOPE_REQUEST的值就是request,SCOPE_SESSION的值就是session。
綜上,在@Scope註解中的取值如下所示。
- singleton:表示組件在Spring容器中是單實例的,這個是Spring的默認值,Spring在啟動的時候會將組件進行實例化並加載到Spring容器中,之後,每次從Spring容器中獲取組件時,直接將實例對象返回,而不必再次創建實例對象。從Spring容器中獲取對象,小夥伴們可以理解為從Map對象中獲取對象。
- prototype:表示組件在Spring容器中是多實例的,Spring在啟動的時候並不會對組件進行實例化操作,而是每次從Spring容器中獲取組件對象時,都會創建一個新的實例對象並返回。
- request:每次請求都會創建一個新的實例對象,request作用域用在spring容器的web環境中。
- session:在同一個session範圍內,創建一個新的實例對象,也是用在web環境中。
- application:全局web應用級別的作用於,也是在web環境中使用的,一個web應用程序對應一個bean實例,通常情況下和singleton效果類似的,不過也有不一樣的地方,singleton是每個spring容器中只有一個bean實例,一般我們的程序只有一個spring容器,但是,一個應用程序中可以創建多個spring容器,不同的容器中可以存在同名的bean,但是sope=aplication的時候,不管應用中有多少個spring容器,這個應用中同名的bean只有一個。
其中,request和session作用域是需要Web環境支持的,這兩個值基本上使用不到,如果我們使用Web容器來運行Spring應用時,如果需要將組件的實例對象的作用域設置為request和session,我們通常會使用request.setAttribute(“key”,object)和session.setAttribute(“key”, object)的形式來將對象實例設置到request和session中,通常不會使用@Scope註解來進行設置。
單實例bean作用域
首先,我們在io.mykit.spring.plugins.register.config包下創建PersonConfig2配置類,在PersonConfig2配置類中實例化一個Person對象,並將其放置在Spring容器中,如下所示。
package io.mykit.spring.plugins.register.config;
import io.mykit.spring.bean.Person;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author binghe
* @version 1.0.0
* @description 測試@Scope註解設置的作用域
*/
@Configuration
public class PersonConfig2 {
@Bean("person")
public Person person(){
return new Person("binghe002", 18);
}
}
接下來,在SpringBeanTest類中創建testAnnotationConfig2()測試方法,在testAnnotationConfig2()方法中,創建ApplicationContext對象,創建完畢后,從Spring容器中按照id獲取兩個Person對象,並打印兩個對象是否是同一個對象,代碼如下所示。
@Test
public void testAnnotationConfig2(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
//從Spring容器中獲取到的對象默認是單實例的
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
System.out.println(person1 == person2);
}
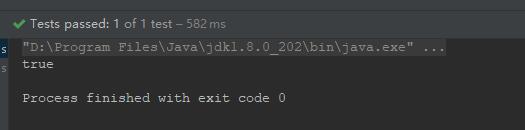
由於對象在Spring容器中默認是單實例的,所以,Spring容器在啟動時就會將實例對象加載到Spring容器中,之後,每次從Spring容器中獲取實例對象,直接將對象返回,而不必在創建新對象實例,所以,此時testAnnotationConfig2()方法會輸出true。如下所示。
這也驗證了我們的結論:對象在Spring容器中默認是單實例的,Spring容器在啟動時就會將實例對象加載到Spring容器中,之後,每次從Spring容器中獲取實例對象,直接將對象返回,而不必在創建新對象實例。
多實例bean作用域
修改Spring容器中組件的作用域,我們需要藉助於@Scope註解,此時,我們將PersonConfig2類中Person對象的作用域修改成prototype,如下所示。
@Configuration
public class PersonConfig2 {
@Scope("prototype")
@Bean("person")
public Person person(){
return new Person("binghe002", 18);
}
}
其實,使用@Scope設置作用域就等同於在XML文件中為bean設置scope作用域,如下所示。
此時,我們再次運行SpringBeanTest類的testAnnotationConfig2()方法,此時,從Spring容器中獲取到的person1對象和person2對象還是同一個對象嗎?
通過輸出結果可以看出,此時,輸出的person1對象和person2對象已經不是同一個對象了。
單實例bean作用域何時創建對象?
接下來,我們驗證下在單實例作用域下,Spring是在什麼時候創建對象的呢?
首先,我們將PersonConfig2類中的Person對象的作用域修改成單實例,並在返回Person對象之前打印相關的信息,如下所示。
@Configuration
public class PersonConfig2 {
@Scope
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
接下來,我們在SpringBeanTest類中創建testAnnotationConfig3()方法,在testAnnotationConfig3()方法中,我們只創建Spring容器,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
}
此時,我們運行SpringBeanTest類中的testAnnotationConfig3()方法,輸出的結果信息如下所示。
從輸出的結果信息可以看出,Spring容器在創建的時候,就將@Scope註解標註為singleton的組件進行了實例化,並加載到Spring容器中。
接下來,我們運行SpringBeanTest類中的testAnnotationConfig2(),結果信息如下所示。
說明,Spring容器在啟動時,將單實例組件實例化之後,加載到Spring容器中,以後每次從容器中獲取組件實例對象,直接返回相應的對象,而不必在創建新對象。
多實例bean作用域何時創建對象?
如果我們將對象的作用域修改成多實例,那什麼時候創建對象呢?
此時,我們將PersonConfig2類的Person對象的作用域修改成多實例,如下所示。
@Configuration
public class PersonConfig2 {
@Scope("prototype")
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,輸出的結果信息如下所示。
可以看到,終端並沒有輸出任何信息,說明在創建Spring容器時,並不會實例化和加載多實例對象,那多實例對象是什麼時候實例化的呢?接下來,我們在SpringBeanTest類中的testAnnotationConfig3()方法中添加一行獲取Person對象的代碼,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
從結果信息中,可以看出,當向Spring容器中獲取Person實例對象時,Spring容器實例化了Person對象,並將其加載到Spring容器中。
那麼,問題來了,此時Spring容器是否只實例化一個Person對象呢?我們在SpringBeanTest類中的testAnnotationConfig3()方法中再添加一行獲取Person對象的代碼,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
從輸出結果可以看出,當對象的Scope作用域為多實例時,每次向Spring容器獲取對象時,都會創建一個新的對象並返回。此時,獲取到的person1和person2就不是同一個對象了,我們也可以打印結果信息來進行驗證,此時在SpringBeanTest類中的testAnnotationConfig3()方法中打印兩個對象是否相等,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
System.out.println(person1 == person2);
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
可以看到,當對象是多實例時,每次從Spring容器中獲取對象時,都會創建新的實例對象,並且每個實例對象都不相等。
單實例bean注意的事項
單例bean是整個應用共享的,所以需要考慮到線程安全問題,之前在玩springmvc的時候,springmvc中controller默認是單例的,有些開發者在controller中創建了一些變量,那麼這些變量實際上就變成共享的了,controller可能會被很多線程同時訪問,這些線程併發去修改controller中的共享變量,可能會出現數據錯亂的問題;所以使用的時候需要特別注意。
多實例bean注意的事項
多例bean每次獲取的時候都會重新創建,如果這個bean比較複雜,創建時間比較長,會影響系統的性能,這個地方需要注意。
自定義Scope
如果Spring內置的幾種sope都無法滿足我們的需求的時候,我們可以自定義bean的作用域。
1.如何實現自定義Scope
自定義Scope主要分為三個步驟,如下所示。
(1)實現Scope接口
我們先來看下Scope接口的定義,如下所示。
package org.springframework.beans.factory.config;
import org.springframework.beans.factory.ObjectFactory;
import org.springframework.lang.Nullable;
public interface Scope {
/**
* 返回當前作用域中name對應的bean對象
* name:需要檢索的bean的名稱
* objectFactory:如果name對應的bean在當前作用域中沒有找到,那麼可以調用這個ObjectFactory來創建這個對象
**/
Object get(String name, ObjectFactory<?> objectFactory);
/**
* 將name對應的bean從當前作用域中移除
**/
@Nullable
Object remove(String name);
/**
* 用於註冊銷毀回調,如果想要銷毀相應的對象,則由Spring容器註冊相應的銷毀回調,而由自定義作用域選擇是不是要銷毀相應的對象
*/
void registerDestructionCallback(String name, Runnable callback);
/**
* 用於解析相應的上下文數據,比如request作用域將返回request中的屬性。
*/
@Nullable
Object resolveContextualObject(String key);
/**
* 作用域的會話標識,比如session作用域將是sessionId
*/
@Nullable
String getConversationId();
}
(2)將Scope註冊到容器
需要調用org.springframework.beans.factory.config.ConfigurableBeanFactory#registerScope的方法,看一下這個方法的聲明
/**
* 向容器中註冊自定義的Scope
*scopeName:作用域名稱
* scope:作用域對象
**/
void registerScope(String scopeName, Scope scope);
(3)使用自定義的作用域
定義bean的時候,指定bean的scope屬性為自定義的作用域名稱。
2.自定義Scope實現案例
例如,我們來實現一個線程級別的bean作用域,同一個線程中同名的bean是同一個實例,不同的線程中的bean是不同的實例。
這裏,要求bean在線程中是共享的,所以我們可以通過ThreadLocal來實現,ThreadLocal可以實現線程中數據的共享。
此時,我們在io.mykit.spring.plugins.register.scope包下新建ThreadScope類,如下所示。
package io.mykit.spring.plugins.register.scope;
import org.springframework.beans.factory.ObjectFactory;
import org.springframework.beans.factory.config.Scope;
import org.springframework.lang.Nullable;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* 自定義本地線程級別的bean作用域,不同的線程中對應的bean實例是不同的,同一個線程中同名的bean是同一個實例
*/
public class ThreadScope implements Scope {
public static final String THREAD_SCOPE = "thread";
private ThreadLocal<Map<String, Object>> beanMap = new ThreadLocal() {
@Override
protected Object initialValue() {
return new HashMap<>();
}
};
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
Object bean = beanMap.get().get(name);
if (Objects.isNull(bean)) {
bean = objectFactory.getObject();
beanMap.get().put(name, bean);
}
return bean;
}
@Nullable
@Override
public Object remove(String name) {
return this.beanMap.get().remove(name);
}
@Override
public void registerDestructionCallback(String name, Runnable callback) {
//bean作用域範圍結束的時候調用的方法,用於bean清理
System.out.println(name);
}
@Nullable
@Override
public Object resolveContextualObject(String key) {
return null;
}
@Nullable
@Override
public String getConversationId() {
return Thread.currentThread().getName();
}
}
在ThreadScope類中,我們定義了一個常量THREAD_SCOPE,在定義bean的時候給scope使用。
接下來,我們在io.mykit.spring.plugins.register.config包下創建PersonConfig3類,並使用@Scope(“thread”)註解標註Person對象的作用域為Thread範圍,如下所示。
package io.mykit.spring.plugins.register.config;
import io.mykit.spring.bean.Person;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
/**
* @author binghe
* @version 1.0.0
* @description 測試@Scope註解設置的作用域
*/
@Configuration
public class PersonConfig3 {
@Scope("thread")
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
最後,我們在SpringBeanTest類中創建testAnnotationConfig4()方法,在testAnnotationConfig4()方法中創建Spring容器,並向Spring容器中註冊ThreadScope對象,接下來,使用循環創建兩個Thread線程,並分別在每個線程中獲取兩個Person對象,如下所示。
@Test
public void testAnnotationConfig4(){
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig3.class);
//向容器中註冊自定義的scope
context.getBeanFactory().registerScope(ThreadScope.THREAD_SCOPE, new ThreadScope());
//使用容器獲取bean
for (int i = 0; i < 2; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread() + "," + context.getBean("person"));
System.out.println(Thread.currentThread() + "," + context.getBean("person"));
}).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
此時,我們運行SpringBeanTest類的testAnnotationConfig4()方法,輸出的結果信息如下所示。
從輸出中可以看到,bean在同樣的線程中獲取到的是同一個bean的實例,不同的線程中bean的實例是不同的。
注意:這裏,我將Person類進行了相應的調整,去掉Lombok的註解,手動寫構造函數和setter與getter方法,如下所示。
package io.mykit.spring.bean;
import java.io.Serializable;
/**
* @author binghe
* @version 1.0.0
* @description 測試實體類
*/
public class Person implements Serializable {
private static final long serialVersionUID = 7387479910468805194L;
private String name;
private Integer age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
好了,咱們今天就聊到這兒吧!別忘了給個在看和轉發,讓更多的人看到,一起學習一起進步!!
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
寫在最後
如果覺得文章對你有點幫助,請微信搜索並關注「 冰河技術 」微信公眾號,跟冰河學習Spring註解驅動開發。公眾號回復“spring註解”關鍵字,領取Spring註解驅動開發核心知識圖,讓Spring註解驅動開發不再迷茫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準