環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!

目錄
示例代碼託管在:
博客園地址:
華為雲社區地址:
附件PPT來自開發文檔。術語里的
cc指的是Chromium Compositor
一直以來都想了解瀏覽器合成層的運作機制,但是相關的中文資料大多比較關注框架和開發技術,這方面的資料實在是太少了,後來在chromium官方網站的文檔里找到了項目組成員malaykeshav在 2019年4月的一份關於瀏覽器合成流水線的演講PPT,個人感覺裏面講的非常清楚了,由於沒有找到視頻,有些部分只能自行理解,本文僅對關鍵信息做一些筆記,對此感興趣的讀者可以在文章開頭的github倉庫或附件中拿到這個PPT自行學習。
合成流水線,就是指瀏覽器處理合成層的工作流程,其基本步驟如下:
大致的流程就是說Paint環節會生成一個列表,列表裡登記了頁面元素的繪製指令,接着這個列表需要經過Raster光柵化處理,並在合成幀中處理紋理,最後的Draw環節才是將這些紋理圖展示在瀏覽器內容區。
chromium中預定義了一些指定類型的UI層,大致分為:
paint渲染和後續的rasterized光柵化任務每個層layer是由若干個views組成的,所謂paint,就是每個views將自己對應圖形的繪製指令添加到層的可展示元素列表Display Item List里,這個列表會被添加到一個延遲執行的光柵化任務中,並最終生成當前層的texture紋理(可以理解為當前層的繪製結果),考慮到傳輸性能以及未來增量更新的需求,光柵化的結果會以tiles瓦片形式保存。在chrome中也可以看到頁面瓦片化拆分的結果:
分層的優勢和劣勢也在此進行了說明,和之前我們主動思考的答案基本一致(暗爽一下)。
views中支持的屬性包含Clip剪裁,transform變換,effect效果(如半透明或濾鏡等),mask遮罩,通常按照後序遍歷的方式自底向上進行遍歷處理。
clip剪裁的處理方式是在父節點和子節點之間插入一個剪裁層,用來將其子樹的渲染結果剪裁到限定的範圍內,然後再向上與父級進行合併;
transform變換直接作用於父節點,處理到這個節點時其子樹都已經處理完畢,直接將整體應用變形即可;
effect效果一般直接作用於當前處理的節點,有時也會產生交叉依賴的場景;
PPT第40頁中在介紹effect效果處理時描述了兩種不同的透明度處理需求,從而引出了一個Render Surface的概念,它相當於一個臨時的層,它的子樹需要先繪製在這個層上,然後再向上與父節點進行合併,屏幕就是是根級的Render Surface。
Layer遍歷處理輸出的結果被稱為Quads(從意思上理解好像就是指輸出了很多個矩形方塊),每個quad都持有它被繪製到目標緩衝區所需要的資源,根據它持有的資源不同可以分為:
Solid Color-固定顏色型Texture– 紋理型Tile– 瓦片型Surface– 臨時繪圖表面型Video – 視頻幀型Render Pass – Render Surface類型的佔位區,Render Surface子樹處理完后填充到關聯的Render Pass合成層真正的工作要開始了,主角概念Compositor Frame(合成幀)登場,它負責將quads合併繪製在一起,膠片里59-62頁非常清楚地展示了合成的過程,最終輸出的結果就是根節點的紋理。
chromium是多進程架構,Browser Process瀏覽器進程會對菜單欄等等容器部分的畫面生成合成幀來輸出,每個網頁的Render Process渲染進程會對頁面內容生成合成幀來輸出,最終的結果都被共享給GPU ProcessGPU進程進行聚合併生成最終完整的合成表面,接着在Display Compositor環節將最後的位圖展示在屏幕上。
膠片里並沒有描述具體的光柵化的處理過程,但是layer輸出的quads看起來應該是光柵化以後的結果,推測應該是處理Display Item List中的繪圖指令時也和WebGL類似,經過頂點着色器和片元着色器的遍歷式處理機制,並在過程中自動完成像素插值。
聲明:本節內容是個人理解,僅用作技術交流,不保證對!
軟件渲染和硬件渲染的區別對筆者而言一直非常抽象,只是知道基本概念。後來在(國內可能無法訪問)中《Compositor Thread Architecture》這篇合成器線程架構的文章中找到了一些相關描述,也解開了筆者心中一直以來的疑惑,相關部分摘抄如下:
Texture Upload
One challenge with all these textures is that we rasterize them on the main thread of the renderer process, but need to actually get them into the GPU memory. This requires handing information about these textures (and their contents) to the impl thread, then to the GPU process, and once there, into the GL/D3D driver. Done naively, this causes us to copy a single texture over and over again, something we definitely don’t want to do.
We have two tricks that we use right now to make this a bit faster. To understand them, an aside on “painting” versus “rasterization.”
- Painting is the word we use for telling webkit to dump a part of its RenderObject tree to a GraphicsContext. We can pass the painting routine a GraphicsContext implementation that executes the commands as it receives them, or we can pass it a recording context that simply writes down the commands as it receives them.
- Rasterization is the word we use for actually executing graphics context commands. We typically execute the rasterization commands with the CPU (software rendering) but could also execute them directly with the GPU using Ganesh.
- Upload: this is us actually taking the contents of a rasterized bitmap in main memory and sending it to the GPU as a texture.With these definitions in mind, we deal with texture upload with the following tricks:
- Per-tile painting: we pass WebKit paint a recording context that simply records the GraphicsContext operations into an SkPicture data structure. We can then rasterize several texture tiles from that one picture.
- SHM upload: instead of rasterizing into a void* from the renderer heap, we allocate a shared memory buffer and upload into that instead. The GPU process then issues its glTex* operations using that shared memory, avoiding one texture copy.The holy grail of texture upload is “zero copy” upload. With such a scheme, we manage to get a raw pointer inside the renderer process’ sandbox to GPU memory, which we software-rasterize directly into. We can’t yet do this anywhere, but it is something we fantasize about.
大概翻譯一下,方便英語水平一般的小夥伴理解,GPU處理圖片的方式是按照Texture進行貼圖的,對此不熟悉的小夥伴可以查看筆者以前發的有關Three.js相關的博文。
紋理上傳:
處理紋理的挑戰之一就是它是在渲染進程(可以理解為單個Tab網頁的進程)的主線程里進行的,但是最終需要將其放入GPU內存。這就需要將紋理數據遞交給合成器線程,然後再交給GPU進程(Chromium架構里有專門的GPU進程用來專門處理和GPU之間的協作任務),最後再傳遞給底層的Direct3D或OpenGL(也就是圖形學的底層技術),如果只是按照常規流程來處理,就會需要一次又一次來複制生成的紋理數據,這顯然不是我們想要的。
我們現在使用了兩個小方法來使這個流程變得快一點。它們分別作用於painting(繪製)和rasterization(光柵化)兩個階段。
- 1號知識點!!!
Painting我們用來告訴webkit為RenderObject Tree的來生成對應的GraphicsContext。通過給painting routine(繪製流程)傳遞一個GraphicsContext的具體實現來執行這些已經編排好的繪製命令,也可以傳遞一個record context(記錄上下文)只是簡單地把繪圖命令都記錄下來。- 2號知識點!!!
Rasterization(光柵化)是指Graphics context關聯的繪圖命令實際被執行的過程。通常我們使用CPU(也就是軟件渲染的方式)來執行光柵化任務,也可以直接使用GPU來渲染(也就是硬件渲染的方式)。- 上傳:指在主線程存儲區獲取到光柵化以後的位圖內容然後將它作為紋理上傳給GPU的過程,考慮到上述已經提及的定義,上傳過程是如下來處理的:
- 瓦片繪製:我們在webkit中使用
recording context來簡單地記錄Graphics Context的操作指令,將它存儲為SkPicture類型(直接使用軟件光柵化時生成的是SkBitmap類型),隨後可以從一張picture裏面光柵化處理得到多個紋理瓦片。- 共享內存:在軟件渲染的方式中,光柵化的結果會被存儲在
renderer進程的堆內存里,現在不這樣搞了,我們重新分配了一塊共享緩衝區,然後通過它來傳遞相關對象,GPU進程隨後在獲取紋理時直接從共享內存中獲取就行了,這樣就避免了數據的拷貝。
總的來說,紋理上傳的過程幾乎是零拷貝的。利用這樣的結構,我們在renderer進程(也就是網頁的渲染進程)的沙箱環境內也可以獲取到指向GPU 內存的指針,而在軟件光柵化的過程中,是直接將位圖結果放在這裏的。
- Painting: this is the process of asking Layers for their content. This is where we ask webkit to tell us what is on a layer. We might then rasterize that content into a bitmap using software, or we might do something fancier. Painting is a main thread operation.
- Drawing: this is the process of taking the layer tree and smashing it together with OpenGL onto the screen. Drawing is an impl-thread operation.
- painting:表示的過程是向Layers對象查詢層內容,也就是讓webkit告訴我們每一層上面到底有什麼。接下來我們就可以使用軟件光柵化的方式將這些內容處理為位圖,也可以做一些更牛的事情,painting是一個主線程行為。
- drawing:是指將Layer中的內容用OpenGL繪製在屏幕上的過程,它是另一個線程中的操作。
概念比較多沒有基礎的讀者可能理解起來有難度,我嘗試用自己的話複述一下:
【軟件渲染】的模式下,在paint時會直接利用Graphics Context繪圖上下文將結果繪製出來,在一個SkBitmap實例中保存為位圖信息;【硬件渲染】的模式下,在paint時傳入一個SkPicture實例,將需要執行的繪圖命令保存在裏面先不執行,然後通過共享內存將它傳給GPU進程,藉助GPU來最終去執行繪圖命令,生成多個瓦片化的位圖紋理結果(OpenGL中頂點着色器向片元着色器傳遞數據時可以自動進行數據插值,完成光柵化的任務)。 純軟件渲染里嚴格說是沒有合成層概念的,因為最終輸出的只有一張位圖,按照順序從下往上畫,和畫到一個新層上再把新層貼到已有結果上其實是一樣的。
不管使用哪種途徑,paint動作都是得到位圖數據,而最終的draw這個動作是藉助OpenGL和位圖數據最終把圖形显示在显示器上。
所以【硬件渲染】就是渲染進程把要做的事情和需要的數據都寫好,然後打包遞給GPU讓它去幹活。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
 |
日本松下(Panasonic)、中國北京汽車宣布將共同投資數百億日圓,於中國天津成立合資公司,用於生產純電動車之核心零組件,搶攻中國龐大的電動車市場商機。
《日本經濟新聞》中文版、日本《共同社》等多家媒體報導,松下社長津賀一宏日前曾前往中國,與北汽公司商討成立合資公司一事,並達成協議。北汽旗下兩家汽車零組件廠商將出資54%、松下的中國公司則出資46%,合資公司計畫在2018年左右開始投入量產,主要產品是電動車空調的電動壓縮機,供貨對象則是北汽公司與其他公司。
電動車的空調電力來自蓄電池。為優化電動車的行駛里程,電動車空調壓縮機須能以更好的效率控制冷、暖風,因此性能需求較一般汽油車高。性能佳的空調壓縮機,將有助提高電動車的續航力。
中國市場蓬勃,松下積極搶進
在政府的大力推動下,中國已在2015年成為全球最大電動車市場之一。《日經》指出,日廠豐田決定在2018年起於中國生產插電式混和動力車(PHEV);而松下與北汽的合作,則象徵松下在中國市場的在地化布局行動。未來預計還會有更多日商在中國展開本土化生產。
松下已宣布退出電視面板製造事業,並轉而提高在住宅、汽車等兩大領域的業務著力。2015財年,松下所生產的車載導航儀與車載電池等零組件銷售額達1.3兆日圓。松下表示,到2018年度時,希望上述零組件銷售額能進一步提高到2兆日圓。
松下在電動車、鋰電池方面的海外投資,包括與美商特斯拉(Tesla)合作在美國內華達州建立的鋰電池工廠Gigafactory,以及中國大連建立的車用鋰電池工廠。大連工廠預計在2017年正式投產。
北汽成立於1953年,為國有企業。在電動車、PHEV領域,北汽是中國僅次於比亞迪(BYD)的第二大業者。北汽計畫到2020年時生產40萬輛電動車。
(照片來源:Wikipedia)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
Java鎖的問題,可以說是每個JavaCoder繞不開的一道坎。如果只是粗淺地了解Synchronized等鎖的簡單應用,那麼就沒什麼談的了,也不建議繼續閱讀下去。如果希望非常詳細地了解非常底層的信息,如monitor源碼剖析,SpinLock,TicketLock,CLHLock等自旋鎖的實現,也不建議看下去,因為本文也沒有說得那麼深入。本文只是按照synchronized這條主線,探討一下Java的鎖實現,如對象頭部,markdown,monitor的主要組成,以及不同鎖之間的轉換。至於常用的ReentrantLock,ReadWriteLock等,我將在之後專門寫一篇AQS主線的Java鎖分析。
不是我不想解釋得更為詳細,更為底層,而是因為兩個方面。一方面正常開發中真的用不到那麼深入的原理。另一方面,而是那些非常深入的資料,比較難以收集,整理。當然啦,等到我的Java積累更加深厚了,也許可以試試。囧
由於Java鎖的內容比較雜,劃分的維度也是十分多樣,所以很是糾結文章的結構。經過一番考慮,還是採用類似正常學習,推演的一種邏輯來寫(涉及到一些複雜的新概念時,再詳細描述)。希望大家喜歡。
如果讓我談一下對程序中鎖的最原始認識,那我就得說說PV操作(詳見我在系統架構師中系統內部原理的筆記)了。通過PV操作可以實現同步效果,以及互斥鎖等。
如果讓我談一下對Java程序中最常見的鎖的認識,那無疑就是Synchronized了。
那麼Java鎖是什麼?網上許多博客都談到了偏向鎖,自旋鎖等定義,唯獨就是沒人去談Java鎖的定義。我也不能很好定義它,因為Java鎖隨着近些年的不斷擴展,其概念早就比原來膨脹了許多。硬要我說,Java鎖就是在多線程情況下,通過特定機制(如CAS),特定對象(如Monitor),配合LockRecord等,實現線程間資源獨佔,流程同步等效果。
當然這個定義並不完美,但也算差不多說出了我目前對鎖的認識(貌似這不叫定義,不要計較)。
其實這裏面有很多有意思的東西,如自旋鎖的特性,大家都可以根據CAS的實現了解到了。Java的自選鎖在JDK4的時候就引入了(但當時需要手動開啟),並在JDK1.6變為默認開啟,更重要的是,在JDK1.6中Java引入了自適應自旋鎖(簡單說就是自旋鎖的自旋次數不再固定)。又比如自旋鎖一般都是樂觀鎖,獨享鎖是悲觀所的子集等等。
** Java鎖還可以按照底層實現分為兩種。一種是由JVM提供支持的Synchronized鎖,另一種是JDK提供的以AQS為實現基礎的JUC工具,如ReentrantLock,ReadWriteLock,以及CountDownLatch,Semaphore,CyclicBarrier等。**
Synchronized應該是大家最早接觸到的Java鎖,也是大家一開始用得最多的鎖。畢竟它功能多樣,能力又強,又能滿足常規開發的需求。
有了上面的概念鋪墊,就很好定義Synchronized了。Synchronized是悲觀鎖,獨享鎖,可重入鎖。
當然Synchronized有多種使用方式,如同步代碼塊(類鎖),同步代碼塊(對象鎖),同步非靜態方法,同步靜態方法四種。後面有機會,我會掛上我筆記的相關頁面。但是總結一下,其實很簡單,注意區分鎖的持有者與鎖的目標就可以了。static就是針對類(即所有對該類的實例對象)。
其次,Synchronized不僅實現同步,並且JMM中規定,Synchronized要保證可見性(詳細參照筆記中對volatile可見性的剖析)。
然後Synchronized有鎖優化:鎖消除,鎖粗化(JDK做了鎖粗化的優化,但可以通過代碼層面優化,可提高代碼的可讀性與優雅性)
另外,Synchronized確實很方便,很簡單,但是也希望大家不要濫用,看起來很糟糕,而且也讓後來者很難下叉。
終於到了重頭戲,也到了最消耗腦力的部分了。這裏要說明一點,這裏提及的只是常見的鎖的原理,並不是所有鎖原理展示(如Synchronized展示的是對象鎖,而不是類鎖,網上也基本沒有博客詳細寫類鎖的實現原理,但不代表沒有)。如Synchronized方法是通過ACC_SYNCHRONIZED進行隱式同步的。
首先,我們需要正常對象在內存中的結構,才可以繼續深入研究。
JVM運行時數據區分為線程共享部分(MetaSpace,堆),線程私有部分(程序計數器,虛擬機棧,本地方法棧)。這部分不清楚的,自行百度或查看我之前有關JVM的筆記。那麼堆空間存放的就是數組與類對象。而MetaSpace(原方法區/持久代)主要用於存儲類的信息,方法數據,方法代碼等。
我知道,沒有圖,你們是不會看的。
PS:為了偷懶,我放的都是網絡圖片,如果掛了。嗯,你們就自己百度吧
PS2:如果使用的網絡圖片存在侵權問題,請聯繫我,抱歉。
第一張圖,簡單地表述了在JVM中堆,棧,方法區三者之間的關係
我來說明一下,我們代碼中類的信息是保存在方法區中,方法區保存了類信息,如類型信息,字段信息,方法信息,方法表等。簡單說,方法區是用來保存類的相關信息的。詳見下圖:
而堆,用於保存類實例出來的對象。
以hotspot的JVM實現為例,對象在對內存中的數據分為三個部分:
簡單說明一下,對齊填充的問題,可以理解為系統內存管理中頁式內存管理的內存碎片。畢竟內存都是要求整整齊齊,便於管理的。如果還不能理解,舉個栗子,正常人規劃自己一天的活動,往往是以小時,乃至分鐘劃分的時間塊,而不會劃分到秒,乃至微妙。所以為了便於內存管理,那些零頭內存就直接填充好了,就像你制定一天的計劃, 晚上睡眠的時間可能總是差幾分鐘那樣。如果你還是不能理解,你可以查閱操作系統的內存管理相關知識(各類內存管理的概念,如頁式,段式,段頁式等)。
如果你原先對JVM有一定認識,卻理解不深的話,可能就有點迷糊了。
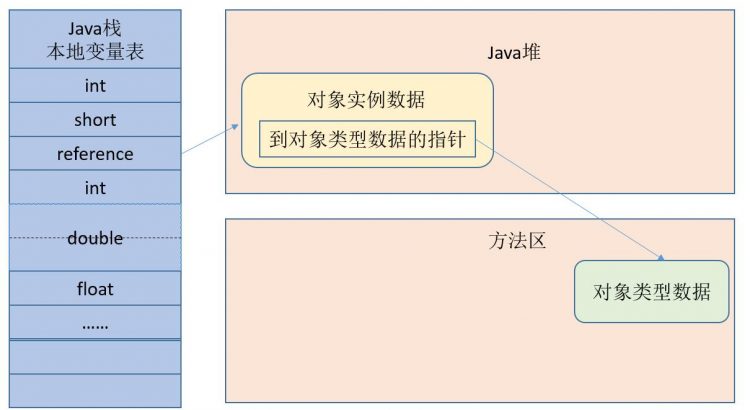
Java對象中的實例數據部分存儲對象的實際數據,什麼是對象的實際數據?這些數據與虛擬機棧中的局部變量表中的數據又有什麼區別?
且聽我給你編,啊呸,我給你說明。為了便於理解,插入圖片
Java對象中所謂的實際數據就是屬於對象中的各個變量(屬於對象的各個變量不包括函數方法中的變量,具體後面會談到)。這裡有兩點需要注意:
針對第二點,我舉個實際例子。
如StudentManager對象中有Student stu = new Student(“ming”);,那麼在內存中是存在兩個對象的:StudentManger實例對象,Student實例對象(其傳入構造方法的參數為”ming”)。而在StudentManager實例對象中有一個Student類型的stu引用變量,其值指向了剛才說的Student實例對象(其傳入構造方法的參數為”ming”)。那麼再深入一些,為什麼StudentManager實例對象中的stu引用變量要強調是Student類型的,因為JVM要在堆中為StudentManager實例對象分配明確大小的內存啊,所以JVM要知道實例對象中各個引用變量需要分配的內存大小。那麼stu引用變量是如何指向Student實例對象(其傳入構造方法的參數為”ming”)的?這個問題的答案涉及到句柄的概念,這裏簡單立即為指針指向即可。
數組是如何確定內存大小的。
那麼數組在內存中的表現是怎樣的呢?其實和之前的思路還是一樣的。引用變量指向實際值。
二維數組的話,第一層數組中保存的是一維數組的引用變量。其實如果學習過C語言,並且學得還行的話,這些概念都很好理解的。
關於對象中的變量與函數方法中的變量區別及緣由:眾所周知,Java有對內存與棧內存,兩者都有着保存數據的職責。堆的優勢可以動態分配內存大小,也正由於動態性,所以速度較慢。而棧由於其特殊的數據結構-棧,所以速度較快。一般而言,對象中的變量的生命周期比對象中函數方法的變量的生命周期更長(至少前者不少於後者)。當然還有一些別的原因,最終對象中的變量保存在堆中,而函數方法的變量放在棧中。
補充一下,Java的內存分配策略分為靜態存儲,棧式存儲,堆式存儲。后兩者本文都有提到,說一下靜態存儲。靜態存儲就是編譯時確定每個數據目標在運行時的存儲需求,保存在堆內對應對象中。
針對虛擬機棧(本地方法不在此討論),簡單說明一下(因為後面用得到)。
先上個圖
虛擬機棧屬於JVM中線程私有的部分,即每個線程都有屬於自己的虛擬機棧(Stack)。而虛擬機棧是由一個個虛擬機棧幀組成的,虛擬機棧幀(Stack Frame)可以理解為一次方法調用的整體邏輯流程(Java方法執行的內存模型)。而虛擬機棧是由局部變量表(Local Variable Table),操作棧(Operand Stack),動態連接(Dynamic Linking),返回地址(Reture Address)等組成。簡單說明一下,局部變量表就是用於保存方法的局部變量(生命周期與方法一致。注意基本數據類型與對象的不同,如果是對象,則該局部變量為一個引用變量,指向堆內存中對應對象),操作棧用於實現各種加減乘除的操作等(如iadd,iload等),動態鏈接(這個解釋比較麻煩,詳見《深入理解Java虛擬機》p243),返回地址(用於在退出棧幀時,恢復上層棧幀的執行狀態。說白了就是A方法中調用B方法,B方法執行結束后,如何確保回到A方法調用B方法的位置與狀態,畢竟一個線程就一個虛擬機棧)。
到了這一步,就滿足了接下來學習的基本要求了。如果希望有更為深入的理解,可以坐等我之後有關JVM的博客,或者查看我的相關筆記,或者查詢相關資料(如百度,《深入理解Java虛擬機》等。
說了這麼多,JVM是如何支持Java鎖呢?
前面Java對象的部分,我們提到了對象是由對象頭,實例數據,對齊填充三個部分組成。其中后兩者已經進行了較為充分的說明,而對象頭還沒有進行任何解釋,而鎖的實現就要靠對象頭完成。
對象頭由兩到三個部分組成:
后兩者不是重點,也與本次主題無關,不再贅述。讓我們來細究一下Mark Word的具體數據結構,及其在內存中的表現。
來,上圖。
一般第一次看看這個圖,都有點蒙,什麼玩意兒啊,到底怎麼理解啊。
所以這個時候需要我來給你舉個簡單例子。
如一個對象頭是這樣的:AAA..(一共23個A)..AAA BB CCCC D EE 。其中23個A表示線程ID,2位B表示Epoch,4位C表示對象的分代年齡,1位D表示該對象的鎖是否為偏向鎖,2位E表示鎖標誌位。
至於其它可能嘛。看到大佬已經寫了一個,情況說明得挺好的,就拿來主義了。
圖中展現了對象在無鎖,偏向鎖,輕量級鎖,重量級鎖,GC標記五種狀態下的Mark Word的不同。
| biased_lock | lock | 狀態 |
|---|---|---|
| 0 | 01 | 無鎖 |
| 1 | 01 | 偏向鎖 |
| 0 | 00 | 輕量級鎖 |
| 0 | 10 | 重量級鎖 |
| 0 | 11 | GC標記 |
引用一下這位大佬的哈(畢竟大佬解釋得蠻全面的,我就不手打了,只做補充)。
可能你看到這裏,會對上面的解釋產生一定的疑惑,什麼是棧中鎖記錄,什麼是Monitor。別急,接下來的Synchronized鎖的實現就會應用到這些東西。
現在就讓我們來看看我們平時使用的Java鎖在JVM中到底是怎樣的情況。
Synchronized鎖一共有四種狀態:無鎖,偏向鎖,輕量級鎖,重量級鎖。其中偏向鎖與輕量級鎖是由Java6提出,以優化Synchronized性能的(具體實現方式,後續可以看一下,有區別的)。
在此之前,我要簡單申明一個定義,首先鎖競爭的資源,我們稱為“臨界資源”(如:Synchronized(this)中指向的this對象)。而競爭鎖的線程,我們稱為鎖的競爭者,獲得鎖的線程,我們稱為鎖的持有者。
就是對象不持有任何鎖。其對象頭中的mark word是
| 含義 | identity_hashcode | age | biased_lock | lock | |
|---|---|---|---|---|---|
| 示例 | aaa…(25位bit) | xxxx(4位bit) | 0(1位bit ,具體值:0) | 01(2位bit ,具體值:01) |
無鎖狀態沒什麼太多說的。
這裏簡單說一下identity_hashcode的含義,25bit位的對象hash標識碼,用於標識這是堆中哪個對象的對象頭。具體會在後面的鎖中應用到。
那麼這個時候一個線程嘗試獲取該對象鎖,會怎樣呢?
如果一個線程獲得了鎖,即鎖直接成為了鎖的持有者,那麼鎖(其實就是臨界資源對象)就進入了偏向模式,此時Mark Word的結果就會進入之前展示的偏向鎖結構。
那麼當該線程進再次請求該鎖時,無需再做任何同步操作(不需要再像第一次獲得該鎖那樣,進行較為複雜的操作),即獲取鎖的過程只需要檢查Mark Word的鎖標記位位偏向鎖並且當前線程ID等於Mark Word的ThreadID即可,從而節省大量有關鎖申請的操作。
看得有點懵,沒關係,我會好好詳細解釋的。此處有關偏向鎖的內存變化過程就兩個,一個是第一次獲得鎖的過程,一個是後續獲得該鎖的過程。
接下來,我會結合圖片,來詳細闡述這兩個過程的。
當一個線程通過Synchronized鎖,出於需求,對共享資源進行獨佔操作時,就得試圖向別的鎖的競爭者宣誓鎖的所有權。但是,此時由於該鎖是第一次被佔用,也不確定是否後面還有別的線程需要佔有它(大多數情況下,鎖不存在多線程競爭情況,總是由同一線程多次獲得該鎖),所以不會立馬進入資源消耗較大的重量鎖,輕量級鎖,而是選擇資源佔用最少的偏向鎖。為了向後面可能存在的鎖競爭者線程證明該共享資源已被佔用,該臨界資源的Mark Word就會做出相應變化,標記該臨界資源已被佔用。具體Mark Word會變成如下形式:
| 含義 | thread | epoll | age | biased_lock | lock |
|---|---|---|---|---|---|
| 示例 | aaa…(23位bit) | bb(2位bit) | xxxx(4位bit) | 1(1位bit ,具體值:1) | 01(2位bit ,具體值:01) |
這裏我來說明一下其中各個字段的具體含義:
接下來就是第二個過程:鎖的競爭者線程嘗試獲得鎖,那麼鎖的競爭者線程會檢測臨界資源,或者說鎖對象的mark word。如果是無鎖狀態,參照上一個過程。如果是偏向鎖狀態,就檢測其thread是否為當前線程(鎖的競爭者線程)的線程ID。如果是當前線程的線程ID,就會直接獲得臨界資源,不需要再次進行同步操作(即上一個過程提到的CAS操作)。
還看不懂,再引入一位大佬的:
偏向鎖的加鎖過程:
訪問Mark Word中偏向鎖的標識是否設置成1,鎖標誌位是否為01,確認為可偏向狀態。
如果為可偏向狀態,則測試線程ID是否指向當前線程,如果是,進入步驟5,否則進入步驟3。
如果線程ID並未指向當前線程,則通過CAS操作競爭鎖。如果競爭成功,則將Mark Word中線程ID設置為當前線程ID,然後執行5;如果競爭失敗,執行4。
如果CAS獲取偏向鎖失敗,則表示有競爭。當到達全局安全點(safepoint)時獲得偏向鎖的線程被掛起,偏向鎖升級為輕量級鎖,然後被阻塞在安全點的線程繼續往下執行同步代碼。(撤銷偏向鎖的時候會導致stop the word)
執行同步代碼。
PS:safepoint(沒有任何字節碼正在執行的時候):詳見JVM GC相關,其會導致stop the world。
偏向鎖的存在,極大降低了Syncronized在多數情況下的性能消耗。另外,偏向鎖的持有線程運行完同步代碼塊后,不會解除偏向鎖(即鎖對象的Mark Word結構不會發生變化,其threadID也不會發生變化)
那麼,如果偏向鎖狀態的mark word中的thread不是當前線程(鎖的競爭者線程)的線程ID呢?
輕量級鎖可能是由偏向鎖升級而來的,也可能是由無鎖狀態直接升級而來(如通過JVM參數關閉了偏向鎖)。
偏向鎖運行在一個線程進入同步塊的情況下,而當第二個線程加入鎖競爭時,偏向鎖就會升級輕量級鎖。
如果JVM關閉了偏向鎖,那麼在一個線程進入同步塊時,鎖對象就會直接變為輕量級鎖(即鎖對象的Mark Word為偏向鎖結構)。
上面的解釋非常簡單,或者說粗糙,實際的判定方式更為複雜。我在查閱資料時,發現網上很多博客根本沒有深入說明偏向鎖升級輕量級鎖的深層邏輯,直到看到一篇寫出了以下的說明:
當線程1訪問代碼塊並獲取鎖對象時,會在java對象頭和棧幀中記錄偏向的鎖的threadID,因為偏向鎖不會主動釋放鎖,因此以後線程1再次獲取鎖的時候,需要比較當前線程的threadID和Java對象頭中的threadID是否一致,如果一致(還是線程1獲取鎖對象),則無需使用CAS來加鎖、解鎖;如果不一致(其他線程,如線程2要競爭鎖對象,而偏向鎖不會主動釋放因此還是存儲的線程1的threadID),那麼需要查看Java對象頭中記錄的線程1是否存活,如果沒有存活,那麼鎖對象被重置為無鎖狀態,其它線程(線程2)可以競爭將其設置為偏向鎖;如果存活,那麼立刻查找該線程(線程1)的棧幀信息,如果還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖,如果線程1 不再使用該鎖對象,那麼將鎖對象狀態設為無鎖狀態,重新偏向新的線程。
這段說明的前半截,我已經在偏向鎖部分說過了。我來說明一下其後半截有關鎖升級的部分。
如果當前線程(鎖的競爭者線程)的線程ID與鎖對象的mark word的thread不一致(其他線程,如線程2要競爭鎖對象,而偏向鎖不會主動釋放因此還是存儲的線程1的threadID),那麼需要查看Java對象頭中記錄的線程1是否存活(可以直接根據鎖對象的Mark Word(更準確說是Displaced Mark Word)的thread來判斷線程1是否還存活),如果沒有存活,那麼鎖對象被重置為無鎖狀態,從而其它線程(線程2)可以競爭該鎖,並將其設置為偏向鎖(等於無鎖狀態下,重新偏向鎖的競爭);如果存活,那麼立刻查找該線程(線程1)的棧幀信息,如果線程1還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖,如果線程1 不再使用該鎖對象,那麼將鎖對象狀態設為無鎖狀態,重新偏向新的線程。(這個地方其實是比較複雜的,如果有不清楚的,可以@我。)
那麼另一個由無鎖狀態升級為輕量級鎖的內存過程,就是:
首先讓我來說明一下上面提到的“如果線程1還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖”涉及的三個問題。
第一個問題,如果不暫停線程1,即線程1的虛擬機棧還在運行,那麼就有可能影響到相關的Lock Record,從而導致異常發生。
第二個問題與第三個問題其實是一個問題,就是通過修改Mark Word的鎖標誌位(lock)與偏向鎖標誌(biased_lock)。將Mark Word修改為下面形式:
| 含義 | thread | epoll | age | biased_lock | lock |
|---|---|---|---|---|---|
| 示例 | aaa…(23位bit) | bb(2位bit) | xxxx(4位bit) | 1(1位bit ,具體值:1) | 01(2位bit ,具體值:01) |
在代碼進入同步塊的時候,如果鎖對象的mark word狀態為無鎖狀態,JVM首先將在當前線程的棧幀)中建立一個名為鎖記錄(Lock Record)的空間,用於存儲Displaced Mark Word(即鎖對象目前的Mark Word的拷貝)。
有資料稱:Displaced Mark Word並不等於Mark Word的拷貝,而是Mark Word的前30bit(32位系統),即Hashcode+age+biased_lock,不包含lock位。但是目前我只從網易微專業課聽到這點,而其它我看到的任何博客都沒有提到這點。所以如果有誰有確切資料,希望告知我。謝謝。
鎖的競爭者嘗試獲取鎖時,會先拷貝鎖對象的對象頭中的Mark Word複製到Lock Record,作為Displaced Mark Word。然後就是之前加鎖過程中提到到的,JVM會通過CAS操作將鎖對象的Mark Word更新為指向Lock Record的指針(這與之前提到的修改thread的CAS操作毫無關係,就是修改鎖對象的引用變量Mark Word的指向,直接指向鎖的競爭者線程的Lock Record的Displaced Mark Word)。CAS成功后,將Lock Record中的owner指針指向鎖對象的Mark Word。而這就表示鎖的競爭者嘗試獲得鎖成功,成為鎖的持有者。
而這之後,就是修改鎖的持有者線程的Lock Record的Displaced Mark Word。將Displaced Mark Word的前25bit(原identity_hashcode字段)修改為當前線程(鎖的競爭者線程)的線程ID(即Mark word的偏向鎖結構中的thread)與當前epoll時間戳(即獲得偏向鎖的epoll時間戳),修改偏向鎖標誌位(從0變為1)。
聽得有點暈暈乎乎,來,給你展示之前那位大佬的(另外我還增加了一些註釋):
輕量級鎖的加鎖過程(無鎖升級偏向鎖):
在代碼進入同步塊的時候,如果同步對象鎖狀態為無鎖狀態(鎖標誌位為“01”狀態,是否為偏向鎖為“0”),虛擬機首先將在當前線程的棧幀(即同步塊進入的地方,這個需要大家理解基於棧的編程的思想)中建立一個名為鎖記錄(Lock Record)的空間,用於存儲 Displaced Mark Word(鎖對象目前的Mark Word的拷貝)。這時候線程堆棧與對象頭的狀態如圖:
(上圖中的Object就是鎖對象。)
拷貝對象頭中的Mark Word複製到鎖記錄中,作為Displaced Mark Word;
拷貝成功后,JVM會通過CAS操作(舊值為Displaced Mark Word,新值為Lock Record Adderss,即當前線程的鎖對象地址)將鎖對象的Mark Word更新為指向Lock Record的指針(就是修改鎖對象的引用變量Mark Word的指向,直接指向鎖的競爭者線程的Lock Record的Displaced Mark Word),並將Lock record里的owner指針指向鎖對象的Mark Word。如果更新成功,則執行步驟4,否則執行步驟5。
如果這個更新動作成功了,那麼這個線程就擁有了該對象的鎖,並且對象Mark Word的鎖標誌位設置為“00”,即表示此對象處於輕量級鎖定狀態,這時候線程堆棧與對象頭的狀態如圖所示。
(上圖中的Object就是鎖對象。)
如果這個更新操作失敗了,虛擬機首先會檢查對象的Mark Word是否指向當前線程的棧幀,如果是就說明當前線程已經擁有了這個對象的鎖,那就可以直接進入同步塊繼續執行(這點是Synchronized為可重入鎖的佐證,起碼說明在輕量級鎖狀態下,Synchronized鎖為可重入鎖。)。否則說明多個線程競爭鎖,輕量級鎖就要膨脹為重量級鎖(其實是CAS自旋失敗一定次數后,才進行鎖升級),鎖標誌的狀態值變為“10”,Mark Word中存儲的就是指向重量級鎖(互斥量)的指針,後面等待鎖的線程也要進入阻塞狀態。 而當前線程便嘗試使用自旋來獲取鎖,自旋就是為了不讓線程阻塞,而採用循環去獲取鎖的過程。
適用的場景為線程交替執行同步塊的場景。
那麼輕量級鎖在什麼情況下會升級為重量級鎖呢?
重量級鎖是由輕量級鎖升級而來的。那麼升級的方式有兩個。
第一,線程1與線程2拷貝了鎖對象的Mark Word,然後通過CAS搶鎖,其中一個線程(如線程1)搶鎖成功,另一個線程只有不斷自旋,等待線程1釋放鎖。自旋達到一定次數(即等待時間較長)后,輕量級鎖將會升級為重量級鎖。
第二,如果線程1拷貝了鎖對象的Mark Word,並通過CAS將鎖對象的Mark Word修改為了線程1的Lock Record Adderss。這時候線程2過來后,將無法直接進行Mark Word的拷貝工作,那麼輕量級鎖將會升級為重量級鎖。
無論是同步方法,還是同步代碼塊,無論是ACC_SYNCHRONIZED(類的同步指令,可通過javap反彙編查看)還是monitorenter,monitorexit(這兩個用於實現同步代碼塊)都是基於Monitor實現的。
所以,要想繼續在JVM層次學習重量級鎖,我們需要先學習一些概念,如Monitor。
這裏貼上作者的一頁筆記,幫助大家更好理解(主要圖片展示效果,比文字好)。
(請不要在意字跡問題,以後一定改正)
說白了,Java的Monitor,就是JVM(如Hotspot)為每個對象建立的一個類似對象的實現,用於支持Monitor實現(實現了Monitor同步原語的各種功能)。
上面這張圖的下半部分,揭示了JVM(Hotspot)如何實現Monitor的,通過一個objectMonitor.cpp實現的。該cpp具有count,owner,WaitSet,EntryList等參數,還有monitorenter,monitorexit等方法。
看到這裏,大家應該對Monitor不陌生了。一般說的Monitor,指兩樣東西:Monitor同步原語(類似協議,或者接口,規定了這個同步原語是如何實現同步功能的);Monitor實現(類似接口實現,協議落地代碼等,就是具體實現功能的代碼,如objectMonitor.cpp就是Hotspot的Monitor同步原語的落地實現)。兩者的關係就是Java中接口和接口實現。
那麼monitor是如何實現重量級鎖的呢?其實JVM通過Monitor實現Synchronized與JDK通過AQS實現ReentrantLock有異曲同工之妙。只不過JDK為了實現更好的功能擴展,從而搞了一個AQS,使得ReentrantLock看起來非常複雜而已,後續會開一個專門的系列,寫AQS的。這裏繼續Monitor的分析。
從之前的objectMonitor.cpp的圖中,可以看出:
這個部分的代碼邏輯不需要太過深入理解,只需要清楚明白關鍵參數的意義,以及大致流程即可。
有關具體重量級鎖的底層ObjectMonitor源碼解析,我就不再贅述,因為有一位大佬給出(我覺得挺好的,再深入就該去看源碼了)。
如果真的希望清楚了解代碼運行流程,又覺得看源碼太過麻煩。可以查看我之後寫的有關JUC下AQS對ReentrantLock的簡化實現。看懂了那個,你會發現Monitor實現Synchronized的套路也就那樣了(我自己就是這麼過來的)。
看完前面一部分的人,可能對如何實現Monitor,Monitor如何實現Synchronized已經很了解了。但是,Monitor如何與持有鎖的線程產生關係呢?或者進一步問,之前提到的objectWaiter是個什麼東西?
來,上圖片。
從圖中,可以清楚地看到,ObjectWaiter * _next與ObjectWaiter * _prev(volatile就不翻譯,文章前面有),說明ObjectWaiter對象是一個雙向鏈表結構。其中通過Thread* _thread來表示當前線程(即競爭鎖的線程),通過TStates TState表示當前線程狀態。這樣一來,每個等待鎖的線程都會被封裝成OjbectWaiter對象,便於管理線程(這樣一看,就和ReentrantLock更像了。ReentrantLock通過AQS的Node來封裝等待鎖的線程)。
最後就是,無鎖,偏向鎖,輕量級鎖,重量級鎖之間的轉換了。
啥都別說了,上圖。
這個圖,基本就說了七七八八了。我就不再深入闡述了。
注意一點,輕量級鎖降級,不會降級為偏向鎖,而是直接降級為無鎖狀態。
重量級鎖,就不用我說了。要麼上鎖,要麼沒有鎖。
鎖的優化,包括自旋鎖,自適應自旋鎖,鎖消除,鎖粗化。
JIT(Just In Time)編譯時,對運行上下文進行掃描,去除不可能存在競爭的鎖。
JIT(Hotspot Code):
通過擴大加鎖的範圍,避免反覆加鎖和解鎖。
刨除代碼,這篇文章在已發表的文章中,應該是我花的時間最長,手打內容最多的文章了。
從開始編寫,到編寫完成,前前後后,橫跨兩個月。當然主要也是因為這段時間太忙了,沒空進行博客的編寫。
在編寫這篇博客的過程中,我自己也收穫很多,將許多原先自己認為自己懂的內容糾正了出來,也將自己對JVM的認識深度,再推進一層。
最後,願與諸君共進步。
《深入理解Java虛擬機》
:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
摘錄自2020年1月2日聯合報德國報導
德國警方表示,一間動物園的猿猴館在跨年夜發生大火,導致30多隻動物死亡,懷疑是天燈惹的禍。
德新社報導,這場大火燒毀克雷菲爾德動物園(Krefeld Zoo)的猿猴館,約30多隻動物命喪火窟,包括黑猩猩、紅毛猩猩、兩隻年長大猩猩,只有兩隻黑猩猩獲救。火災也導致狐蝠和鳥類死亡。
克雷菲爾德動物園距離杜塞道夫約15公里,1日和2日不對外開放。警方懷疑可能是跨年夜當晚,有人放天燈才導致大火,並在該地區發現一些類似的天燈。
調查人員霍普曼(Gerd Hoppmann)說,天燈相當危險,可能會飛行超過一公里。另外,也呼籲在該地區放天燈的人自首。
德國之聲報導,天燈導致幾起死亡火災後,德國北萊茵-西發利亞邦2009年起禁止放天燈。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
美國豪華電動車製造商特斯拉 (Tesla) 電動運動休旅車 Model X 本季正式在美國發表後,預計 2016 年上半年就會進軍中國。 特斯拉北京分部發言人 Gary Tao 在接受專訪時透露了上述訊息,還宣稱特斯拉今年底前要在中國加開 5 至 6 個全新展示間,預計展示車輛的據點有望增加至 15 處,展示新車的位置會在北京、上海、廣州等重點城市。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!

本文由葡萄城技術團隊於博客園翻譯並首發
轉載請註明出處:,葡萄城為開發者提供專業的開發工具、解決方案和服務,賦能開發者。
JavaScript最初是為Web應用程序創建的。但是隨着前端技術的發展,大多數開發人員更喜歡使用基於JavaScript的框架。它簡化了你的代碼以及使你能完成更多全棧工作,您幾乎可以在任何框架中使用JavaScript。
使用什麼類型的框架決定了創建應用程序的便捷程度。因此,您必須慎重選擇。在已經足夠複雜的前端環境里,其中兩個框架脫穎而出。我們會在本文中對Ember.js和Vue.js之間進行對比,以幫助你更好的做出判斷。
在開始比較這兩個框架之前,我們應該先來了解下選擇一個框架的決定因素都有什麼。每個開發人員選擇一個框架之前,讓我們看看選擇的理由。
開發人員總是在尋找新的框架來構建他們的應用程序。主要要求是速度快、成本低。這個框架應該很容易被新開發人員理解並且能夠以更低的成本使用。其他考慮選項還有簡單的編碼方式、健全的幫助文檔等。
在Web應用程序開發中,VUEJS在軟件語言方面結合了很多優點。VUE.JS的體繫結構易於使用。使用VUE.JS開發的應用程序很容易與新的應用程序集成。
VUE.JS是一個非常輕量級的框架。你能很快的下載到它。它也比其他框架快得多。該框架的單文件組件性質也很棒。這個尺寸使它很受歡迎。
同時你可以進一步減少它的體積。使用Vue.js可以將模板和編譯器分離為虛擬DOM。您只能部署只有12 KB的壓縮后的壓縮解釋器。您可以在您的機器中編譯模板。
Vue.js的另一個重要優點是它可以輕鬆地與使用JavaScript創建的現有應用程序集成。使用此框架可以輕鬆地對已經存在的應用程序進行更改。
Vue.js還可輕鬆與其他前端庫集成。您可以插入另一個庫,以彌補此框架中的任何不足。此功能使該工具成為通用工具。
Vue.js使用服務器端渲染流的方法。它使服務器具有較高的響應速度。 你的用戶將很快獲得渲染的內容。
Vue.js非常適合SEO。由於該框架支持服務器端渲染,因此視圖直接在服務器上渲染。便於搜索引擎直接索引到這些網頁內容。
但對你來說最重要的是你可以輕鬆地學習Vue.js。該結構是基本的。即使是新的開發人員,也會發現使用它來構建應用程序很容易。該框架有助於開發大型和小型模板。它有助於節省大量時間。
您可以返回並輕鬆檢查錯誤。除了測試組件外,您還可以返回並檢查所有狀態。就任何開發人員而言,這是另一個重要功能。
Vue.js也有非常詳細的文檔。它有助於為你快速上手開發應用程序。您可以使用HTML或JavaScript的基本知識來構建網頁或應用。
Ember.js是MVVM模型框架。它是開源軟件。該平台主要用於創建複雜的多頁面應用程序。它保持最新的特性,並不會丟棄任何舊功能。
通過這個框架,您必須嚴格遵循框架的體繫結構。JS框架是非常嚴密的組織。所以它降低了和其他框架可能提供的靈活性。
它的平台和工具有非常完善的控制系統。您可以使用提供的工具將其與新版本集成,以避免使用過時的API。
您可以輕鬆了解Ember的API。他們也很容易工作。您可以簡單,直接地使用高度複雜的功能。
當類似的工作一起處理時,性能更好。它創建了相似的綁定和DOM更新,讓瀏覽器一次性處理它們,以提高性能。這樣則將避免為每個工作重複計算,以免浪費大量時間。
因為Promise無處不在,所以你可以以簡單的方式編寫代碼和模塊,使用 Ember 的任何 API。
同時Ember也有一個很不錯的上手指南。上面記錄著API的使用方式。Ember明確了一般應用程序的組織和結構,因此你將不會犯任何錯誤。你將不可能在不必要的情況下使程序複雜化。Ember的模板語言是Handlebar,Handlebar簡潔的語法可以使你可以輕鬆閱讀和理解模板,同樣的也能使頁面加載速度變得更快。使用Handlebar另一個優勢是,不必每次在頁面上添加或刪除數據時都更新模板。語言本身將自動為你完成。
最後,Ember.js擁有一個活躍的社區,可以定期更新框架並從而促進向後兼容
當你需要將原有應用程序向現代框架上遷移時,Vue.js可以為您提供幫助。它結合了其他框架的許多優點。Vue.js面向開發過程的框架,所以沒有提供現成的界面元素庫。但是,許多第三方社區庫可以為您提供幫助。
Ember.js為您提供了一個值得信賴的成熟框架。當你的開發團隊規模很大時,這個框架比較合適。由於MVVM結構所致,它使每個人都可以為項目做出貢獻。
Vue.js可以幫助你兼容應用程序中不同類型的語法,它有助於輕鬆編寫代碼,同時由於後端渲染,它也是一個對SEO友好的框架。而Ember是一個完全加載的前端框架,可以幫助您非常快速地開發應用程序。但是它不適合開發小型項目。
很難說誰比誰更具優勢。選擇哪個框架將取決於你實際參与的項目類型是什麼。兩者都有其優缺點,所以我為大家總結了一張表,也許它能幫助你更好地進行對比:
選擇什麼,取決於您要開發的應用程序。這兩個框架都在發展中。兩者也都在更新。
雖然Ember是一個全棧框架,但它太複雜了,很難應用於較小的項目。而Vue.js憑藉著輕盈的體量,易於上手的特點,使開發應用程序變得異常高效,從而獲得了不少行業的開發者的青睞。
此外,無論選擇什麼類型的框架,葡萄城都為廣大開發者提供了兼容各類框架的開發組件,例如:和 ,為開發者賦能。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
摘錄自2020年1月6日中央社河內報導
越南電力集團(EVN)4日與寮國供電業者簽署5項購電合同,預計2021年起將從寮國進口數十億度電,希望解決國內缺電隱憂。
越南近年來經濟發展迅速,現今隨著美中貿易戰而掀起外商轉向越南投資的浪潮,加上經濟發展依賴能源密集的製造業,使境內電力需求量日益增加。
越南正面臨兩項潛在的能源危機。一是發電能量不足,二是中國對越南鑽探離岸石油及天然氣的動作強力施壓。
越南工商部表示,2021年起越南恐將嚴重缺電,因為建設新電廠的速率趕不上電力需求增長。缺電可能使外資卻步,對從美中貿易戰受惠最多的越南形成不小隱憂,電力需求將於2021年超出供給,因為許多越南能源計畫延宕而使2021至2025年間缺電情況最嚴重,每年缺口可達70億至80億度或千瓦小時(kWh)。
「民智報」網站6日報導,越南電力集團與寮國Phongsubthavy和Chealun Sekong兩家供電集團簽署電力銷售合同,向由這2家集團運作的5個水力發電廠購買電力,其中寮國2號南空水力發電廠(Nam Kong 2)自2021年開始每年向越南出口2.631億度,其餘4個發電廠2022年起每年向越南輸送2.04億至4.2774億度。
越南2019年電力需求量為2400億度,與2018年同期相較,增加8.9%;預計今年電力需求量增至2620億度。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!

 宣稱性能可媲美特斯拉的台灣品牌純電動車,由昶洧設計製造的 Thunder Power 品牌,即將現身今年德國法蘭克福車展。 自許在研發「四輪電腦」的昶洧,純電動車選定在今年德國法蘭克福車展曝光,展出車款 5-passenger RWD sedan 的設計,是以「Timeless『Zen』,Simple、Concise、Flexible but Sharp」永恆禪風、極簡、精煉、靈活敏銳為核心精神。 昶洧電動車除 Zagato 負責造型設計及擬具整車開發計畫的評估報告外,還與歐洲、BOSCH、Dallara、CSI 等名車設計工程公司,進行技術開發,共同打造。 昶洧表示,原型車目前已可達到只需充電 30 分鐘即可行駛 200 公里以上,充飽電至少可行駛 700 公里,及車身平台及模組化平台的概念,未來一系列車型包括轎車、運動休旅車(SUV)、跨界休旅車(Crossover)、中小型房車(Compact)都可共用車身平台。
宣稱性能可媲美特斯拉的台灣品牌純電動車,由昶洧設計製造的 Thunder Power 品牌,即將現身今年德國法蘭克福車展。 自許在研發「四輪電腦」的昶洧,純電動車選定在今年德國法蘭克福車展曝光,展出車款 5-passenger RWD sedan 的設計,是以「Timeless『Zen』,Simple、Concise、Flexible but Sharp」永恆禪風、極簡、精煉、靈活敏銳為核心精神。 昶洧電動車除 Zagato 負責造型設計及擬具整車開發計畫的評估報告外,還與歐洲、BOSCH、Dallara、CSI 等名車設計工程公司,進行技術開發,共同打造。 昶洧表示,原型車目前已可達到只需充電 30 分鐘即可行駛 200 公里以上,充飽電至少可行駛 700 公里,及車身平台及模組化平台的概念,未來一系列車型包括轎車、運動休旅車(SUV)、跨界休旅車(Crossover)、中小型房車(Compact)都可共用車身平台。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!