環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
摘錄自2018年8月10日中央社報導
法國政府為遏止蜜蜂持續大量死亡,公告自9月1日起禁用五種含類尼古丁的農藥。
法國於2016年實施生物多樣性法規,當時就決定要禁用含類尼古丁(neonicotinoid)的殺蟲劑,這種物質會破壞昆蟲的神經系統,導致蜜蜂等花粉媒介昆蟲迷路及死亡,威脅到生物多樣性和糧食生產。
法國這一波禁用的五種殺蟲劑包括益達胺(imidacloprid)、可尼丁(clothianidin)、賽速安(Thiamethoxam)、賽果培(Thiacloprid)和亞滅培(Acetamiprid)。
法國政府對這類殺蟲劑的禁令比歐盟嚴格。費加洛報(Le Figaro)報導,法國生態部表示,國會正在審議糧食法草案,通過後,應可再增加禁用類尼古丁殺蟲劑的種類。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
摘錄自2018年8月10日中央社報導
聯邦第九巡迴上訴法院今天(10日)裁決,美國環境保護署(EPA)須在60天內下令禁用陶斯松(chlorpyrifos)。批評人士指出,這種廣泛使用的農藥會傷害兒童和農民。
第九巡迴上訴法院以2票贊成、1票反對的裁決結果,推翻前環保署長普魯特(Scott Pruitt)2017年3月拒絕接受環保團體請願的決定。當時環保團體呼籲,禁止陶斯松用於水果、蔬菜和堅果等糧食作物。
代表第九巡迴上訴法院撰寫裁決書的法官拉柯夫(Jed Rakoff)指出,「科學證據顯示,殘留在糧食上(的陶斯松)會對兒童神經發育造成損害」,但環保署未能提出有力反駁,因此下令環保署須在60天內下令禁用陶斯松。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
俗話說的好工欲善其事必先利其器,Git分佈式版本控制系統是我們日常開發中不可或缺的。目前市面上比較流行的Git可視化管理工具有SourceTree、Github Desktop、TortoiseGit,綜合網上的一些文章分析和自己的日常開發實踐心得個人比較推薦開發者使用SourceTree,因為SourceTree同時支持Windows和Mac,並且界面十分的精美簡潔,大大的簡化了開發者與代碼庫之間的Git操作方式。該篇文章主要是對日常開發中使用SourceTree可視化管理工具的一些常用操作進行詳細講解。
https://blog.csdn.net/hmllittlekoi/article/details/104504406/
https://www.cnblogs.com/Can-daydayup/p/13128511.html
注意:這裏介紹的是使用SSH協議獲取關聯遠程倉庫的代碼,大家也可以直接使用過HTTPS協議的方式直接輸入賬號密碼獲取關聯代碼!
https://www.cnblogs.com/Can-daydayup/p/13063280.html
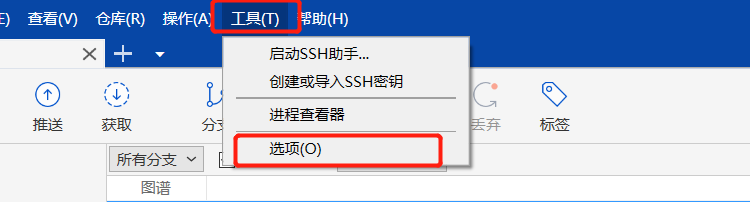
工具=>選擇:
添加SSH密鑰位置:C:\Users\xxxxx\.ssh\id_rsa.pub:
SSH客戶端選擇OpenSSH:
打開碼雲,找到自己需要Clone的倉庫!
由上面我們可以發現每次Clone克隆項目的時候,克隆下來的項目默認存儲位置都是在C盤,因此每次都需要我們去選擇項目存放的路徑,作為一個喜歡偷懶的人而言當然不喜歡這種方式啦,因此我們可以設置一個默認的項目存儲位置。
點擊工具=>選項=>一般=>找到項目目錄設置Clone項目默認存儲的位置
注意:多人同時開發項目的時候,不推薦默認選中立即推送變更到origin/develop,避免一些不必要的麻煩!
勾選需要推送的分支,點擊推送到遠程分支:
代碼成功推送到遠程代碼庫:
雙擊切換: 單擊鼠標右鍵切換:
注意:在新建分支時,我們需要在哪個主分支的基礎上新建分支必須先要切換到對應的主分支才能到該主分支上創建分支,如下我們要在master分支上創建一個feature-0613分支:
注意:在合併代碼之前我們都需要將需要合併的分支拉取到最新狀態(**避免覆蓋別人的代碼,或者丟失一些重要文件)!!!!! 在master分支上點擊右鍵,選擇合併feature-0613至當前分支即可進行合併: 分支合併成功:
在SoureceTree中在Clone一個新項目,命名為pingrixuexilianxi2,如下圖所示:
我們以項目中的【代碼合併衝突測試.txt】文件為例: 在pingrixuexilianxi2中添加內容,並提交到遠程代碼庫,添加的內容如下: 在pingrixuexilianxi中添加內容,提交代碼(不選擇立即推送變更到origin/master),拉取代碼即會遇到衝突:
衝突文件中的內容:
由下面的衝突文件中的衝突內容我們了解到:
<<<<<<< HEAD 6月19日 pingrixuexilianxi添加了內容 ======= 6月18日 pingrixuexilianxi2修改了這個文件哦 >>>>>>> a8284fd41903c54212d1105a6feb6c57292e07b5
<<<<<<< HEAD到 =======裏面的【6月19日 pingrixuexilianxi添加了內容】是自己剛才的Commit提交的內容 =======到 >>>>>>> a8284fd41903c54212d1105a6feb6c57292e07b5裏面的【6月18日 pingrixuexilianxi2修改了這個文件哦】是遠程代碼庫更新的內容(即為pingrixuexilianxi2本地代碼庫推送修改內容)。 手動衝突解決方法:
根據項目需求刪除不需要的代碼就行了,假如都需要的話我們只需要把 <<<<<<< HEAD======= >>>>>>> a8284fd41903c54212d1105a6feb6c57292e07b5都刪掉衝突就解決了(注意,在項目中最後這些符號都不能存在,否則可能會報異常)。
最後將衝突文件標記為已解決,提交到遠程倉庫:
工具=>選項=>比較:
Beyond Compare使用技巧: 官方全面教程: https://www.beyondcompare.cc/jiqiao/ SourceTree打開外部和合併工具:
注意:第一次啟動Beynod Compare軟件需要一會時間,請耐心等待:
Beynod Compare進行衝突合併: 點擊保存文件后關閉Beynod Compare工具,SourceTree中的衝突就解決了,在SourceTree中我們會發現多了一個 .orig 的文件。接着選中那個.orig文件,單擊右鍵 => 移除,最後我們推送到遠程代碼庫即可:
克隆/新建(clone):從遠程倉庫URL加載創建一個與遠程倉庫一樣的本地倉庫。 提交(commit):將暫存區文件上傳到本地代碼倉庫。
推送(push):將本地倉庫同步至遠程倉庫,一般推送(push)前先拉取(pull)一次,確保一致(十分注意:這樣你才能達到和別人最新代碼同步的狀態,同時也能夠規避很多不必要的問題)。 拉取(pull):從遠程倉庫獲取信息並同步至本地倉庫,並且自動執行合併(merge)操作(git pull=git fetch+git merge)。 獲取(fetch):從遠程倉庫獲取信息並同步至本地倉庫。 分支(branch):創建/修改/刪除分枝。 合併(merge):將多個同名文件合併為一個文件,該文件包含多個同名文件的所有內容,相同內容抵消。 貯藏(git stash):保存工作現場。 丟棄(Discard):丟棄更改,恢復文件改動/重置所有改動,即將已暫存的文件丟回未暫存的文件。 標籤(tag):給項目增添標籤。 工作流(Git Flow):團隊工作時,每個人創建屬於自己的分枝(branch),確定無誤后提交到master分支。 終端(terminal):可以輸入git命令行。 每次拉取和推送的時候不用每次輸入密碼的命令行:git config credential.helper osxkeychain sourcetree。 檢出(checkout):切換不同分支。 添加(add):添加文件到緩存區。 移除(remove):移除文件至緩存區。 重置(reset):回到最近添加(add)/提交(commit)狀態。
當然作為一個有逼格的程序員, 一些常用的命令我們還是需要了解和掌握的,詳情可參考我之前寫過的文章:
https://www.cnblogs.com/Can-daydayup/p/10134733.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
目錄
JVM的參數有很多很多,根據我的統計JDK8中JVM的參數總共有1853個,正式的參數也有680個。
這麼多參數帶給我們的是對JVM的細粒度的控制,但是並不是所有的參數都需要我們自己去調節的,我們需要關注的是一些最常用的,對性能影響比較大的GC參數即可。
為了更好的讓大家理解JDK8中 GC的調優的秘籍,這裏特意準備了八張圖。在本文的最後,還附帶了一個總結的PDF all in one文檔,大家把PDF下載回去,遇到問題就看兩眼,不美嗎?
為了更好的提升GC的效率,現代的JVM都是採用的分代垃圾回收的策略(ZGC不是)。
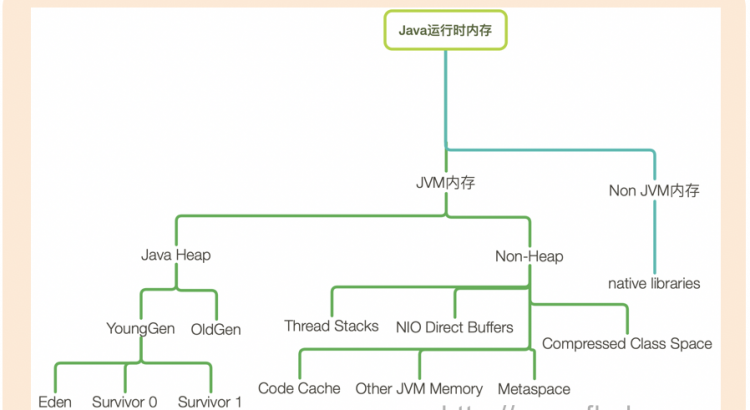
java運行時內存可以分為JVM內存和非JVM內存。
JVM內存又可以分為堆內存和非堆內存。
堆內存大家都很熟悉了,YoungGen中的Eden,Survivor和OldGen。
非堆內存中存儲的有thread Stack,Code Cache, NIO Direct Buffers,Metaspace等。
注意這裏的Metaspace元空間是方法區在JDK8的實現,它是在本地內存中分配的。
JDK8中到底有哪些可以使用的GC呢?
這裏我們以HotSpot JVM為例,總共可以使用4大GC方式:
其中對於ParallelGC和CMS GC又可以對年輕代和老年代分別設置GC方式。
大家看到上圖可能有一個疑問,Parallel scavenge和Parallel有什麼區別呢?
其實這兩個GC的算法是類似的,Parallel Scavenge收集器也經常稱為“吞吐量優先”收集器,Parallel Scavenge收集器提供了兩個參數用於精確控制吞吐量; -XX:MaxGCPauseMillis:控制最大垃圾收集停頓時間; -XX:GCTimeRatio:設置吞吐量大小。
同時Parallel Scavenge收集器能夠配合自適應調節策略,把內存管理的調優任務交給虛擬機去完成。
JDK8中默認開啟的是ParallelGC。
如果想研究和理解GC的內部信息,GC信息打印是少不了的:
上圖提供了一些非常有用的GC日誌的控制參數。
JVM分為Heap區和非Heap區,各個區又有更細的劃分,下面就是調整各個區域大小的參數:
TLAB大家還記得嗎?TLAB的全稱是Thread-Local Allocation Buffers。TLAB是在Eden區間分配的一個一個的連續空間。然後將這些連續的空間分配個各個線程使用。
因為每一個線程都有自己的獨立空間,所以這裏不涉及到同步的概念。
上圖就是TLAB的參數。
雖然JDK8的GC這麼多,但是他們有一些通用的GC參數:
這裏講解一下Young space tenuring,怎麼翻譯我不是很清楚,這個主要就是指Young space中的對象經過多少次GC之後會被提升到Old space中。
CMS全稱是Concurrent mark sweep。是一個非常非常複雜的GC。
複雜到什麼程度呢?光光是CMS調優的參數都有一百多個!
下圖是常用的CMS的參數。
CMS這裏就不多講了,因為在JDK9之後,CMS就已經被廢棄了。
主要原因是CMS太過複雜,如果要向下兼容需要巨大的工作量,然後就直接被廢棄了。
在JDK9之後,默認的GC是G1。
G1收集器是分代的和region化的,也就是整個堆內存被分為一系列大小相等的region。在啟動時,JVM設置region的大小,根據堆大小的不同,region的大小可以在1MB到32MB之間變動,region的數量最多不超過2048個。Eden區、Survivor區、老年代是這些region的邏輯集合,它們並不是連續的。
G1中的垃圾收集過程:年輕代收集和混合收集交替進行,背後有全局的併發標記周期在進行。當老年代分區佔用的空間達到或超過初始閾值,就會觸發併發標記周期。
下圖是G1的調優參數:
上面總共8副圖,我把他們做成了一個PDF,預覽界面大概是這樣子的:
大家可以通過下面的鏈接直接下載PDF版本:
JDK8GC-cheatsheet.pdf
如果遇到問題可以直接拿過來參考。這種東西英文名字應該叫JDK8 GC cheatsheet,翻譯成中文應該就是JDK8 GC調優秘籍!
本文作者:flydean程序那些事
本文鏈接:http://www.flydean.com/jdk8-gc-cheatsheet/
本文來源:flydean的博客
歡迎關注我的公眾號:程序那些事,更多精彩等着您!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心
上一篇介紹的 6 個特性從園子里的反饋來看效果不錯,那這一篇就再帶來 6 個特性同大家一起欣賞。
大家都知道弱類型的語言有很多,如: nodejs,python,php,它們有一個的地方就是處理json,不需要像 強類型語言 那樣還要給它配一個類,什麼意思呢? 就拿下面的 json 說事。
{
"DisplayName": "新一代算法模型",
"CustomerType": 1,
"Report": {
"TotalCustomerCount": 1000,
"TotalTradeCount": 50
},
"CustomerIDHash": [1,2,3,4,5]
}
這個 json 如果想灌到 C# 中處理,你就得給它定義一個適配的類,就如 初篇 的客戶算法模型類,所以這裏就有了一個需求,能不能不定義類也可以自由解析上面這串 json 呢??? 哈哈,當然是可以的, 反序列化成 Dictionary 即可,就拿提取 Report.TotalCustomerCount 和 CustomerIDHash 這兩個字段演示一下。
static void Main(string[] args)
{
var json = @"{
'DisplayName': '新一代算法模型',
'CustomerType': 1,
'Report': {
'TotalCustomerCount': 1000,
'TotalTradeCount': 50
},
'CustomerIDHash': [1,2,3,4,5]
}";
var dict = JsonConvert.DeserializeObject<Dictionary<object, object>>(json);
var report = dict["Report"] as JObject;
var totalCustomerCount = report["TotalCustomerCount"];
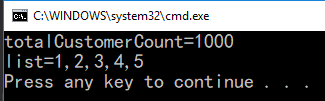
Console.WriteLine($"totalCustomerCount={totalCustomerCount}");
var arr = dict["CustomerIDHash"] as JArray;
var list = arr.Select(m => m.Value<int>()).ToList();
Console.WriteLine($"list={string.Join(",", list)}");
}
這句話是什麼意思呢? 默認情況下, SerializeObject 會將 Model 中的 Enum 變成數值型,大家都知道數值型語義性是非常差的,如下代碼所示:
static void Main(string[] args)
{
var model = new ThreadModel() { ThreadStateEnum = System.Threading.ThreadState.Running };
var json = JsonConvert.SerializeObject(model);
Console.WriteLine(json);
}
class ThreadModel
{
public System.Threading.ThreadState ThreadStateEnum { get; set; }
}
對吧,確實語義特別差,那能不能直接生成 Running 這種字符串形式呢? 當然可以了。。。改造如下:
var json = JsonConvert.SerializeObject(model, new StringEnumConverter());
這裏可能就有人鑽牛角尖了,能不能部分指定讓枚舉生成 string,其他的生成 int ,沒關係,這也難不倒我,哪裡使用就用 JsonConverter 標記哪裡。。。
static void Main(string[] args)
{
var model = new ThreadModel()
{
ThreadStateEnum = System.Threading.ThreadState.Running,
TaskStatusEnum = TaskStatus.RanToCompletion
};
var json = JsonConvert.SerializeObject(model);
Console.WriteLine(json);
}
class ThreadModel
{
public System.Threading.ThreadState ThreadStateEnum { get; set; }
[JsonConverter(typeof(StringEnumConverter))]
public TaskStatus TaskStatusEnum { get; set; }
}
在 model 轉化成 json 的過程中,總少不了 時間類型,為了讓時間類型 可讀性更高,通常會 格式化為 YYYY年/MM月/dd日 ,那如何實現呢? 很簡單撒,在 JsonConvert 中也是一個 枚舉 幫你搞定。。。
static void Main(string[] args)
{
var json = JsonConvert.SerializeObject(new Order()
{
OrderTitle = "女裝大佬",
Created = DateTime.Now
}, new JsonSerializerSettings
{
DateFormatString = "yyyy年/MM月/dd日",
});
Console.WriteLine(json);
}
public class Order
{
public string OrderTitle { get; set; }
public DateTime Created { get; set; }
}
對了,我記得很早的時候,C# 自帶了一個 JavaScriptSerializer, 也是用來進行 model 轉 json的,但是它會將 datetime 轉成 時間戳,而不是時間字符串形式,如果你因為特殊原因想通過 JsonConvert 將時間生成時間戳的話,也是可以的, 用 DateFormatHandling.MicrosoftDateFormat 枚舉指定一下即可,如下:
在之前所有演示的特性技巧中都是在 JsonConvert 上指定的,也就是說 100 個 JsonConvert 我就要指定 100 次,那有沒有類似一次指定,整個進程通用呢? 這麼強大的 Newtonsoft 早就支持啦, 就拿上面的 Order 舉例:
JsonConvert.DefaultSettings = () =>
{
var settings = new JsonSerializerSettings
{
Formatting = Formatting.Indented
};
return settings;
};
var order = new Order() { OrderTitle = "女裝大佬", Created = DateTime.Now };
var json1 = JsonConvert.SerializeObject(order);
var json2 = JsonConvert.SerializeObject(order);
Console.WriteLine(json1);
Console.WriteLine(json2);
可以看到,Formatting.Indented 對兩串 json 都生效了。
有時候我們有這樣的需求,一旦 json 中出現 model 未知的字段,有兩種選擇: 要麼報錯,要麼提取出未知字段,在 Newtonsoft 中默認的情況是忽略,場景大家可以自己找哈。
static void Main(string[] args)
{
var json = "{'OrderTitle':'女裝大佬', 'Created':'2020/6/23','Memo':'訂單備註'}";
var order = JsonConvert.DeserializeObject<Order>(json, new JsonSerializerSettings
{
MissingMemberHandling = MissingMemberHandling.Error
});
Console.WriteLine(order);
}
public class Order
{
public string OrderTitle { get; set; }
public DateTime Created { get; set; }
public override string ToString()
{
return $"OrderTitle={OrderTitle}, Created={Created}";
}
}
我依稀的記得 WCF 在這種場景下也是使用一個 ExtenstionDataObject 來存儲客戶端傳過來的未知字段,有可能是客戶端的 model 已更新,server端還是舊版本,通常在 json 序列化中也會遇到這種情況,這裏只要使用 JsonExtensionData 特性就可以幫你搞定,在 OnDeserialized 這種AOP方法中進行攔截,如下代碼:
static void Main(string[] args)
{
var json = "{'OrderTitle':'女裝大佬', 'Created':'2020/6/23','Memo':'訂單備註'}";
var order = JsonConvert.DeserializeObject<Order>(json);
Console.WriteLine(order);
}
public class Order
{
public string OrderTitle { get; set; }
public DateTime Created { get; set; }
[JsonExtensionData]
private IDictionary<string, JToken> _additionalData;
public Order()
{
_additionalData = new Dictionary<string, JToken>();
}
[OnDeserialized]
private void OnDeserialized(StreamingContext context)
{
var dict = _additionalData;
}
public override string ToString()
{
return $"OrderTitle={OrderTitle}, Created={Created}";
}
}
有時候在查閱源碼的時候開啟日誌功能更加有利於理解源碼的內部運作,所以這也是一個非常實用的功能,看看如何配置吧。
static void Main(string[] args)
{
var json = "{'OrderTitle':'女裝大佬', 'Created':'2020/6/23','Memo':'訂單備註'}";
MemoryTraceWriter traceWriter = new MemoryTraceWriter();
var account = JsonConvert.DeserializeObject<Order>(json, new JsonSerializerSettings
{
TraceWriter = traceWriter
});
Console.WriteLine(traceWriter.ToString());
}
public class Order
{
public string OrderTitle { get; set; }
public DateTime Created { get; set; }
public override string ToString()
{
return $"OrderTitle={OrderTitle}, Created={Created}";
}
}
嘿嘿,這篇 6 個特性就算說完了, 結合上一篇一共 12 個特性,是不是非常簡單且實用,後面準備給大家帶來一些源碼解讀吧! 希望本篇對您有幫助,謝謝!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
又到周末了,周更选手申請出站~
這次分享一下上個月碰到的離奇的問題。一個簡單的問題,硬是因為異常被悄咪咪吃掉,過關難度直線提升,導致小黑哥排查一個晚上。
這個美好的晚上,本想着開兩把 LOL 無限火力,在召喚師峽谷來個五殺的~
哎,就這樣沒了啊!我知道,你們一定能理解這種五殺被搶的感覺~
下次,真的,誰再讓我看到悄咪咪的吃掉異常,我真的要上去一 Jio 了!
好了,本文可不是水文,看完本篇文章,你可以學到以下知識點:
好了,同學們,打開小本子,準備記好知識點~
先贊后看養成習慣,微信搜索「程序通事」,關注就完事了
我們有個業務系統,應用之間調用鏈如下所示:
A 應用是業務發生起始應用,在這個應用中將會根據一定規則選擇最後的通訊渠道 C,然後將這個渠道標識傳遞給 B 應用。
B 應用的功能類似網關,這個應用將會根據 A 應用傳遞過來的渠道標識,將會請求路由下發到具體的 C 應用,起到服務路由的功能。
C 應用是與外部應用交互的應用,我們將其稱為渠道通訊機。
假設一次業務中,A 應用根據規則選擇 C2 的渠道標識,然後傳遞給 B 應用。B 應用根據這個標識選擇使用 C2 進行通訊,最後 C2 調用外部應用完成一次業務調用。
上述所有應用都基於 Dubbo 進行遠程通訊,B 應用實現原理在小黑哥之前文章「支付路由系統演進史」中有寫過,感興趣的同學可以查看一下。
介紹完業務的基本情況,現在我們來看下到底發生了啥事。
一次業務需求中,需要改動 C2 應用,這次改動功能點真的很小,很快就完成了。小黑哥想着閑着也是閑着,於是就把之前 C2 應用中打印的日誌中一些沒有脫敏的信息,進行脫敏處理。
由於之前日誌框架脫敏處理存在一些問題,於是就將日誌框架從 Log4j 升級為 LogBack。升級之後,為了防止不同日誌框架中之間的產生衝突,於是使用 IDEA Maven Helper 插件,統一將應用中所有的 Log4j 相關依賴都給排除了。
改動完成之後,將 C2 應用發布到測試環境,再次從 A 應用發起測試, B 應用返回異常提示未找到 C2 應用。
B 應用業務代碼類似如下:
public Response pay(Request req) {
try {
if (!isSupport(req.getChnlCode())) {
return new Response("ERROR", "未找到相關渠道應用");
}
return doPay(req);
} catch (Exception e) {
return new Response("ERROR", "未找到相關渠道應用");
}
}
正常情況下,若是配置存在問題,B 應用將會返回未找到具體渠道,請求也會在 B 應用結束,不會調用到 C2 應用(也沒辦法調用)。
然而此次配置什麼都沒問題, 而且最詭異的是 C2 應用居然收到了請求,並且成功處理了業務請求。
由於 B 應用異常處理時,將異常吃掉了,我們沒辦法得知這個過程到底發生了啥事,所以第一要緊的事獲取異常信息。
最簡單的辦法就是,將 B 應用改造一下,加入打印異常日誌。不過當時比較懶,不想改造應用,就想獲取異常信息,於是想到使用 Arthas。
Arthas 是Alibaba開源的Java診斷工具,這裏就不再詳細介紹這個工具,主要講下這次排錯用到的命令-watch。
watch 命令可以方便觀察指定方的調用情況,可以具體觀察方法的返回值、拋出異常、入參,另外還可以通過 OGNL表達式查看對應的變量。
這裏我們主要為了查看方法拋出的異常信息,執行命令如下:
watch com.dubbo.example.DemoService doPay -e -x 2 '{params,throwExp}'
上述命令將會在方法異常之後觀察方法的入參以及異常信息。
注意,我們需要查看
doPay方法,而不是pay方法。這是因為pay方法中我們將異常捕獲,不太可能會拋出異常哦~
異常信息如下所示:
真正引起此次錯誤的異常信息為:
java.lang.NoClassDefFoundError: Could not initialize class xx.xxx.xx.GELogger
由於此次 B 應用不存在改動,所以推測這個異常實際發生在 C2 應用,於是在 C2 應用處再次使用 Arthas watch 命令,同樣觀察到相同的錯誤信息。
NoClassDefFound,從名字上我們可以推測是因為類不存在,從而引發的這個錯誤。按照這個思路,我們首先可以簡單查看一下 B 應用中是否存在 GELogger 相關類。
查看 B 應用相關依賴包,從中發現了這個類文件,這說明這個類確實存在。
在 IDEA 反編譯查看 GELogger類相關源碼,從中發現了問題。
private static Logger logger;
static {
System.out.println("static init");
logger = Logger.getLogger(NoClassDefFoundErrorTestService.class);
System.out.println("Logger init success");
}
GELogger存在一個靜態代碼塊,用於初始化一個 org.apache.log4j.Logger日誌類。
然後在上面改動中,全部的 Log4j依賴都被排除了,所以這裏運行時應該會拋出另外一個找到 org.apache.log4j.Logger 錯誤。
執行以下代碼,模擬拋錯過程。
System.out.println("模擬第一次 Error");
try {
NoClassDefFoundErrorTestService noClassDefFoundErrorTestService=new NoClassDefFoundErrorTestService();
} catch (Throwable e) {
e.printStackTrace();
}
System.out.println("模擬第二次 Error");
try {
NoClassDefFoundErrorTestService noClassDefFoundErrorTestService=new NoClassDefFoundErrorTestService();
} catch (Throwable e) {
e.printStackTrace();
}
異常信息如下所示:
第一次創建 NoClassDefFoundErrorTestService實例時,Java 虛擬機讀取加載時,將會初始化靜態代碼塊時。由於 org.apache.log4j.Logger類不存在,靜態代碼塊執行異常,從而導致類加載失敗。
第二次再創建 NoClassDefFoundErrorTestService 實例時,Java 虛擬機不會再次讀取加載,所以直接返回了以下異常。
java.lang.NoClassDefFoundError: Could not initialize class com.dubbo.example.NoClassDefFoundErrorTestService
找到問題真正原因,解決辦法也很簡單,直接排除 GELogger 所在依賴包。
雖然問題到此解決了,但是這裏還有一個疑問,為何 C2 應用發生了異常,卻沒有相關錯誤日誌,並且 C2 業務邏輯也正常處理完成。
這就要說到 Dubbo 內部異常錯誤處理方式,上面 GELogger 其實作用在一個 Dubbo 自定義 Filter 中,用來記錄結果,模擬代碼如下:
@Activate(
group = {"provider", "consumer"}
)
public class ErrorFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
Result result = invoker.invoke(invocation);
NoClassDefFoundErrorTestService noClassDefFoundErrorTestService=new NoClassDefFoundErrorTestService();
// 處理業務邏輯
return result;
}
}
這個自定義 Filter 中首先執行 invoker 方法,這個方法將會調用真正的業務方法,這就是為什麼 C2 應用邏輯是正常處理完成。
業務方法處理完成之後,然後執行後續邏輯。由於 NoClassDefFoundErrorTestService將會拋出 Error,最終這個 Error,將會在 HeaderExchangeHandler#handleRequest 被捕獲,然後將會把相關異常信息返回給調用 Dubbo 消費者。
而在 Dubbo 消費者接受到服務提供者返回信息之後,將會在 DefaultFuture#doReceived轉化成 RemotingException。
而 RemotingException 最終將會在 FailoverClusterInvoker#doInvoke 轉換成 RpcException返回給業務代碼。
好了,說了這麼多,總結一下本文知識點
NoClassDefFoundError,類加載過程失敗,也會導致 NoClassDefFoundError。1、當Dubbo遇上Arthas:排查問題的實踐
2、java.lang.NoClassDefFoundError 的解決方法一例
3、noclassdeffounderror-could-not-initialize-class-error
歡迎關注我的公眾號:程序通事,獲得日常乾貨推送。如果您對我的專題內容感興趣,也可以關注我的博客:studyidea.cn
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
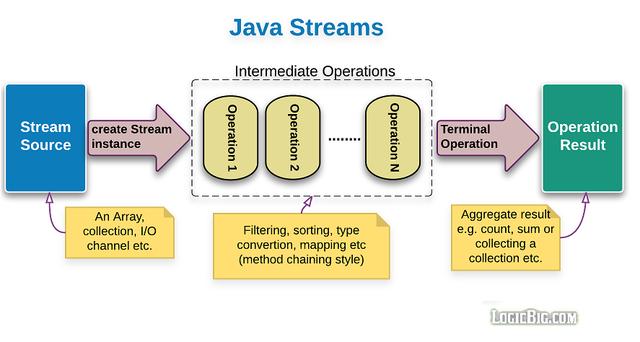
通過前面章節的學習,我們應該明白了Stream管道流的基本操作。我們來回顧一下:
看下面的腦圖,可以有更清晰的理解:
其實在程序員編程中,經常會接觸到“有狀態”,“無狀態”,絕大部分的人都比較蒙。而且在不同的場景下,“狀態”這個詞的含義似乎有所不同。但是“萬變不離其宗”,理解“狀態”這個詞在編程領域的含義,筆者教給大家幾個關鍵點:
是不是更蒙了?舉個例子,你就明白了
回到我們的Stream管道流
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.limit(2)
.collect(Collectors.toList());
List<String> skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.skip(2)
.collect(Collectors.toList());
我們還可以使用distinct方法對管道中的元素去重,涉及到去重就一定涉及到元素之間的比較,distinct方法時調用Object的equals方法進行對象的比較的,如果你有自己的比較規則,可以重寫equals方法。
List<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());
上面代碼去重之後的結果是: [“Monkey”, “Lion”, “Giraffe”, “Lemur”]
默認的情況下,sorted是按照字母的自然順序進行排序。如下代碼的排序結果是:[Giraffe, Lemur, Lion, Monkey],字數按順序G在L前面,L在M前面。第一位無法區分順序,就比較第二位字母。
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
排序我們後面還會給大家詳細的講一講,所以這裏暫時只做一個了解。
通常情況下,有狀態和無狀態操作不需要我們去關心。除非?:你使用了并行操作。
還是用班級按身高排隊為例:班級有一個人負責排序,這個排序結果最後就會是正確的。那如果有2個、3個人負責按大小個排隊呢?最後可能就亂套了。一個人只能保證自己排序的人的順序,他無法保證其他人的排隊順序。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
如果數據量比較小的情況下,不太能觀察到,數據量大的話,就能觀察到數據順序是無法保證的。
Monkey
Lion
Lemur
Giraffe
Lion
通常情況下,parallel()能夠很好的利用CPU的多核處理器,達到更好的執行效率和性能,建議使用。但是有些特殊的情況下,parallel並不適合:深入了解請看這篇文章:
https://blog.oio.de/2016/01/22/parallel-stream-processing-in-java-8-performance-of-sequential-vs-parallel-stream-processing/
該文章中幾個觀點,說明并行操作的適用場景:
覺得對您有幫助的話,幫我點贊、分享!您的支持是我不竭的創作動力! 。另外,筆者最近一段時間輸出了如下的精品內容,期待您的關注。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化

作者:HelloGitHub-小魚乾
摘要:如何優雅地誇一個程序員呢?vscode-rainbow-fart 作為一個彩虹屁的項目,深得程序員心,能在你編程時瘋狂稱讚你的除了你自己,還有它。除了鼓勵之外,Super Linte 是官方出品的旨在保證代碼和文檔一致性的工具,有了它,你可以更優雅地進行編程。說完優雅編程,來說下優雅使用 k8s,那就不得不提 Lens,一個專業管理 k8s 工具。
以下內容摘錄自微博@HelloGitHub 的 GitHub Trending,選項標準:新發布 | 實用 | 有趣,根據項目 release 時間分類,發布時間不超過 7 day 的項目會標註 New,無該標誌則說明項目 release 超過一周。由於本文篇幅有限,還有部分項目未能在本文展示,望周知
本周 star 增長數:3100+
GitHub Super Linter 是由 GitHub Services DevOps 工程團隊開源的提供給 Action 調用的存儲庫,目的是保持我們文檔和代碼的一致性,同時提升整個公司之間的交流和協作的效率。特性包括:
GitHub 地址→https://github.com/github/super-linter/
本周 star 增長數:1800+
Newvscode-rainbow-fart 是一個彩虹屁 VSCode 插件,在你編程時瘋狂稱讚你,可以根據代碼關鍵字播放貼近代碼意義的真人語音,誇你寫代碼牛逼。
GitHub 地址→https://github.com/SaekiRaku/vscode-rainbow-fart
本周 star 增長數:1850+
practical-python 是一個從事 Python 編程近三十年的工程師出的 Python 核心課程,它需要你 3、4 天的學習時間,大約 25-35 小時的時間,包括 130 多個項目實踐。
GitHub 地址→https://github.com/dabeaz-course/practical-python
本周 star 增長數:1500+
Newpulse 是一個可以將馬賽克圖片百年變成高清圖的工具,近日由杜克大學(Duke University)研究團隊開發了。作為一款 AI 修圖黑科技 PULSE,可以解決所有低像素煩惱。據說它能夠將圖像原始分辨率放大 64 倍,任何渣畫質都可以秒變高清、逼真圖像,甚至被打了馬賽克的人臉圖像,毛孔、皺紋,頭髮也都能被清晰還原。
GitHub 地址→https://github.com/adamian98/pulse
本周 star 增長數:2800+
Newalgorithm-pattern 是項目作者找工作時,從 0 開始刷 LeetCode 的心得記錄,通過各種刷題文章、專欄、視頻等總結的一套自己的刷題模板。
GitHub 地址→https://github.com/greyireland/algorithm-pattern
本周 star 增長數:10900+
python-small-examples 是一個告別枯燥,60 秒學會一個 Python 小例子的項目,目前庫已有 223 個實用的小例子 。
GitHub 地址→https://github.com/jackzhenguo/python-small-examples
本周 star 增長數:800+
Len 是一個開源、免費可用的 IDE,可方便管理 Kubernetes 的工具。
GitHub 地址→https://github.com/lensapp/lens
本周 star 增長數:600+
shapez.io 是一個受 Factorio 啟發的搭建遊戲。你要做的事情就是簡單地通過切割,旋轉,合併和繪製形狀的零件來產生形狀。
GitHub 地址→https://github.com/tobspr/shapez.io
本周 star 增長數:1800+
NewGoPlus 是數據科學的 Go+ 語言。
GitHub 地址→https://github.com/qiniu/goplus
在本期主題模塊,小魚乾這裏選取了 3 個和量化相關的小工具,希望能增加你的收入,養肥你的錢包。
vn.py 是一套基於 Python 的開源量化交易系統開發框架。
GitHub 地址→https://github.com/vnpy/vnpy
easytrader 是一個提供同花順客戶端/國金/華泰客戶端/雪球的基金、股票自動程序化交易以及自動打新,支持跟蹤 joinquant /ricequant 模擬交易和實盤雪球組合的量化交易組件。特性:
GitHub 地址→https://github.com/shidenggui/easytrader
stock 是作者作為業餘投機者(韭菜)一枚,自學量化交易,把經歷寫成代碼推送到 GitHub 的項目。
GitHub 地址→https://github.com/Rockyzsu/stock
以上為 2020 年第 23 個工作周的 GitHub Trending 如果你 Pick 其他好玩、實用的 GitHub 項目,記得來 HelloGitHub issue 區和我們分享下喲
HelloGitHub 交流群現已全面開放,添加微信號:HelloGitHub 為好友入群,可同前端、Java、Go 等各界大佬談笑風生、切磋技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※教你寫出一流的銷售文案?

在日常的網絡開發當中,協議解析都是必須的工作內容,Netty中雖然內置了基於長度、分隔符的編解碼器,但在大部分場景中我們使用的都是自定義協議,所以Netty提供了 MessageToByteEncoder<I> 與 ByteToMessageDecoder 兩個抽象類,通過繼承重寫其中的encode與decode方法實現私有協議的編解碼。這篇文章我們就對Netty中的自定義編解碼器進行實踐與分析。
下面是MessageToByteEncoder與ByteToMessageDecoder使用的簡單示例,其中不涉及具體的協議編解碼。
創建一個sever端服務
EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); final CodecHandler codecHandler = new CodecHandler(); try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).option(ChannelOption.SO_BACKLOG, 100) .handler(new LoggingHandler(LogLevel.INFO)).childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); if (sslCtx != null) { p.addLast(sslCtx.newHandler(ch.alloc())); } //添加編解碼handler p.addLast(new MessagePacketDecoder(),new MessagePacketEncoder()); //添加自定義handler p.addLast(codecHandler); } }); // Start the server. ChannelFuture f = b.bind(PORT).sync();
繼承MessageToByteEncoder並重寫encode方法,實現編碼功能
public class MessagePacketEncoder extends MessageToByteEncoder<byte[]> { @Override protected void encode(ChannelHandlerContext ctx, byte[] bytes, ByteBuf out) throws Exception { //進行具體的編碼處理 這裏對字節數組進行打印 System.out.println("編碼器收到數據:"+BytesUtils.toHexString(bytes)); //寫入並傳送數據 out.writeBytes(bytes); } }
繼承ByteToMessageDecoder 並重寫decode方法,實現解碼功能
public class MessagePacketDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out){ try { if (buffer.readableBytes() > 0) { // 待處理的消息包 byte[] bytesReady = new byte[buffer.readableBytes()]; buffer.readBytes(bytesReady); //進行具體的解碼處理 System.out.println("解碼器收到數據:"+ByteUtils.toHexString(bytesReady)); //這裏不做過多處理直接把收到的消息放入鏈表中,並向後傳遞 out.add(bytesReady); } }catch(Exception ex) { } } }
實現自定義的消息處理handler,到這裏其實你拿到的已經是編解碼后的數據
public class CodecHandler extends ChannelInboundHandlerAdapter{ @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println("CodecHandler收到數據:"+ByteUtils.toHexString((byte[])msg)); byte[] sendBytes = new byte[] {0x7E,0x01,0x02,0x7e}; ctx.write(sendBytes); } @Override public void channelReadComplete(ChannelHandlerContext ctx) { ctx.flush(); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { // Close the connection when an exception is raised. cause.printStackTrace(); ctx.close(); } }
運行一個客戶端模擬發送字節0x01,0x02,看一下輸出的執行結果
解碼器收到數據:0102 CodecHandler收到數據:0102 編碼器收到數據:7E01027E
根據輸出的結果可以看到消息的入站與出站會按照pipeline中自定義的順序傳遞,同時通過重寫encode與decode方法實現我們需要的具體協議編解碼操作。
通過上面的例子可以看到MessageToByteEncoder<I>與ByteToMessageDecoder分別繼承了ChannelInboundHandlerAdapter與ChannelOutboundHandlerAdapter,所以它們也是channelHandler的具體實現,並在創建sever時被添加到pipeline中, 同時為了方便我們使用,netty在這兩個抽象類中內置與封裝了一些其操作;消息的出站和入站會分別觸發write與channelRead事件方法,所以上面例子中我們重寫的encode與decode方法,也都是在父類的write與channelRead方法中被調用,下面我們就別從這兩個方法入手,對整個編解碼的流程進行梳理與分析。
1、MessageToByteEncoder
編碼需要操作的是出站數據,所以在MessageToByteEncoder的write方法中會調用我們重寫的encode具體實現, 把我們內部定義的消息實體編碼為最終要發送的字節流數據發送出去。
@Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { ByteBuf buf = null; try { if (acceptOutboundMessage(msg)) {//判斷傳入的msg與你定義的類型是否一致 @SuppressWarnings("unchecked") I cast = (I) msg;//轉為你定義的消息類型 buf = allocateBuffer(ctx, cast, preferDirect);//包裝成一個ByteBuf try { encode(ctx, cast, buf);//傳入聲明的ByteBuf,執行具體編碼操作 } finally { /** * 如果你定義的類型就是ByteBuf 這裏可以幫助你釋放資源,不需要在自己釋放 * 如果你定義的消息類型中包含ByteBuf,這裡是沒有作用,需要你自己主動釋放 */ ReferenceCountUtil.release(cast);//釋放你傳入的資源 } //發送buf if (buf.isReadable()) { ctx.write(buf, promise); } else { buf.release(); ctx.write(Unpooled.EMPTY_BUFFER, promise); } buf = null; } else { //類型不一致的話,就直接發送不再執行encode方法,所以這裏要注意如果你傳遞的消息與泛型類型不一致,其實是不會執行的 ctx.write(msg, promise); } } catch (EncoderException e) { throw e; } catch (Throwable e) { throw new EncoderException(e); } finally { if (buf != null) { buf.release();//釋放資源 } } }
MessageToByteEncoder的write方法要實現的功能還是比較簡單的,就是把你傳入的數據類型進行轉換和發送;這裡有兩點需要注意:
2、ByteToMessageDecoder
從命名上就可以看出ByteToMessageDecoder解碼器的作用是把字節流數據編碼轉換為我們需要的數據格式
作為入站事件,解碼操作的入口自然是channelRead方法
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { if (msg instanceof ByteBuf) {//如果消息是bytebuff CodecOutputList out = CodecOutputList.newInstance();//實例化一個鏈表 try { ByteBuf data = (ByteBuf) msg; first = cumulation == null; if (first) { cumulation = data; } else { cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data); } callDecode(ctx, cumulation, out);//開始解碼 } catch (DecoderException e) { throw e; } catch (Exception e) { throw new DecoderException(e); } finally { if (cumulation != null && !cumulation.isReadable()) {//不為空且沒有可讀數據,釋放資源 numReads = 0; cumulation.release(); cumulation = null; } else if (++ numReads >= discardAfterReads) { // We did enough reads already try to discard some bytes so we not risk to see a OOME. // See https://github.com/netty/netty/issues/4275 numReads = 0; discardSomeReadBytes(); } int size = out.size(); decodeWasNull = !out.insertSinceRecycled(); fireChannelRead(ctx, out, size);//向下傳遞消息 out.recycle(); } } else { ctx.fireChannelRead(msg); } }
callDecode方法內部通過while循環的方式對ByteBuf數據進行解碼,直到其中沒有可讀數據
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { try { while (in.isReadable()) {//判斷ByteBuf是還有可讀數據 int outSize = out.size();//獲取記錄鏈表大小 if (outSize > 0) {//判斷鏈表中是否已經有數據 fireChannelRead(ctx, out, outSize);//如果有數據繼續向下傳遞 out.clear();//清空鏈表 // Check if this handler was removed before continuing with decoding. // If it was removed, it is not safe to continue to operate on the buffer. // // See: // - https://github.com/netty/netty/issues/4635 if (ctx.isRemoved()) { break; } outSize = 0; } int oldInputLength = in.readableBytes(); decodeRemovalReentryProtection(ctx, in, out);//開始調用decode方法 // Check if this handler was removed before continuing the loop. // If it was removed, it is not safe to continue to operate on the buffer. // // See https://github.com/netty/netty/issues/1664 if (ctx.isRemoved()) { break; } //這裏如果鏈表為空且bytebuf沒有可讀數據,就跳出循環 if (outSize == out.size()) { if (oldInputLength == in.readableBytes()) { break; } else {//有可讀數據繼續讀取 continue; } } if (oldInputLength == in.readableBytes()) {//beytebuf沒有讀取,但卻進行了解碼 throw new DecoderException( StringUtil.simpleClassName(getClass()) + ".decode() did not read anything but decoded a message."); } if (isSingleDecode()) {//是否設置了每條入站數據只解碼一次,默認false break; } } } catch (DecoderException e) { throw e; } catch (Exception cause) { throw new DecoderException(cause); } }
decodeRemovalReentryProtection方法內部會調用我們重寫的decode解碼實現
final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { decodeState = STATE_CALLING_CHILD_DECODE;//標記狀態 try { decode(ctx, in, out);//調用我們重寫的decode解碼實現 } finally { boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING; decodeState = STATE_INIT; if (removePending) {//這裏判斷標記,防止handlerRemoved事件與解碼操作衝突 handlerRemoved(ctx); } } }
channelRead方法中接受到數據經過一系列邏輯處理,最終會調用我們重寫的decode方法實現具體的解碼功能;在decode方法中我們只需要ByteBuf類型的數據解析為我們需要的數據格式直接放入 List<Object> out鏈表中即可,ByteToMessageDecoder會自動幫你向下傳遞消息。
通過上面的講解,我們可以對Netty中內置自定義編解碼器MessageToByteEncoder與ByteToMessageDecoder有一定的了解,其實它們本質上是Netty封裝的一組專門用於自定義編解碼的channelHandler實現類。在實際開發當中基於這兩個抽象類的實現非常具有實用性,所以在這裏稍作分析, 其中如有不足與不正確的地方還望指出與海涵。
關注微信公眾號,查看更多技術文章。
轉載說明:未經授權不得轉載,授權后務必註明來源(註明:來源於公眾號:架構空間, 作者:大凡)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!