Java之線性表的鏈式存儲——單鏈表
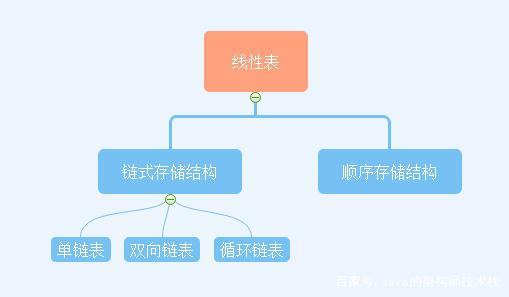
我們都知道,線性表的存儲結構分為兩種,順序存儲結構和鏈式存儲結構,線性表的分類可以參考下圖來學習記憶。今天我們主要來學習一下鏈式存儲結構。
一、鏈式存儲介紹
“鏈式存儲結構,地址可以連續也可以不連續的存儲單元存儲數據元素”——來自定義。
其實,你可以想象這樣一個場景,你想找一個人(他的名字叫小譚),於是你首先去問 A , A 說他不知道,但是他說 B 可能知道,並告訴了你 B 在哪裡,於是你找到 B ,B 說他不知道,但是他說 C 可能知道,並告訴了你 C 的地址,於是你去找到 C ,C 真的知道小譚在何處。
上面場景其實可以幫助我們去理解鏈表,其實每一個鏈表都包含多個節點,節點又包含兩個部分,一個是數據域(儲存節點含有的信息),一個是指針域(儲存下一個節點或者上一個節點的地址),而這個指針域就相當於你去問B,B知道C的地址,這個指針域就是存放的 C 的地址。
鏈表下面其實又細分了3種:單鏈表、雙向鏈表和循環鏈表。今天我們先講單鏈表。
二、單鏈表介紹
什麼是單鏈表呢?單鏈表就是每一個節點只有一個指針域的鏈表。如下圖所示,就是一個帶頭節點的單鏈表。下面我們需要知道什麼是頭指針,頭節點和首元節點。
頭指針:指向鏈表節點的第一個節點的指針
頭節點:指在鏈表的首元節點之前附設的一個節點
首元節點:指在鏈表中存儲第一個實際數據元素的節點(比如上圖的 a1 節點)
三、單鏈表的創建
單鏈表的創建有兩種方式,分別是頭插法和尾插法。
1、頭插法
頭插法,顧名思義就是把新元素插入到頭部的位置,每次新加的元素都作為鏈表的第一個節點。那麼頭插入法在Java中怎麼實現呢。首先我們需要定義一個節點,如下
public class ListNode {
public int val; //數據域
public ListNode next;//指針域
}
然後我們就創建一個頭指針(不帶頭節點)
//元素個數
int n = 5;
//創建一個頭指針
ListNode headNode = new ListNode();
//頭插入法
headNode= createHead(headNode, n);
然後創建一個私有方法去實現頭插法,這裏我們插入5個新元素,頭插入的核心是要先斷開首元節點和頭指針的連接,也就是需要先將原來首元節點的地址存放到新節點的指針域里,也就是 newNode.next = headNode.next,然後再讓頭指針指向新的節點 headNode.next = newNode,這兩步是頭插入的核心,一定要理解。
/**
* 頭插法
* 新的節點放在頭節點的後面,之前的就放在新節點的後面
* @param headNode 頭指針
* @return
*/
private static ListNode createHead(ListNode headNode, int n) {
//插入5個新節點
for (int i = 1; i <= n; i++) {
ListNode newNode = new ListNode();
newNode.val = i;
//將之前的所有節點指向新的節點(也就是新節點指向之前的所有節點)
newNode.next = headNode.next;
//將頭指針指向新的節點
headNode.next = newNode;
}
return headNode;
}
最後我把鏈表打印輸出一下(其實也是單鏈表的遍歷),判斷條件就是只有當指針域為空的時候才是最後一個節點。
private static void printLinkedList(ListNode headNode) {
int countNode = 0;
while (headNode.next != null){
countNode++;
System.out.println(headNode.next.val);
headNode = headNode.next;
}
System.out.println("該單鏈表的節點總數:" +countNode);
}
最後的輸出結果顯然是逆序,因為沒一個新的元素都是從頭部插入的,自然第一個就是最後一個,最後一個就是第一個:
2、尾插法
尾插法,顧名思義就是把新元素插入到尾部的位置(也就是最後一個位置),每次新加的元素都作為鏈表的第最後節點。那麼尾插法在 Java 中怎麼實現呢,這裏還是採用不帶頭節點的實現方式,頭節點和頭指針和頭插入的實現方式一樣,這裏我就直接將如何實現:
/**
* 尾插法
* 找到鏈表的末尾結點,把新添加的數據作為末尾結點的後續結點
* @param headNode
*/
private static ListNode createByTail(ListNode headNode, int n) {
//讓尾指針也指向頭指針
ListNode tailNode = headNode;
for (int i = 1; i <= n; i++) {
ListNode newNode = new ListNode();
newNode.val = i;
newNode.next = null;
//插入到鏈表尾部
tailNode.next = newNode;
//指向新的尾節點,tailer永遠存儲最後一個節點的地址
tailNode = newNode;
}
return headNode;
}
和頭插入不同的是,我們需要聲明一個尾指針來輔助我們實現,最開始,尾指針指向頭指針,每插入一個元素,尾指針就后移一下,這裏我們來講一下原理:每次往末尾新加一個節點,我們就需要把原來的連接斷開,那怎麼斷開呢,我們首先需要讓尾指針指向新的節點,也就是 tailNode.next = newNode; 然後再讓尾指針后移一個位置,讓尾指針指向最後一個節點。也就是尾指針始終指向最後一個節點,最後將頭指針返回,輸出最後結果:
四、單鏈表的刪除
既然單鏈表創建好了,怎麼在鏈表裡面刪除元素呢,單鏈表的刪除,我分為了兩種情況刪除,分別是刪除第i個節點和刪除指定元素的節點。
1、刪除第i個節點
我們可以先來理一下思路:在單鏈表裡,節點與節點之間都是通過指針域鏈接起來的,所以如果我們想實現刪除的操作,實際上是需要我們去改變相應指針域對應得地址的。當想去刪除第i個元素的時候,比如要刪除上圖的第3個元素(也就是3),實際上我們要做的就是要讓2號元素指向4號元素(其實就是需要修改2號元素的指針域,讓2號元素的指針域存儲4號元素)。那麼怎麼做才能實現這一步呢?很顯然,要實現這個步驟,我們必須要找到4號元素和2號元素,但是再仔細想一下,其實我們只需要找到2號元素就可以了,因為4號元素的地址存儲再2號的下一個元素的指針域裏面。
所以綜上所述分析我們可以得出刪除的兩個核心步驟:
1.刪除第i個節點,需要先找到第 i-1 個個節點,也就是第i個節點的前一個節點;
2.然後讓第 i-1 個節點指向第 i-1 個節點的下下個節點
下面的代碼具體實現了怎麼刪除第i個元素。
/**
* 刪除第i個節點
* 1,2 4,4,5
* 刪除之後應該是1,2,4,5
* @param headNode
* @param index
* @return
*/
public static ListNode deleteNodeByIndex(ListNode headNode, int index) {
int count = 1;
//將引用給它
ListNode preNode = headNode;
//看計數器是不是到了i-1,如果到了i-1,就找到了第i-1個節點
while (preNode.next != null && count <= index -1){
//尋找要刪除的當前節點的前一個節點
count++;
preNode = preNode.next;
}
if (preNode != null){
preNode.next = preNode.next.next;
}
return headNode;
}
2、刪除指定元素的那個節點
刪除指定元素節點的實現方法有兩種,第一種就是先找到指定元素對應的鏈表的位置( index ),然後再按照刪除第 i 個節點的思路刪除即可。實現方法如下圖所示:
/**
* 刪除鏈表指定數值的節點
* @param headNode
* @param val
* @return
*/
private static ListNode deleteNodeByNum(ListNode headNode, int val) {
ListNode deleteOne = headNode;
int countByDeleteOne = 1;
while (deleteOne.next != null){
if (deleteOne.next.val == val){
deleteOne = deleteOne.next;
break;
}
countByDeleteOne ++;
deleteOne = deleteOne.next;
}
return deleteNodeByIndex(headNode, countByDeleteOne);
}
第二種方法的實現就很精妙(前提是此節點不是尾節點)
public void deleteNode(ListNode node) {
//刪除node即通過將後面的值賦給node,然後更改node的指針指向下下一個結點即可
node.val = node.next.val;
node.next = node.next.next;
}
五、單鏈表的查詢(及修改)
單鏈表的查詢實現很簡單,就是遍歷當前單鏈表,然後用一個計數器累加到當前下標,那麼當前的這個節點就是要查詢的那個節點,然後再返回即可,當然需要判斷傳過來的這個下標是否合法。當然如果需要修改,就需要把當前找到的節點的數據域重新賦上需要修改的值即可,這裏就不上代碼了。具體實現如下:
private static ListNode searchLinkedList(ListNode headNode, int index) {
//如果下標是不合法的下標就表示找不到
if (index < 1 || index > getLinkedListLength(headNode)){
return null;
}
for (int i = 0; i < index; i++) {
headNode = headNode.next;
}
return headNode;
}
獲取單鏈表的長度(注意我這裏定義的 headNode 是頭指針不是頭節點)
/**
* 求單鏈表長度
* @param headNode
* @return
*/
private static int getLinkedListLength(ListNode headNode) {
int countNode = 0;
while (headNode.next != null){
countNode++;
headNode = headNode.next;
}
return countNode;
}
六、小結
單鏈表的相關操作就講解完了,其實通過上面對單鏈表的相關操作,我們不難發現,單鏈表的刪除和插入其實很方便,只需要改變指針的指向就可以完成,但是查找元素的時候就比較麻煩,因為在查找的時候,需要把整個鏈表從頭到尾遍歷一次。
公眾號:良許Linux
有收穫?希望老鐵們來個三連擊,給更多的人看到這篇文章
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?