一 CLI訪問OpenShift資源
1.1 資源操作
OCP將OpenShift集群中的為由主節點管理的對象統稱為資源,如:node、service、pod、project、deployment、user。
即使針對的是不同的資源,OpenShift命令行工具也提供了一種統一的、一致的方法來更新、修改、刪除和查詢這些資源。
oc命令行工具提供了在軟件開發項目的整個交付生命周期中修改和管理資源的常見操作。
1.2 安裝oc工具
在OpenShift安裝過程中,oc命令行工具安裝在所有master和node節點上,還可以在不屬於OpenShift集群的機器。
安裝后,可以使用用戶名和密碼對任何主節點通過身份驗證后執行相關命令。
根據使用的平台,安裝oc命令行工具有以下幾種方式:
yum安裝:在RHEL平台上,可通過以下命令安裝oc客戶端命令。
[user@host ~]$ sudo yum install atomic-openshift-clients
其它 Linux 發行版本和操作系統,需在擁有 OpenShift 訂閱后,在 Red Hat Customer Portal 中下載。
提示:oc安裝完成后自動補全需要退出一次才可生效,或者source /etc/bash_completion.d/oc。
1.3 oc主要查詢命令
[student@workstation ~]$ oc –help #显示幫助信息
[student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com #登錄到OpenShift集群
提示:從client成功通過身份驗證之後,OpenShift將授權令牌保存在用戶的主文件夾中。此令牌用於後續請求,從而無需重新輸入憑據或完整的主URL。
1 [root@master ~]# oc whoami
2 system:admin #master的root用戶為集群的最高權限的用戶
3 [student@workstation ~]$ oc whoami #查看當前用戶
4 developer
5 [student@workstation ~]$ oc new-project working #創建project
6 [student@workstation ~]$ oc status #查看項目狀態
7 In project working on server https://master.lab.example.com:443
8 You have no services, deployment configs, or build configs.
9 Run 'oc new-app' to create an application.
10 [student@workstation ~]$ oc delete project working #刪除project
11 [student@workstation ~]$ oc logout #退出該集群。
12 [student@workstation ~]$ oc get pods #查看pod
13 NAME READY STATUS RESTARTS AGE
14 hello-openshift-1-6ls8z 1/1 Running 0 4h
15 [student@workstation ~]$ oc get all #查看所有主要組件信息
16 [student@workstation ~]$ oc get pods -w #-w表示以監視模式運行
1.4 oc 其他命令
oc describe:如果oc get提供的摘要不夠,可以使用oc describe命令檢索關於資源的更詳細信息。
[student@workstation ~]$ oc describe pod hello-openshift-1-6ls8z
oc export:使用oc export命令導出資源的定義。典型的用例包括創建備份,或者用於修改定義。默認情況下,export命令以YAML格式輸出對象表示,但是可以通過提供-o選項來更改。
oc create:使用oc create命令從資源定義創建資源。通常,這與用於編輯定義的oc export命令相匹配。
oc delete RESOURCE_TYPE name:使用oc delete命令從OpenShift集群中刪除資源。
注意:部分資源直接刪除後會重新創建,如基於rc的pod,需要對OpenShift體系資源展示形式有一個基本的了解。
oc exec:使用oc exec命令在容器中執行命令,可以使用此命令作為腳本的一部分運行交互式和非交互式批處理命令。
oc rsh POD:oc rsh pod命令打開到容器的遠程shell會話,要遠程登錄到容器shell並執行命令,請運行以下命令。
[student@workstation ~]$ oc rsh <pod>
注意:oc rsh需要pod中存在相應的shell,如bash。
二 OpenShift資源類型
2.1 常見資源
OpenShift容器平台中的應用程序由不同類型的資源組成,主要常見的類型有:
- Container:如何在可移植Linux環境中運行一個或多個進程的定義。容器從一個映像啟動,並且通常與同一機器上的其他容器隔離。
- Image:一個分層的Linux文件系統,包含應用程序代碼、依賴關係和函數庫等。image由一個名稱標識,該名稱可以是當前集群的本地名稱,也可以指向遠程Docker倉庫。
- Pod:部署在節點上並共享唯一IP地址和卷(持久存儲)的一個或多個容器,Pods還為每個容器定義安全性和運行時策略。
- Label:標籤是鍵值對,可以分配給系統中的任何資源進行分組和選擇。通常資源使用標籤來標識其他資源集。
- Volume:默認情況下容器不是持久性的,即容器的內容在重新啟動時被清除。volume是掛載在pod及其容器上的文件系統,它們可能由許多本地或網絡的存儲提供。最簡單的卷類型是EmptyDir,它是一台機器上的臨時目錄。
- Node:node是集群中用來運行容器的節點,node通常由管理員管理,而不是由最終用戶管理。
- Service:service是表示一組pod的邏輯名稱,service被分配一個IP地址和一個DNS名稱,可以通過端口或route向集群外部公開。名為SERVICE_HOST的環境變量會自動注入到其他pod中。
- Route:route是一個DNS條目,創建它是為了指向一個service,以便可以從集群外部訪問它。可以配置一個或多個路由器來處理這些route,通常通過HAProxy負載均衡器。
- Replication Controller:Replication Controller基於匹配一組label的Templates維護特定數量的pod。如果刪除了pod,控制器將創建該pod的新副本。Replication Controller最常用來表示基於image的應用程序部分的單個部署。
- Deployment Configuration:deployment configuration定義pod的模板,並在屬性更改時管理部署新映像或配置更改。單個deployment configuration通常類似於單個微服務。deployment configuration可以支持許多不同的部署模式,包括完全重啟、可定製的滾動更新以及生命周期前後的順序。每個deployment都表示為一個replication controller。
- Build Configuration:build configuration包含如何將源代碼和基本image構建為新image的描述。Build可以是基於源代碼的,可以為常見語言(如Java、PHP、Ruby或Python)或基於docker的(從Dockerfile創建構建)使用構建器映像。每個build configuration都有webhook,可以通過對其基本映像的更改自動觸發。
- Build:構建從源代碼、其他圖像、Dockerfiles或二進制輸入創建新image。Build在容器中運行,具有與普通pod相同的限制。Build通常會導致將image推入Docker倉庫中,但也可以選擇運行post-build測試而不push到image倉庫。
- Image Streams and Image Stream Tags:IS使用標記名稱對相關is進行分組。它類似於源代碼倉庫中的分支。每個is可以有一個或多個標記(默認標記稱為“latest”),這些標記可能指向外部Docker倉庫、同一is中的其他標記,或者被控製為直接指向已知image。此外,可以通過集成的Docker倉庫直接將image push到docker倉庫。
- Secret:secret資源可以保存文本或二進制secrets,以便注入至pod。默認情況下,在/var/run/secrets/kubernetes.io/serviceaccount上,每個容器都有一個secret,其中包含訪問API有限特權的令牌。可以創建新的secret並將它們掛載到自己的pod中,也可以引用構建中的secret(用於連接遠程服務器),或者使用它們將遠程image導入到is中。
- Project:所有上述資源(node除外)都存在於項目中。項目具有成員列表及其role(如view、edit或admin),以及運行的pod上的一組安全控制,並限制項目可以使用多少資源,資源名稱在項目中是惟一的。
使用oc types命令快速查看可用的概念和類型。
2.2 創建應用
簡單的應用程序、複雜的多層應用程序和微服務應用程序都可以使用資源定義文件來描述。
這個文件包含許多pod定義、連接這些pod的服務定義、用於水平伸縮應用程序pod的rc或dc、用於持久存儲應用程序數據的持久卷,以及OpenShift可以管理的任何其他需要的內容。
oc new-app命令可以使用-o json或-o yaml選項分別創建以json或yaml格式的定義文件的資源。可以使用oc create -f <filename>命令調用定義文件,並將其用於創建應用程序,或者與其他資源定義文件合併以創建複合應用程序。
oc new-app命令可以以許多不同的方式創建在OpenShift上運行的pod應用程序。它可以使用source-to-image (S2I)流程從現有docker映像、Dockerfiles或原始源代碼創建pod。
運行oc new-app -h命令,了解在OpenShift上創建新應用程序的所有不同選項。最常見的選項如下:
運行以下命令創建應用程序。OpenShift根據Docker配置文件的ADD_REGISTRY選項定義的倉庫 pull image。
$ oc new-app mysql MYSQL_USER=user MYSQL_PASSWORD=pass MYSQL_DATABASE=testdb -l
db=mysql
根據私有倉庫中的image創建應用程序。
$ oc new-app –docker-image=myregistry.com/mycompany/myapp –name=myapp
根據存儲在Git庫中的源代碼創建應用程序。
$ oc new-app https://github.com/openshift/ruby-hello-world –name=ruby-hello
創建基於存儲在Git庫中的源代碼並引用IS的應用程序。
$ oc new-app https://mygitrepo/php-hello -i php:7.0 –name=php-hello
從Docker配置文件的ADD_REGISTRY指令定義的可用倉庫之一創建一個基於mysql映像的應用程序。l db=mysql選項定義了一個值為mysql的db標籤。
$ oc new-app mysql MYSQL_USER=user \
MYSQL_PASSWORD=pass \
MYSQL_DATABASE=testdb \
-l db=mysql
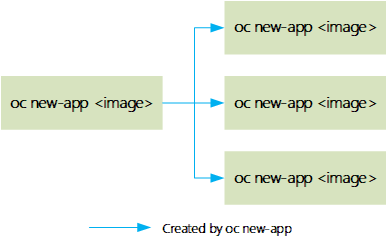
下圖显示了oc new-app命令在參數為容器image時創建的Kubernetes和OpenShift資源。該命令創建dc、is和svc,可以通過端口或route從外部訪問。
提示:通過使用帶有源代碼的oc new-app,將創建一個build configuration,而bc又從源代碼創建一個新的應用程序。但是,如果命令中沒有使用源代碼,則不會創建gc。該命令始終為應用程序創建dc和svc。
三 oc使用練習
3.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
3.2 本練習準備
[student@workstation ~]$ lab manage-oc setup
3.3 驗證OpenShift
1 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com
2 [student@workstation ~]$ oc project default
3 Already on project "default" on server "https://master.lab.example.com:443".
4 [student@workstation ~]$ oc project default
5 Already on project "default" on server "https://master.lab.example.com:443".
6 [student@workstation ~]$ oc get nodes
7 NAME STATUS ROLES AGE VERSION
8 master.lab.example.com Ready master 23h v1.9.1+a0ce1bc657
9 node1.lab.example.com Ready compute 23h v1.9.1+a0ce1bc657
10 node2.lab.example.com Ready compute 23h v1.9.1+a0ce1bc657
11 [student@workstation ~]$ oc describe node master.lab.example.com #查看master節點詳情
12 [student@workstation ~]$ oc describe node node1.lab.example.com
13 [student@workstation ~]$ oc describe node node2.lab.example.com
14 [student@workstation ~]$ oc get pods -o wide
15 NAME READY STATUS RESTARTS AGE IP NODE
16 docker-registry-1-8v7sh 1/1 Running 4 23h 10.129.0.30 node2.lab.example.com
17 docker-registry-1-rrmhm 1/1 Running 2 23h 10.128.0.12 node1.lab.example.com
18 registry-console-1-xzxxp 1/1 Running 4 23h 10.129.0.31 node2.lab.example.com
19 router-1-fwttd 1/1 Running 4 23h 172.25.250.12 node2.lab.example.com
20 router-1-xdw84 1/1 Running 2 23h 172.25.250.11 node1.lab.example.com
21 [student@workstation ~]$ oc describe pod docker-registry-1-8v7sh #查看pod詳情
3.4 pod操作
[student@workstation ~]$ oc exec docker-registry-1-8v7sh hostname #執行pod中命令
docker-registry-1-8v7sh
[student@workstation ~]$ oc exec router-1-fwttd ls /
[student@workstation ~]$ oc exec docker-registry-1-8v7sh cat /etc/resolv.conf
提示:只要pod中存在的命令,都可以通過oc exec直接執行。
[student@workstation ~]$ oc rsh docker-registry-1-8v7sh #進入pod的shell
sh-4.2$ ls /
3.5 oc其他操作
[student@workstation ~]$ oc status -v #現實詳細的狀態
[student@workstation ~]$ oc get events #查看集群生命周期事件
[student@workstation ~]$ oc get all #獲取所有資源信息
3.6 導出資源
[student@workstation ~]$ oc export pod docker-registry-1-8v7sh
提示:oc export命令通常用於導出現有資源,並將它們轉換為配置文件(YAML或JSON),以便備份或在集群的其他地方重新創建資源。
[student@workstation ~]$ oc export svc,dc docker-registry –as-template=docker-registry
#通過將–as-template選項傳遞給oc export命令,將多個資源作為OpenShift模板同時導出。
[student@workstation ~]$ oc export svc,dc docker-registry > docker-registry.yaml #也可以使用重定嚮導出
[student@workstation ~]$ oc export –help #查看幫助
四 oc常見故障排除
4.1 常見環境信息
使用RPM安裝的OCP,那麼master和node的ocp相關服務將作為Red Hat Enterprise Linux服務運行。從master和node使用標準的sosreport實用程序,收集關於環境的信息,以及docker和openshift相關的信息。
[root@master ~]# sosreport -k docker.all=on -k docker.logs=on
sosreport命令創建一個包含所有相關信息的壓縮歸檔文件,並將其保存在/var/tmp目錄中。
另一個有用的診斷工具是oc adm diagnostics命令,能夠在OpenShift集群上運行多個診斷檢查,包括network、日誌、內部倉庫、master節點和node節點的服務檢查等等。oc adm diagnostics –help命令,獲取幫助。
4.2 常見診斷命令
oc客戶端命令是用來檢測和排除OpenShift集群中的問題的主要工具。它有許多選項,能夠檢測、診斷和修復由集群管理的主機和節點、服務和資源的問題。若已授權所需的權限,可以直接編輯集群中大多數託管資源的配置。
事件允許OpenShift記錄集群中生命周期事件的信息,以統一的方式查看關於OpenShift組件的信息。oc get events命令提供OpenShift namespace的事件信息,可實現以下事件的捕獲:
- Pod創建和刪除
- pod調度的節點
- master和node節點的狀態
事件通常用於故障排除,從而獲得關於集群中的故障和問題的高級信息,然後使用日誌文件和其他oc子命令進一步定位。
示例:使用以下命令獲得特定項目中的事件列表。
[student@workstation ~]$ oc get events -n <project>
也可以通過Web控制台進行事件的查看events。
oc logs命令查看build、deployment或pod的日誌輸出,。
示例1:使用oc命令查看pod的日誌。
[student@workstation ~]$ oc logs pod
示例2:使用oc命令查看build的日誌。
[student@workstation ~]$ oc logs bc/build-name
使用oc logs命令和-f選項實時跟蹤日誌輸出。例如,這對於連續監視build的進度和檢查錯誤非常有用。
也可以通過Web控制台進行事件的查看log。
oc rsync命令將內容複製到正在運行的pod中的目錄或從目錄複製內容。如果一個pod有多個容器,可以使用-c選項指定容器ID。否則,它默認為pod中的第一個容器。通常用於從容器傳輸日誌文件和配置文件。
示例1:將pod目錄中的內容複製到本地目錄。
[student@workstation ~]$ oc rsync <pod>:<pod_dir> <local_dir> -c <container>
示例2:將內容從本地目錄複製到pod的目錄中。
[student@workstation ~]$ oc rsync <local_dir> <pod>:<pod_dir> -c <container>
使用oc port-forward命令將一個或多個本地端口轉發到pod。這允許在本地監聽特定或隨機端口,並將數據轉發到pod中的特定端口。
示例1:本地監聽3306並轉發到pod的3306.
[student@workstation ~]$ oc port-forward <pod> 3306:3306
五 TS常見故障
5.1 資源限制和配額問題
對於設置了資源限制和配額的項目,不適當的資源配置將導致部署失敗。使用oc get events和oc describe命令來排查失敗的原因。
例如試圖創建超過項目中pod數量配額限制的pod數量,那麼在運行oc get events命令時會提示:
Warning FailedCreate {hello-1-deploy} Error creating: pods “hello-1” is forbidden:
exceeded quota: project-quota, requested: cpu=250m, used: cpu=750m, limited: cpu=900m
5.2 S2I build失敗
使用oc logs命令查看S2I構建失敗。例如,要查看名為hello的構建配置的日誌:
[student@workstation ~]$ oc logs bc/hello
例如可以通過在build configuration策略中指定BUILD_LOGLEVEL環境變量來調整build日誌的詳細程度。
1 {
2 "sourceStrategy": {
3 ...
4 "env": [
5 {
6 "name": "BUILD_LOGLEVEL",
7 "value": "5"
8 }
9 ]
10 }
11 }
5.3 ErrImagePull和imgpullback錯誤
通常是由不正確的deployment configuration造成、部署期間引用的錯誤或缺少image或Docker配置不當造成。
使用oc get events和oc describe命令排查,通過使用oc edit dc/<deploymentconfig>編輯deployment configuration來修復錯誤。
5.4 docker配置異常
master和node上不正確的docker配置可能會在部署期間導致許多錯誤。
通常檢查ADD_REGISTRY、INSECURE_REGISTRY和BLOCK_REGISTRY設置。使用systemctl status, oc logs, oc get events和oc describe命令對問題進行排查。
可以通添加/etc/sysconfig/docker配置文件中的–log-level參數來更改docker服務日誌級別。
示例:將日誌級別設置為debug。
OPTIONS=’–insecure-registry=172.30.0.0/16 –selinux-enabled –log-level=debug’
5.5 master和node節點失敗
運行systemctl status命令,對atomicopenshift-master、atom-openshift-node、etcd和docker服務中的問題進行排查。使用journalctl -u <unit-name>命令查看與前面列出的服務相關的系統日誌。
可以通過在各自的配置文件中編輯–loglevel變量,然後重新啟動關聯的服務,來增加來自atom-openshift-node、atomicopenshift-master-controllers和atom-openshift-master-api服務的詳細日誌記錄。
示例:設置OpenShift主控制器log level為debug級別,修改/etc/sysconfig/atomic-openshift-master-controllers文件。
OPTIONS=–loglevel=4 –listen=https://0.0.0.0:8444
延伸:
Red Hat OpenShift容器平台有五個級別的日誌詳細程度,無論日誌配置如何,日誌中都會出現帶有致命、錯誤、警告和某些信息嚴重程度的消息。
- 0:只有錯誤和警告
- 2:正常信息(默認)
- 4:debug級信息
- 6:api級debug信息(請求/響應)
- 8:帶有完整請求體的API debug信息
5.6 調度pod失敗
OpenShift master調度pod在node上運行,通常由於node本身沒有處於就緒狀態,也由於資源限制和配額,pod無法運行。
使用oc get nodes命令驗證節點的狀態。在調度失敗期間,pod將處於掛起狀態,可以使用oc get pods -o wide命令進行檢查,該命令還显示了計劃在哪個節點上運行pod。使用oc get events和oc describe pod命令檢查調度失敗的詳細信息。
示例1:如下所示pod調度失敗,原因是CPU不足。
{default-scheduler } Warning FailedScheduling pod (FIXEDhello-phb4j) failed to
fit in any node
fit failure on node (hello-wx0s): Insufficient cpu
fit failure on node (hello-tgfm): Insufficient cpu
fit failure on node (hello-qwds): Insufficient cpu
示例2:如下所示pod調度失敗,原因是節點沒有處於就緒狀態,可通過oc describe排查。
{default-scheduler } Warning FailedScheduling pod (hello-phb4j): no nodes
available to schedule pods
六 常見問題排查
6.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
6.2 本練習準備
[student@workstation ~]$ lab common-troubleshoot setup
6.3 創建應用
[student@workstation ~]$ oc new-project common-troubleshoot
[student@workstation ~]$ oc new-app –name=hello -i php:5.4 \ #從源代碼創建應用
> http://services.lab.example.com/php-helloworld
6.4 查看詳情
[student@workstation ~]$ oc describe is php -n openshift
結論:由上可知,倉庫中不存在所需鏡像。
6.5 修正錯誤
[student@workstation ~]$ oc new-app –name=hello -i php:7.0 http://services.lab.example.com/php-helloworld
[student@workstation ~]$ oc get pod -o wide #再次查看發現一隻出於pending
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-build 0/1 Pending 0 40s <none> <none>
6.6 查看詳情
1 [student@workstation ~]$ oc log hello-1-build #查看log
2 W0720 20:22:16.455008 18942 cmd.go:358] log is DEPRECATED and will be removed in a future version. Use logs instead.
3 [student@workstation ~]$ oc get events #查看事件
4 LAST SEEN FIRST SEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
5 56s 4m 15 hello-1-build.15b31cbd8da8ff1e Pod Warning FailedScheduling default-scheduler 0/3 nodes are available: 1 MatchNodeSelector, 2 NodeNotReady.
6 [student@workstation ~]$ oc describe pod hello-1-build #查看詳情
7 ……
8 Warning FailedScheduling 31s (x22 over 5m) default-scheduler 0/3 nodes are available: 1 MatchNodeSelector, 2 NodeNotReady.
9 結論:由上可知,沒有node可供調度此pod。
10 [root@master ~]# oc get nodes #在master節點進一步排查node情況
11 NAME STATUS ROLES AGE VERSION
12 master.lab.example.com Ready master 1d v1.9.1+a0ce1bc657
13 node1.lab.example.com NotReady compute 1d v1.9.1+a0ce1bc657
14 node2.lab.example.com NotReady compute 1d v1.9.1+a0ce1bc657
15 結論:由上可知,node狀態異常,都未出於ready狀態。
6.7 檢查服務
[root@node1 ~]# systemctl status atomic-openshift-node.service
[root@node2 ~]# systemctl status atomic-openshift-node.service
[root@node1 ~]# systemctl status docker
[root@node2 ~]# systemctl status docker
結論:由上可知,node節點的docker異常。
6.8 啟動服務
[root@node1 ~]# systemctl start docker
[root@node2 ~]# systemctl start docker
6.9 確認驗證
[root@master ~]# oc get nodes #再次查看node狀態
NAME STATUS ROLES AGE VERSION
master.lab.example.com Ready master 1d v1.9.1+a0ce1bc657
node1.lab.example.com Ready compute 1d v1.9.1+a0ce1bc657
node2.lab.example.com Ready compute 1d v1.9.1+a0ce1bc657
[student@workstation ~]$ oc get pods #確認pod是否正常調度至node
NAME READY STATUS RESTARTS AGE
hello-1-build 1/1 Running 0 22m
[student@workstation ~]$ oc describe is #查看is詳情
結論:由上可知,IS也將image推送至內部倉庫。
七 oc命令綜合實驗
7.1 前置準備
準備完整的OpenShift集群,參考《003.OpenShift網絡》2.1。
7.2 本練習準備
[student@workstation ~]$ lab execute-review setup
7.3 git項目至本地
[student@workstation ~]$ cd /home/student/DO280/labs/execute-review/
[student@workstation execute-review]$ git clone http://services.lab.example.com/node-hello
7.4 docker構建image
[student@workstation execute-review]$ cd node-hello/
[student@workstation node-hello]$ docker build -t node-hello:latest .
[student@workstation node-hello]$ docker images #查看image
REPOSITORY TAG IMAGE ID CREATED SIZE
node-hello latest ff48daa00d8e 12 seconds ago 495 MB
registry.lab.example.com/rhscl/nodejs-6-rhel7 latest fba56b5381b7 22 months ago 489 MB
7.5 修改docker tag
[student@workstation node-hello]$ docker tag ff48daa00d8e \
> registry.lab.example.com/node-hello:latest
[student@workstation node-hello]$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
node-hello latest ff48daa00d8e About a minute ago 495 MB
registry.lab.example.com/node-hello latest ff48daa00d8e About a minute ago 495 MB
registry.lab.example.com/rhscl/nodejs-6-rhel7 latest fba56b5381b7 22 months ago 489 MB
7.6 push image
[student@workstation node-hello]$ docker push registry.lab.example.com/node-hello:latest
7.7 創建project
[student@workstation ~]$ oc login -u developer -p redhat \
> https://master.lab.example.com
[student@workstation ~]$ oc projects
[student@workstation ~]$ oc project execute-review
[student@workstation ~]$ oc new-app registry.lab.example.com/node-hello –name hello
[student@workstation ~]$ oc get all #查看全部資源
7.8 排查ImagePullBackOff
[student@workstation ~]$ oc logs hello-1-2jkkj #查看日誌
Error from server (BadRequest): container “hello” in pod “hello-1-2jkkj” is waiting to start: trying and failing to pull image
[student@workstation ~]$ oc describe pod hello-1-2jkkj #查看詳情
[student@workstation ~]$ oc get events –sort-by=’.metadata.creationTimestamp’ #查看事件
結論:由上可知,為image pull失敗。
7.9 手動pull鏡像
[student@workstation ~]$ oc get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-2jkkj 0/1 ImagePullBackOff 0 8m 10.128.0.45 node1.lab.example.com
hello-1-deploy 1/1 Running 0 8m 10.129.0.72 node2.lab.example.com
[root@node1 ~]# docker pull registry.lab.example.com/node-hello #手動拉去也失敗
Using default tag: latest
Trying to pull repository registry.lab.example.com/node-hello …
All endpoints blocked.
結論:由上可知,所有endpoint都被阻塞了。這種類型的錯誤通常發生在OpenShift中,原因是不正確的部署配置或無效docker配置。
7.10 修正docker配置
[root@node1 ~]# vi /etc/sysconfig/docker
將BLOCK_REGISTRY=’–block-registry registry.access.redhat.com –block-registry docker.io –block-registry registry.
lab.example.com’
修改為
BLOCK_REGISTRY=’–block-registry registry.access.redhat.com –block-registry docker.io’
[root@node1 ~]# systemctl restart docker
提示:node2也需要如上操作。
7.11 更新pod
[student@workstation ~]$ oc rollout latest hello
[student@workstation ~]$ oc get pods #確認
NAME READY STATUS RESTARTS AGE
hello-1-deploy 0/1 Error 0 22m
hello-2-75x9t 1/1 Running 0 47s
7.12 確認驗證
[student@workstation ~]$ oc logs hello-2-75x9t #查看log
nodejs server running on http://0.0.0.0:3000
7.13 暴露服務
[student@workstation ~]$ oc expose svc hello –hostname=hello.apps.lab.example.com
route “hello” exposed
7.14 測試服務
[student@workstation ~]$ curl http://hello.apps.lab.example.com
Hi! I am running on host -> hello-2-75x9t
[student@workstation ~]$ lab execute-review grade #腳本驗證試驗
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化