環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※回頭車貨運收費標準
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※推薦評價好的iphone維修中心
※教你寫出一流的銷售文案?
※台中搬家公司教你幾個打包小技巧,輕鬆整理裝箱!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!
摘錄自2020年5月14日自由時報報導
武漢肺炎(COVID-19)持續蔓延全球,先前部分國家驚見貓科動物也遭傳染,日本最新研究發現,雖然目前尚未發現病毒由貓傳人的證據,但已經證實該種病毒能夠「貓傳貓」。
根據《共同社》報導,日本東京大學醫科研究所13日在《美國醫學期刊》刊登研究成果,負責這項研究的教授河岡義裕與研究團隊,發現新型冠狀病毒能夠「貓傳貓」,但貓感染後沒有發生明顯症狀,有鑑於寵物在外有機會在無意間遭受感染,河岡建議飼主不要讓貓出門,盡量待在室內。
研究團隊使用新型冠狀病毒,感染3隻實驗用的貓,並將這些貓分別與1隻健康的貓分組放置於籠子中,每相隔24小時候就對健康的貓進行採檢,實驗第2天,1隻健康的貓驗出病毒;實驗第5天,其他2隻貓也測出病毒,不過並沒有發生體溫升高、體重變輕等症狀。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
※台中搬家公司費用怎麼算?
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
※台中搬家公司費用怎麼算?
摘錄自2020年5月15日中央社報導
土耳其氣象總局今(14日)就來襲的一波熱浪提出警告,15至19日境內大部分地區可能較正常氣溫高出攝氏9到13度。
「自由日報」(Hurriyet Daily News)報導,包括馬爾馬拉海(Marmara region)、愛琴海、東地中海地區,以及安納托利亞高原(Anatolia)中部部分地區的氣溫,於15至19日間可能會比正常氣溫高出9到13度。
土耳其氣象總局警告,甚至可能會遠遠超過於過去幾年出現的5月高溫紀錄。這一波熱浪將會襲擊全國大部分城巿,伊斯坦堡省長辦公室已就此發布警告。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
摘錄自2020年5月19日自由時報報導
南韓LG化學再傳工安意外,位在忠清南道瑞山市的催化劑工廠,在當地時間今(19)日下午2時20分(台灣時間下午1時20分)左右爆炸失火,造成1死2傷。
《韓聯社》報導,該化工廠的催化劑疑似在過高的壓力下爆炸而引發大火,火勢已在下午3時30分(台灣時間下午2時30分)被撲滅,據消防部門表示,沒有有害化學物質外洩。目前該設施已關閉,警方和消防部門將在清理現場後調查確切事故原因。
本月7日,LG化學在印度投資的一家化工廠發生重大事故,廠內兩座5000公噸級苯乙烯儲存槽因不明原因發生嚴重外洩,造成12人死亡,1000多人住院。
建築
公害污染
生活環境
污染治理
國際新聞
南韓
化學工廠
工安事故
化工廠爆炸
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※回頭車貨運收費標準
※推薦評價好的iphone維修中心
※超省錢租車方案
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!
※推薦台中搬家公司優質服務,可到府估價
摘錄自2020年5月19日自由時報報導
美國國防部已對國會提出一項提案,擴大對稀土的投資上限,以停止對中國的依賴程度,這些稀土可以用來製造飛彈和彈藥、極音速武器,及相關電子產品。如果美國可以重新生產稀土,中國打「稀土牌」的威脅程度將大幅降低。
根據《國防新聞》報導,美國國防部希望提高《國防生產法》的支出上限,在開採稀土上提升至最高17.5億美元(約新台幣523億),在微電子晶片上增至3.5億美元(約新台幣104億),當涉及到極音速武器時,將會沒有上限。據悉,此提案已於本月初提出,已納入國會正在起草的年度國防政策法案。
美國防部副部長洛德(Ellen Lord)去年8月曾表示,國防部正與澳洲進行談判,要求其為美軍提供稀土。澳洲Lynas公司擁有稀土礦,同時在馬來西亞也有精煉廠,可能是此計劃的核心。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※回頭車貨運收費標準
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※推薦評價好的iphone維修中心
※教你寫出一流的銷售文案?
※台中搬家公司教你幾個打包小技巧,輕鬆整理裝箱!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!

最近在整理優化.net代碼時,發現幾個很不友好的處理現象:登錄判斷、權限認證、日誌記錄、異常處理等通用操作,在項目中的action中到處都是。在代碼優化上,這一點是很重要着力點。這時.net中的過濾器、攔截器(Filter)就派上用場了。現在根據這幾天的實際工作,對其做了一個簡單的梳理,分享出來,以供大家參考交流,如有寫的不妥之處,多多指出,多多交流。
.net中的Filter中主要包括以下4大類:Authorize(授權),ActionFilter(自定義),HandleError(錯誤處理)。
|
過濾器 |
類名 |
實現接口 |
描述 |
|
授權 |
AuthorizeAttribute |
IAuthorizationFilter |
此類型(或過濾器)用於限制進入控制器或控制器的某個行為方法,比如:登錄、權限、訪問控制等等 |
|
異常 |
HandleErrorAttribute |
IExceptionFilter |
用於指定一個行為,這個被指定的行為處理某個行為方法或某個控制器裏面拋出的異常,比如:全局異常統一處理。 |
|
自定義 |
ActionFilterAttribute |
IActionFilter和IResultFilter |
用於進入行為之前或之後的處理或返回結果的之前或之後的處理,比如:用戶請求日誌詳情日誌記錄 |
認證授權主要是對所有action的訪問第一入口認證,對用戶的訪問做第一道監管過濾攔截閘口。
實現方式:需要自定義一個類,繼承AuthorizeAttribute並重寫OnAuthorization,在OnAuthorization中能夠獲取到用戶請求的所有Request信息,其實我們做的所有認證攔截操作,其所有數據支撐都是來自Request中。
具體驗證流程設計:
IP白名單:這個主要針對的是API做IP限制,只有指定IP才可訪問,非指定IP直接返回
請求頻率控制:這個主要是控制用戶的訪問頻率,主要是針對API做,超出請求頻率直接返回。
登錄認證:登錄認證一般我們採用的是通過在請求的header中傳遞token的方式來進行驗證,這樣即使用與一般的MVC登錄認證,也使用與API接口的Auth認證,並且也不依賴於用戶前端js設置等。
授權認證:授權認證就簡單了,主要是驗證該用戶是否具有該權限,如果不具有,直接做下相應的返回處理。
MVC和API異同:
命名空間:MVC:System.Web.Http.Filters;API:System.Web.Mvc
注入方式:在注入方式上,主要包括:全局->控制器Controller->行為Action
全局註冊:針對所有系統的所有Aciton都使用
Controller:只針對該Controller下的Action起作用
Action:只針對該Action起作用
其中全局註冊,針對MVC和API還有一些差異:
MVC在 FilterConfig.cs中注入
filters.Add(new XYHMVCAuthorizeAttribute());
API 在 WebApiConfig.cs 中注入
config.Filters.Add(new XYHAPIAuthorizeAttribute());
注意事項:在實際使用中,針對認證授權,我們一般都是添加全局認證,但是,有的action又不需要做認證,比如本來的登錄Action等等,那麼該如何排除呢?其實也很簡單,我們只需要在自定定義一個Attribute集成Attribute,或者系統的AllowAnonymousAttribute,在不需要驗證的action中只需要註冊上對於的Attribute,並在驗證前做一個過濾即可,比如:
// 有 AllowAnonymous 屬性的接口直接開綠燈
if (actionContext.ActionDescriptor.GetCustomAttributes<AllowAnonymousAttribute>().Any())
{
return;
}
API AuthFilterAttribute實例代碼
/// <summary> /// 授權認證過濾器 /// </summary> public class XYHAPIAuthFilterAttribute : AuthorizationFilterAttribute { /// <summary> /// 認證授權驗證 /// </summary> /// <param name="actionContext">請求上下文</param> public override void OnAuthorization(HttpActionContext actionContext) { // 有 AllowAnonymous 屬性的接口直接開綠燈 if (actionContext.ActionDescriptor.GetCustomAttributes<AllowAnonymousAttribute>().Any()) { return; } // 在請求前做一層攔截,主要驗證token的有效性和驗簽 HttpRequest httpRequest = HttpContext.Current.Request; // 獲取apikey var apikey = httpRequest.QueryString["apikey"]; // 首先做IP白名單校驗 MBaseResult<string> result = new AuthCheckService().CheckIpWhitelist(FilterAttributeHelp.GetIPAddress(actionContext.Request), apikey); // 檢驗時間戳 string timestamp = httpRequest.QueryString["Timestamp"]; if (result.Code == MResultCodeEnum.successCode) { // 檢驗時間戳 result = new AuthCheckService().CheckTimestamp(timestamp); } if (result.Code == MResultCodeEnum.successCode) { // 做請求頻率驗證 string acitonName = actionContext.ActionDescriptor.ActionName; string controllerName = actionContext.ActionDescriptor.ControllerDescriptor.ControllerName; result = new AuthCheckService().CheckRequestFrequency(apikey, $"api/{controllerName.ToLower()}/{acitonName.ToLower()}"); } if (result.Code == MResultCodeEnum.successCode) { // 簽名校驗 // 獲取全部的請求參數 Dictionary<string, string> queryParameters = httpRequest.GetAllQueryParameters(); result = new AuthCheckService().SignCheck(queryParameters, apikey); if (result.Code == MResultCodeEnum.successCode) { // 如果有NoChekokenFilterAttribute 標籤 那麼直接不做token認證 if (actionContext.ActionDescriptor.GetCustomAttributes<XYHAPINoChekokenFilterAttribute>().Any()) { return; } // 校驗token的有效性 // 獲取一個 token string token = httpRequest.Headers.GetValues("Token") == null ? string.Empty : httpRequest.Headers.GetValues("Token")[0]; result = new AuthCheckService().CheckToken(token, apikey, httpRequest.FilePath); } } // 輸出 if (result.Code != MResultCodeEnum.successCode) { // 一定要實例化一個response,是否最終還是會執行action中的代碼 actionContext.Response = new HttpResponseMessage(HttpStatusCode.OK); //需要自己指定輸出內容和類型 HttpContext.Current.Response.ContentType = "text/html;charset=utf-8"; HttpContext.Current.Response.Write(JsonConvert.SerializeObject(result)); HttpContext.Current.Response.End(); // 此處結束響應,就不會走路由系統 } } }
MVC AuthFilterAttribute實例代碼
/// <summary> /// MVC自定義授權 /// 認證授權有兩個重寫方法 /// 具體的認證邏輯實現:AuthorizeCore 這個裡面寫具體的認證邏輯,認證成功返回true,反之返回false /// 認證失敗處理邏輯:HandleUnauthorizedRequest 前一步返回 false時,就會執行到該方法中 /// 但是,我平時在應用過程中,一般都是在AuthorizeCore根據不同的認證結果,直接做認證后的邏輯處理 /// </summary> public class XYHMVCAuthorizeAttribute : AuthorizeAttribute { /// <summary> /// 認證邏輯 /// </summary> /// <param name="filterContext">過濾器上下文</param> public override void OnAuthorization(AuthorizationContext filterContext) { // 此處主要寫認證授權的相關驗證邏輯 // 該部分的驗證一般包括兩個部分 // 登錄權限校驗 // --我們的一般處理方式是,通過header中傳遞一個token來進行邏輯驗證 // --當然不同的系統在設計上也不盡相同,有的也會採用session等方式來驗證 // --所以最終還是根據其項目本身的實際情況來進行對應的邏輯操作 // 具體的頁面權限校驗 // --該部分的驗證是具體的到頁面權限驗證 // --我看有得小夥伴沒有做到這一個程度,直接將這一步放在前端js來驗證,這樣不是很安全,但是可以攔住小白用戶 // --當然有的系統根本就沒有做權限控制,那就更不需要這一個邏輯了。 // --所以最終還是根據其項目本身的實際情況來進行對應的邏輯操作 // 現在用一個粗暴的方式來簡單模擬實現過,用系統當前時間段秒廚藝3,取餘數 // 當餘數為0:認證授權通過 // 1:代表為登錄,調整至登錄頁面 // 2:代表無訪問權限,調整至無權限提示頁面 // 當然,在這也還可以做一些IP白名單,IP黑名單驗證 請求頻率驗證等等 // 說到這而,還有一點需要注意,如果我們選擇的是全局註冊該過濾器,那麼如果有的頁面根本不需要權限認證,比如登錄頁面,那麼我們可以給不需要權限的認證的控制器或者action添加一個特殊的註解 AllowAnonymous ,來排除 // 獲取Request的幾個關鍵信息 HttpRequest httpRequest = HttpContext.Current.Request; string acitonName = filterContext.ActionDescriptor.ActionName; string controllerName = filterContext.ActionDescriptor.ControllerDescriptor.ControllerName; // 注意:如果認證不通過,需要設置filterContext.Result的值,否則還是會執行action中的邏輯 filterContext.Result = null; int thisSecond = System.DateTime.Now.Second; switch (thisSecond % 3) { case 0: // 認證授權通過 break; case 1: // 代表為登錄,調整至登錄頁面 // 只有設置了Result才會終結操作 filterContext.Result = new RedirectResult("/html/Login.html"); break; case 2: // 代表無訪問權限,調整至無權限提示頁面 filterContext.Result = new RedirectResult("/html/NoAuth.html"); break; } } }
自定義過濾器,主要是監控action請求前後,處理結果返回前後的事件。其中API只有請求前後的兩個方法。
|
重新方法 |
方法功能描述 |
使用於 |
|
OnActionExecuting |
一個請求在進入到aciton邏輯前執行 |
MVC、API |
|
OnActionExecuted |
一個請求aciton邏輯執行后執行 |
MVC、API |
|
OnResultExecuting |
對應的view視圖渲染前執行 |
MVC |
|
OnResultExecuted |
對應的view視圖渲染后執行 |
MVC |
在這幾個方法中,我們一般主要用來記錄交互日誌,記錄每一個步驟的耗時情況,以便後續系統優化使用。具體的使用,根據自身的業務場景使用。
其中MVC和API的異同點,和上面說的認證授權的異同類似,不在詳細說明。
下面的一個實例代碼:
API定義過濾器實例DEMO代碼
/// <summary> /// Action過濾器 /// </summary> public class XYHAPICustomActionFilterAttribute : ActionFilterAttribute { /// <summary> /// Action執行開始 /// </summary> /// <param name="actionContext"></param> public override void OnActionExecuting(HttpActionContext actionContext) { } /// <summary> /// action執行以後 /// </summary> /// <param name="actionContext"></param> public override void OnActionExecuted(HttpActionExecutedContext actionContext) { try { // 構建一個日誌數據模型 MApiRequestLogs apiRequestLogsM = new MApiRequestLogs(); // API名稱 apiRequestLogsM.API = actionContext.Request.RequestUri.AbsolutePath; // apiKey apiRequestLogsM.API_KEY = HttpContext.Current.Request.QueryString["ApiKey"]; // IP地址 apiRequestLogsM.IP = FilterAttributeHelp.GetIPAddress(actionContext.Request); // 獲取token string token = HttpContext.Current.Request.Headers.GetValues("Token") == null ? string.Empty : HttpContext.Current.Request.Headers.GetValues("Token")[0]; apiRequestLogsM.TOKEN = token; // URL apiRequestLogsM.URL = actionContext.Request.RequestUri.AbsoluteUri; // 返回信息 var objectContent = actionContext.Response.Content as ObjectContent; var returnValue = objectContent.Value; apiRequestLogsM.RESPONSE_INFOR = returnValue.ToString(); // 由於數據庫中最大隻能存儲4000字符串,所以對返回值做一個截取 if (!string.IsNullOrEmpty(apiRequestLogsM.RESPONSE_INFOR) && apiRequestLogsM.RESPONSE_INFOR.Length > 4000) { apiRequestLogsM.RESPONSE_INFOR = apiRequestLogsM.RESPONSE_INFOR.Substring(0, 2000); } // 請求參數 apiRequestLogsM.REQUEST_INFOR = actionContext.Request.RequestUri.Query; // 定義一個異步委託 ,異步記錄日誌 // Func<MApiRequestLogs, string> action = AddApiRequestLogs;//聲明一個委託 // IAsyncResult ret = action.BeginInvoke(apiRequestLogsM, null, null); } catch (Exception ex) { } } }
異常處理對於我們來說很常用,很好的利用異常處理,可以很好的避免全篇的try/catch。異常處理箱單很簡單,值需要自定義集成:ExceptionFilterAttribute,並自定義實現:OnException方法即可。
在OnException我們可以根據自身需要,做一些相應的邏輯處理,比如記錄異常日誌,便於後續問題分析跟進。
OnException還有一個很重要的處理,那就是對異常結果的統一包裝,返回一個很友好的結果給用戶,避免把一些不必要的信息返回給用戶。比如:針對MVC,那麼跟進不同異常,統一調整至友好的提示頁面等等;針對API,那麼我們可以一個統一的返回幾個封裝,便於用戶統一處理結果。
MVC 的異常處理實例代碼:
/// <summary> /// MVC自定義異常處理機制 /// 說道異常處理,其實我們腦海中的第一反應,也該是try/cache操作 /// 但是在實際開發中,很有可能地址錯誤根本就進入不到try中,又或者沒有被try處理到異常 /// 該類就發揮了作用,能夠很好的未經捕獲的異常,並做相應的邏輯處理 /// 自定義異常機制,主要集成HandleErrorAttribute 重寫其OnException方法 /// </summary> public class XYHMVCHandleError : HandleErrorAttribute { /// <summary> /// 處理異常 /// </summary> /// <param name="filterContext">異常上下文</param> public override void OnException(ExceptionContext filterContext) { // 我們在平時的項目中,異常處理一般有兩個作用 // 1:記錄異常的詳細日誌,便於事後分析日誌 // 2:對異常的統一友好處理,比如根據異常類型重定向到友好提示頁面 // 在這裏面既能獲取到未經處理的異常信息,也能獲取到請求信息 // 在此可以根據實際項目需要做相應的邏輯處理 // 下面簡單的列舉了幾個關鍵信息獲取方式 // 控制器名稱 注意,這樣獲取出來的是一個文件的全路徑 string contropath = filterContext.Controller.ToString(); // 訪問目錄的相對路徑 string filePath = filterContext.HttpContext.Request.FilePath; // url完整地址 string url = (filterContext.HttpContext.Request.Url.AbsoluteUri).ExUrlDeCode(); // 請求方式 post get string httpMethod = filterContext.HttpContext.Request.HttpMethod; // 請求IP地址 string ip = filterContext.HttpContext.Request.GetIPAddress(); // 獲取全部的請求參數 HttpRequest httpRequest = HttpContext.Current.Request; Dictionary<string, string> queryParameters = httpRequest.GetAllQueryParameters(); // 獲取異常對象 Exception ex = filterContext.Exception; // 異常描述信息 string exMessage = ex.Message; // 異常堆棧信息 string stackTrace = ex.StackTrace; // 根據實際情況記錄日誌(文本日誌、數據庫日誌,建議具體步驟採用異步方式來完成) filterContext.ExceptionHandled = true; // 模擬根據不同的做對應的邏輯處理 int statusCode = filterContext.HttpContext.Response.StatusCode; if (statusCode>=400 && statusCode<500) { filterContext.Result = new RedirectResult("/html/404.html"); } else { filterContext.Result = new RedirectResult("/html/500.html"); } } }
API 的異常處理實例代碼:
/// <summary> /// API自定義異常處理機制 /// 說道異常處理,其實我們腦海中的第一反應,也該是try/cache操作 /// 但是在實際開發中,很有可能地址錯誤根本就進入不到try中,又或者沒有被try處理到異常 /// 該類就發揮了作用,能夠很好的未經捕獲的異常,並做相應的邏輯處理 /// 自定義異常機制,主要集成ExceptionFilterAttribute 重寫其OnException方法 /// </summary> public class XYHAPIHandleError : ExceptionFilterAttribute { /// <summary> /// 處理異常 /// </summary> /// <param name="actionExecutedContext">異常上下文</param> public override void OnException(HttpActionExecutedContext actionExecutedContext) { // 我們在平時的項目中,異常處理一般有兩個作用 // 1:記錄異常的詳細日誌,便於事後分析日誌 // 2:對異常的統一友好處理,比如根據異常類型重定向到友好提示頁面 // 在這裏面既能獲取到未經處理的異常信息,也能獲取到請求信息 // 在此可以根據實際項目需要做相應的邏輯處理 // 下面簡單的列舉了幾個關鍵信息獲取方式 // action名稱 string actionName = actionExecutedContext.ActionContext.ActionDescriptor.ActionName; // 控制器名稱 string controllerName =actionExecutedContext.ActionContext.ControllerContext.ControllerDescriptor.ControllerName; // url完整地址 string url = (actionExecutedContext.Request.RequestUri.AbsoluteUri).ExUrlDeCode(); // 請求方式 post get string httpMethod = actionExecutedContext.Request.Method.Method; // 請求IP地址 string ip = actionExecutedContext.Request.GetIPAddress(); // 獲取全部的請求參數 HttpRequest httpRequest = HttpContext.Current.Request; Dictionary<string, string> queryParameters = httpRequest.GetAllQueryParameters(); // 獲取異常對象 Exception ex = actionExecutedContext.Exception; // 異常描述信息 string exMessage = ex.Message; // 異常堆棧信息 string stackTrace = ex.StackTrace; // 根據實際情況記錄日誌(文本日誌、數據庫日誌,建議具體步驟採用異步方式來完成) // 自己的記錄日誌落地邏輯略 ...... // 構建統一的內部異常處理機制,相當於對異常做一層統一包裝暴露 MBaseResult<string> result = new MBaseResult<string>() { Code = MResultCodeEnum.systemErrorCode, Message = MResultCodeEnum.systemError }; actionExecutedContext.Response = new HttpResponseMessage(HttpStatusCode.OK); //需要自己指定輸出內容和類型 HttpContext.Current.Response.ContentType = "text/html;charset=utf-8"; HttpContext.Current.Response.Write(JsonConvert.SerializeObject(result)); HttpContext.Current.Response.End(); // 此處結束響應,就不會走路由系統 } }
.net過濾器,我個人的一句話理解就是:對action的各個階段進行統一的監控處理等操作。.net過濾器中,其中每一個種過濾器的執行先後順序為:Authorize(授權)–>ActionFilter(自定義)–>HandleError(錯誤處理)
好了,就先聊到這而,如果什麼地方說的不對之處,多多指點和多多包涵。我自己寫了一個練習DEMO,裏面會有每一種情況的處理說明。有興趣的可以取下載下來看一看,謝謝。
DEMO在GitHub地址為:https://github.com/xuyuanhong0902/XYH.FilterTest.git
END
為了更高的交流,歡迎大家關注我的公眾號,掃描下面二維碼即可關注,謝謝:
認證授權
時間戳
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
※台中搬家公司費用怎麼算?
本文目錄
前言
Oracle 公司計劃廢除 Java 中的古董:序列化技術,因為它帶來了許多嚴重的安全問題(如序列化存儲安全、反序列化安全、傳輸安全等),據統計,至少有3分之1的漏洞是序列化帶來的,這也是 1997 年誕生序列化技術的一個巨大錯誤。但是,序列化技術現在在 Java 應用中無處不在,特別是現在的持久化框架和分佈式技術中,都需要利用序列化來傳輸對象,如:Hibernate、Mybatis、Java RMI、Dubbo等,即對象要存儲或者傳輸都不可避免要用到序列化技術,所以刪除序列化技術將是一個長期的計劃。
你在實際工作中可能會很難有機會真正用到Java自帶的序列化技術了,工業界一般也會選擇一些更安全的對象編解碼方案例如Google的Protobuf等。所以,對於Java序列化,我們不必再投入過多的精力學習,你花20分鐘讀完本文所掌握的知識,對於應付日常源碼閱讀中遇到的遺留的Java序列化技術應該是足夠了。
一、序列化是什麼
序列化機制允許將實現序列化的Java對象轉換成字節序列,這些字節序列可以保存在磁盤上,或通過網絡傳輸,以備以後重新恢復成原來的對象。序列化機制使得對象可以脫離程序的運行而獨立存在。
本文中用序列化來簡稱整個序列化和反序列化機制。
二、為什麼需要序列化
所有可能在網絡上傳輸的對象的類都應該是可序列化的,否則程序將會出現異常,比如RMI(Remote Method Invoke,即遠程方法調用,是JavaEE的基礎)過程中的參數和返回值;所有需要保存到磁盤裡的對象的類都必須可序列化,比如Web應用中需要保存到HttpSession或ServletContext屬性的Java對象。
因為序列化是RMI過程的參數和返回值都必須實現的機制,而RMI又是Java EE技術的基礎——所有的分佈式應用常常需要跨平台、跨網絡,所以要求所有傳遞的參數、返回值必須實現序列化。因此序列化機制是Java EE平台的基礎。通常建議:程序創建的每個JavaBean類都實現Serializable。
三、序列化怎麼用
如果一個類的對象需要序列化,那麼在Java語法層面,這個類需要:
下面我們通過代碼示例來看看序列化最基本的用法。我們創建了Person類,其擁有兩個基本類型的屬性,並實現了Serializable接口。testSerialize方法用來測試序列化,testDeserialize方法用來測試反序列化。
1 import org.junit.Test; 2 3 import java.io.*; 4 5 public class SerializableTest { 6 7 @Test 8 public void testSerialize() { 9 Person one = new Person(12, 148.2); 10 Person two = new Person(35, 177.8); 11 12 try (ObjectOutputStream output = 13 new ObjectOutputStream(new FileOutputStream("Person.txt"))) { 14 output.writeObject(one); 15 output.writeObject(two); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 } 20 21 @Test 22 public void testDeserialize() { 23 24 try (ObjectInputStream input = 25 new ObjectInputStream(new FileInputStream("Person.txt"))) { 26 Person one = (Person) input.readObject(); 27 Person two = (Person) input.readObject(); 28 29 System.out.println(one); 30 System.out.println(two); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } catch (ClassNotFoundException e) { 34 e.printStackTrace(); 35 } 36 } 37 } 38 39 class Person implements Serializable { 40 int age; 41 double height; 42 43 public Person(int age, double height) { 44 this.age = age; 45 this.height = height; 46 } 47 48 @Override 49 public String toString() { 50 return "Person{" + 51 "age=" + age + 52 ", height=" + height + 53 '}'; 54 } 55 }
四、序列化深度探秘
如果某個類需要支持序列化功能,那麼它必須實現Serializable接口,否則會報 java.io.NotSerializableException。Serializable接口是一個標誌性接口(Marker Interface),也就是說,該接口並不包含任何具體的方法,是一個空接口,僅僅用來判斷該類是否能夠序列化。JDK8中Serializable接口的源碼如下:
1 package java.io; 2 3 public interface Serializable { 4 }
在 ObjectOutputStream.java 的 writeObject0 方法中,我們確實可以看到對對象是否實現了 Serializable接口進行了驗證(第15行),否則會拋出 NotSerializableException 異常(第22行)。
1 private void writeObject0(Object obj, boolean unshared) 2 throws IOException 3 { 4 boolean oldMode = bout.setBlockDataMode(false); 5 depth++; 6 try { 7 ... 8 // remaining cases 9 if (obj instanceof String) { 10 writeString((String) obj, unshared); 11 } else if (cl.isArray()) { 12 writeArray(obj, desc, unshared); 13 } else if (obj instanceof Enum) { 14 writeEnum((Enum<?>) obj, desc, unshared); 15 } else if (obj instanceof Serializable) { 16 writeOrdinaryObject(obj, desc, unshared); 17 } else { 18 if (extendedDebugInfo) { 19 throw new NotSerializableException( 20 cl.getName() + "\n" + debugInfoStack.toString()); 21 } else { 22 throw new NotSerializableException(cl.getName()); 23 } 24 } 25 } finally { 26 depth--; 27 bout.setBlockDataMode(oldMode); 28 } 29 }
在第三部分“序列化怎麼用”部分的示例中,Person類的字段全都是基本類型,我們知道基本類型其地址中直接存放的就是它的值,那如果是引用類型呢?引用類型其地址中存放的是指向堆內存中的一個地址,難道序列化時就是將這個地址進行了保存嗎?顯然,這是說不通的,因為對象的內存地址是可變的,在同一系統的不同運行時刻或者是不同系統中,對象的地址肯定是不同的,因此,序列化內存地址沒有意義。
如果被序列化對象的字段是引用,那麼要求該引用的類型也是可序列化實現了Serializable接口的,否則無法序列化。當對某個對象進行序列化時,系統會自動把該對象的所有Field依次進行序列化,如果某個Field引用到另一個對象,則被引用的對象也會被序列化;如果被引用的對象的Field也引用了其他對象,則被引用的對象也會被序列化,這種情況被稱為遞歸序列化。
如果對象A和對象B同時引用了對象C,那麼,當序列化對象A和對象B時,對象C會被序列化兩次嗎?答案顯然是不會。
要解釋這個問題,就不得不說一下Java序列化的基本算法了:
在一些特殊的場景下,如果一個類里包含的某些Field值是敏感信息,例如銀行賬戶信息等,這時不希望系統將該Field值進行序列化;或者某個Field的類型是不可序列化的,因此不希望對該Field進行遞歸序列化,以避免引發java.io.NotSerializableException異常。
此時,我們就需要自定義序列化了。自定義序列化的常用方式有兩種:
我們先看第一種方式,使用transient關鍵字。transient關鍵字只能用於修飾Field,不可修飾Java程序中的其他成分。使用transient修飾的屬性,java序列化時,會忽略掉此字段,所以反序列化出的對象,被transient修飾的屬性是默認值。對於引用類型,值是null;基本類型,值是0;boolean類型,值是false。
下列代碼中,我們把People的height字段設置為transient,在反序列化時,可觀察到輸出為默認值0.0。
1 import org.junit.Test; 2 3 import java.io.*; 4 5 public class SerializableTest { 6 7 @Test 8 public void testSerialize() { 9 Person one = new Person(12, 156.6); 10 Person two = new Person(16, 177.7); 11 12 try (ObjectOutputStream output = 13 new ObjectOutputStream(new FileOutputStream("Person.txt"))) { 14 output.writeObject(one); 15 output.writeObject(two); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 } 20 21 @Test 22 public void testDeserialize() { 23 24 try (ObjectInputStream input = 25 new ObjectInputStream(new FileInputStream("Person.txt"))) { 26 Person one = (Person) input.readObject(); 27 Person two = (Person) input.readObject(); 28 29 System.out.println(one); 30 System.out.println(two); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } catch (ClassNotFoundException e) { 34 e.printStackTrace(); 35 } 36 } 37 } 38 39 class Person implements Serializable{ 40 protected int age; 41 protected transient double height; 42 43 public Person() { 44 } 45 46 public Person(int age, double height) { 47 this.age = age; 48 this.height = height; 49 } 50 51 @Override 52 public String toString() { 53 return "Person{" + 54 "age=" + age + 55 ", height=" + height + 56 '}'; 57 } 58 }
程序輸出:
Person{age=12, height=0.0}
Person{age=16, height=0.0}
Process finished with exit code 0
使用transient關鍵字修飾Field雖然簡單、方便,但被transient修飾的Field將被完全隔離在序列化機制之外,這樣導致在反序列化恢復Java對象時無法取得該Field值。Java還提供了一種自定義序列化機制,通過這種自定義序列化機制可以讓程序控制如何序列化各Field,甚至完全不序列化某些Field(與使用transient關鍵字的效果相同)。在序列化和反序列化過程中需要特殊處理的類應該提供如下特殊簽名的方法,這些特殊的方法用以實現自定義序列化。
private void writeObject(java.io.ObjectOutputStream out) throws IOException private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException; private void readObjectNoData() throws ObjectStreamException;
下面的示例代碼中,我們在writeObject方法中對Person的字段進行了簡單的加密處理,在readObject方法中對其進行了相應的解密。
1 import org.junit.Test; 2 3 import java.io.*; 4 5 public class SerializableTest { 6 7 @Test 8 public void testSerialize() { 9 Person one = new Person(12, 156.6); 10 Person two = new Person(16, 177.7); 11 12 try (ObjectOutputStream output = 13 new ObjectOutputStream(new FileOutputStream("Person.txt"))) { 14 output.writeObject(one); 15 output.writeObject(two); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 } 20 21 @Test 22 public void testDeserialize() { 23 24 try (ObjectInputStream input = 25 new ObjectInputStream(new FileInputStream("Person.txt"))) { 26 Person one = (Person) input.readObject(); 27 Person two = (Person) input.readObject(); 28 29 System.out.println(one); 30 System.out.println(two); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } catch (ClassNotFoundException e) { 34 e.printStackTrace(); 35 } 36 } 37 } 38 39 class Person implements Serializable{ 40 protected int age; 41 protected double height; 42 43 public Person() { 44 } 45 46 public Person(int age, double height) { 47 this.age = age; 48 this.height = height; 49 } 50 51 private void writeObject(java.io.ObjectOutputStream out) 52 throws IOException { 53 System.out.println("Encryption!"); 54 out.writeInt(age + 1); 55 out.writeDouble(height - 1); 56 } 57 private void readObject(java.io.ObjectInputStream in) 58 throws IOException, ClassNotFoundException { 59 System.out.println("Decryption!"); 60 this.age = in.readInt() - 1; 61 this.height = in.readDouble() + 1; 62 } 63 64 @Override 65 public String toString() { 66 return "Person{" + 67 "age=" + age + 68 ", height=" + height + 69 '}'; 70 } 71 }
被序列化對象具有繼承關係時無非就兩種情況,第一,該類具有子類,第二,該類具有父類。
當該類實現了Serializable接口且具有子類時,根據官方文檔中的說明,其子類天然具有可被序列化的屬性,不需要顯式實現Serializable接口;。
All subtypes of a serializable class are themselves serializable.
當該類實現了Serializable接口且具有父類時,,該類的父類需要實現Serializable接口嗎?在JDK8中Serializable接口的官方文檔中有這樣一段話:
1 /** 2 * ...... 3 * 4 * To allow subtypes of non-serializable classes to be serialized, the 5 * subtype may assume responsibility for saving and restoring the 6 * state of the supertype's public, protected, and (if accessible) 7 * package fields. The subtype may assume this responsibility only if 8 * the class it extends has an accessible no-arg constructor to 9 * initialize the class's state. It is an error to declare a class 10 * Serializable if this is not the case. The error will be detected at 11 * runtime. 12 * 13 * During deserialization, the fields of non-serializable classes will 14 * be initialized using the public or protected no-arg constructor of 15 * the class. A no-arg constructor must be accessible to the subclass 16 * that is serializable. The fields of serializable subclasses will 17 * be restored from the stream. 18 */
閱讀文檔我們得知,為了使得不可序列化類的子類能夠序列化,其子類必須擔負起保存和恢復其超類的public、protected 和 package(if accessible)實例域的責任,且要求其父類必須有一個可訪問的無參構造函數以使得在反序列化時能夠初始化實例域。
我們寫代碼驗證一下,如果父類中沒有可訪問的無參構造函數會發生什麼,注意Person類中沒有無參構造函數。
1 import org.junit.Test; 2 3 import java.io.*; 4 5 public class SerializableTest { 6 7 @Test 8 public void testSerialize() { 9 Student one = new Student(12, 156.6, "1234"); 10 Student two = new Student(16, 177.7, "5678"); 11 12 try (ObjectOutputStream output = 13 new ObjectOutputStream(new FileOutputStream("Student.txt"))) { 14 output.writeObject(one); 15 output.writeObject(two); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 } 20 21 @Test 22 public void testDeserialize() { 23 24 try (ObjectInputStream input = 25 new ObjectInputStream(new FileInputStream("Student.txt"))) { 26 Student one = (Student) input.readObject(); 27 Student two = (Student) input.readObject(); 28 29 System.out.println(one); 30 System.out.println(two); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } catch (ClassNotFoundException e) { 34 e.printStackTrace(); 35 } 36 } 37 } 38 39 class Person{ 40 protected int age; 41 protected double height; 42 43 public Person(int age, double height) { 44 this.age = age; 45 this.height = height; 46 } 47 48 @Override 49 public String toString() { 50 return "Person{" + 51 "age=" + age + 52 ", height=" + height + 53 '}'; 54 } 55 } 56 57 class Student extends Person implements Serializable{ 58 private String id; 59 60 public Student(int age, double height, String id) { 61 super(age, height); 62 this.id = id; 63 } 64 65 @Override 66 public String toString() { 67 return "Student{" + 68 "age=" + age + 69 ", height=" + height + 70 ", id='" + id + '\'' + 71 '}'; 72 } 73 }
程序輸出產生異常:
java.io.InvalidClassException: Student; no valid constructor at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:150) at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:768) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1775) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:371) at SerializableTest.testDeserialize(SerializableTest.java:26) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) ... Process finished with exit code 0
當我們為Person類添加默認構造函數時:
1 class Person{ 2 protected int age; 3 protected double height; 4 5 public Person() { 6 } 7 8 public Person(int age, double height) { 9 this.age = age; 10 this.height = height; 11 } 12 13 @Override 14 public String toString() { 15 return "Person{" + 16 "age=" + age + 17 ", height=" + height + 18 '}'; 19 } 20 }
程序輸出如下,我們可觀察到,父類中的字段都是默認值,只有子類中的字段得到了正確的序列化。出現這種情況的原因是子類並沒有擔負起序列化父類中字段的責任。
Student{age=0, height=0.0, id='1234'}
Student{age=0, height=0.0, id='5678'}
Process finished with exit code 0
為了解決上述問題,我們需要藉助上一節中學到的知識,使用自定義的序列化方法writeObject和readObject來主動將父類中的字段進行序列化。
1 import org.junit.Test; 2 3 import java.io.*; 4 5 public class SerializableTest { 6 7 @Test 8 public void testSerialize() { 9 Student one = new Student(12, 156.6, "1234"); 10 Student two = new Student(16, 177.7, "5678"); 11 12 try (ObjectOutputStream output = 13 new ObjectOutputStream(new FileOutputStream("Studnet.txt"))) { 14 output.writeObject(one); 15 output.writeObject(two); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 } 20 21 @Test 22 public void testDeserialize() { 23 24 try (ObjectInputStream input = 25 new ObjectInputStream(new FileInputStream("Studnet.txt"))) { 26 Student one = (Student) input.readObject(); 27 Student two = (Student) input.readObject(); 28 29 System.out.println(one); 30 System.out.println(two); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } catch (ClassNotFoundException e) { 34 e.printStackTrace(); 35 } 36 } 37 } 38 39 class Person{ 40 protected int age; 41 protected double height; 42 43 public Person() { 44 } 45 46 public Person(int age, double height) { 47 this.age = age; 48 this.height = height; 49 } 50 51 @Override 52 public String toString() { 53 return "Person{" + 54 "age=" + age + 55 ", height=" + height + 56 '}'; 57 } 58 } 59 60 class Student extends Person implements Serializable{ 61 private String id; 62 63 public Student(int age, double height, String id) { 64 super(age, height); 65 this.id = id; 66 } 67 68 private void writeObject(java.io.ObjectOutputStream out) 69 throws IOException { 70 out.defaultWriteObject(); 71 out.writeInt(age); 72 out.writeDouble(height); 73 } 74 75 private void readObject(java.io.ObjectInputStream in) 76 throws IOException, ClassNotFoundException { 77 in.defaultReadObject(); 78 this.age = in.readInt(); 79 this.height = in.readDouble(); 80 } 81 82 @Override 83 public String toString() { 84 return "Student{" + 85 "age=" + age + 86 ", height=" + height + 87 ", id='" + id + '\'' + 88 '}'; 89 } 90 }
程序輸出如下,可以看到完全正確。
Student{age=12, height=156.6, id='1234'}
Student{age=16, height=177.7, id='5678'}
Process finished with exit code 0
五、serialVersionUID的作用及自動生成
我們知道,反序列化必須擁有class文件,但隨着項目的升級,class文件也會升級,序列化怎麼保證升級前後的兼容性呢?
java序列化提供了一個private static final long serialVersionUID 的序列化版本號,只有版本號相同,即使更改了序列化屬性,對象也可以正確被反序列化回來。如果反序列化使用的class的版本號與序列化時使用的不一致,反序列化會報InvalidClassException異常。下面是JDK 8中ArrayList的源碼中的serialVersionUID。
1 public class ArrayList<E> extends AbstractList<E> 2 implements List<E>, RandomAccess, Cloneable, java.io.Serializable 3 { 4 private static final long serialVersionUID = 8683452581122892189L; 5 6 /** 7 * Default initial capacity. 8 */ 9 private static final int DEFAULT_CAPACITY = 10; 10 ... 11 }
序列化版本號可自由指定,如果不指定,JVM會根據類信息自己計算一個版本號,這樣隨着class的升級,就無法正確反序列化;不指定版本號另一個明顯隱患是,不利於jvm間的移植,可能class文件沒有更改,但不同jvm可能計算的規則不一樣,這樣也會導致無法反序列化。
什麼情況下需要修改serialVersionUID呢?分三種情況。
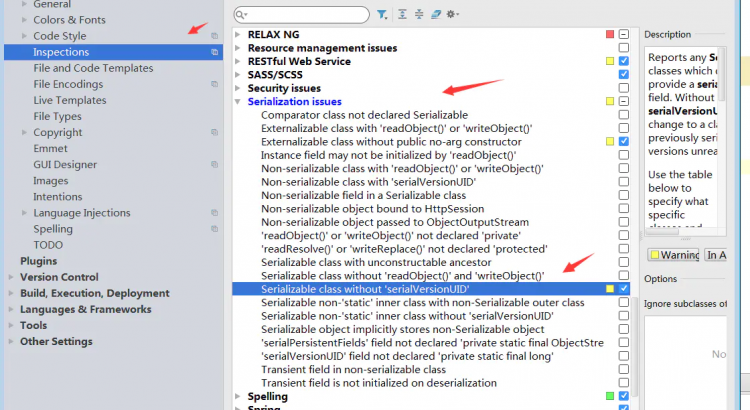
我們在日常編程實踐中,一般會選擇使用IDE來自動生成serialVersionUID,這樣可以最大化地減少重複的可能性。對於IntelliJ IDEA,自動生成serialVersionUID有三步:
六、序列化的缺點
Java序列化存在四個致命缺點,導致其不適用於網絡傳輸:
在真正的生產環境中,一般會選擇其它編解碼框架,領先的跨平台結構化數據表示是 JSON 和 Protocol Buffers,也稱為 protobuf。JSON 由 Douglas Crockford 設計用於瀏覽器與服務器通信,Protocol Buffers 由谷歌設計用於在其服務器之間存儲和交換結構化數據。JSON 和 protobuf 之間最顯著的區別是 JSON 是基於文本的,並且是人類可讀的,而 protobuf 是二進制的,但效率更高。
七、參考文獻
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※推薦台中搬家公司優質服務,可到府估價