JDK BUG
這篇文章,聊一下我最近才知道的一個關於 JDK 8 的 BUG 吧。
首先說一下我是怎麼發現這個 BUG 的呢?
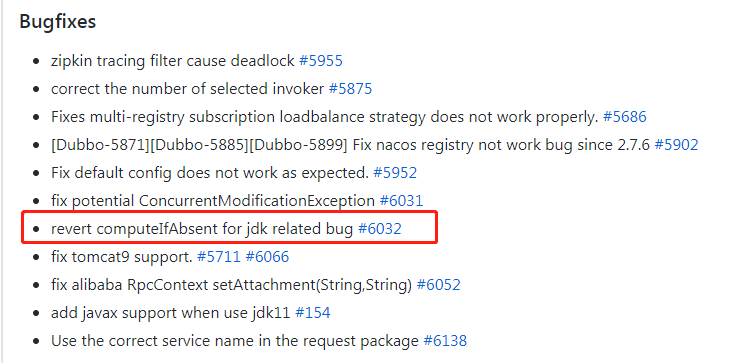
大家都知道我對 Dubbo 有一定的關注,前段時間 Dubbo 2.7.7 發布后我看了它的更新點,就是下面這個網址: https://github.com/apache/dubbo/releases/tag/dubbo-2.7.7
其中有 Bugfixes 這一部分:
每一個我都去簡單的看了一下,其他的 Bugfixes 或多或少都和 Dubbo 框架有一定的關聯性。但是上面紅框框起來的部分完全就是 JDK 的 Bug 了。
所以可以單獨拎出來說。
這個 Bug 我也是看到了這個地方才知道的,但是研究的過程中我發現,這個怎麼說呢:我懷疑這根本就不是 Bug ,這就是 Doug Lea 老爺子在釣魚執法。
為什麼這樣的說呢,大家看完本文就知道了。
Bug 穩定復現
點擊 Dubbo 裏面的鏈接,我們可以看到具體的描述就是一個鏈接:
打開這個鏈接:
https://bugs.openjdk.java.net/browse/JDK-8062841
我們可以看到:這個 Bug 是位於大名鼎鼎的 concurrent 包裏面的 computeIfAbsent 方法。
這個 Bug 在 JDK 9 裏面被修復了,修復人是 Doug Lea。
而我們知道 ConcurrentHashMap 就是 Doug Lea 的大作,可以說是“誰污染誰治理”。
要了解這個 Bug 是怎麼回事,就必須先了解下面這個方法是幹啥的:
java.util.concurrent.ConcurrentHashMap#computeIfAbsent
從這個方法的第二個入參 mappingFunction 我們可以知道這是 JDK 8 之後提供的方法了。
該方法的含義是:當前 Map 中 key 對應的值不存在時,會調用 mappingFunction 函數,並且將該函數的執行結果(不為 null)作為該 key 的 value 返回。
比如下面這樣的:
初始化一個 ConcurrentHashMap ,然後第一次去獲取 key 為 why 的 value,沒有獲取到,直接返回 null。
接着調用 computeIfAbsent 方法,獲取到 null 后調用 getValue 方法,將該方法的返回值和當前的 key 關聯起來。
所以,第二次獲取的時候拿到了 “why技術”。
其實上面的代碼的 17 行的返回值就是 “why技術”,只是我為了代碼演示,再去調用了一次 map.get() 方法。
知道這個方法干什麼的,接下來就帶大家看看 Bug 是什麼。
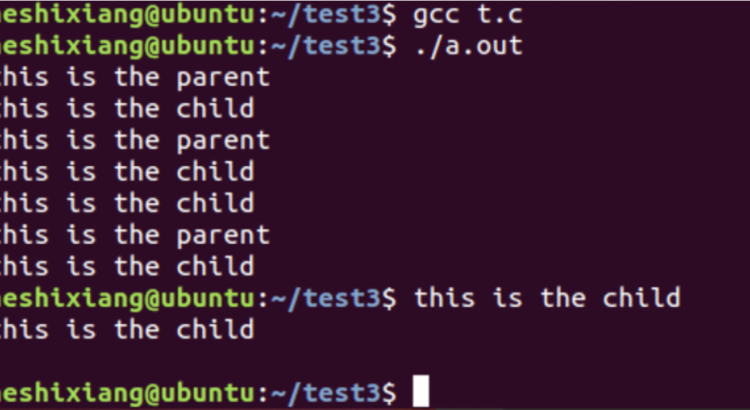
我們直接用這個問題裏面給的測試用例,地址:
https://bugs.openjdk.java.net/secure/attachment/23985/Main.java
我只是在第 11 行和第 21 行加入了輸出語句:
正常的情況下,我們希望方法正常結束,然後 map 裏面是這樣的:{AaAa=42,BBBB=42}
但是你把這個代碼拿到本地去跑(需要 JDK 8 環境),你會發現,這個方法永遠不會結束。因為它在進行死循環。
這就是 Bug。
提問的藝術
知道 Bug 了,按理來說就應該開始分析源碼,了解為啥出現了會出現這個 Bug。
但是我想先插播一小節提問的藝術。因為這個 Bug 就是一個活生生的示例呀。
這個鏈接,我建議你打開看看,這裏面還有 Doug Lea 老爺子的親自解答:
https://bugs.openjdk.java.net/browse/JDK-8062841
首先我們看提出問題的這個人對於問題的描述(可以先不用細看,反正看着也是懵逼的):
通常情況下,被提問的人分為兩類人:
1.遇到過並知道這個問題的人,可以看的明白你在說什麼。
2.雖然沒有碰見過這個問題,但感覺是自己熟悉的領域,可能知道答案,但是看了你的問題描述,也不知道你在說什麼。
這個描述很長,我第一次看的時候很懵逼,很難理解他在說什麼。我就是屬於第二類人。
而且在大多數的問題中,第二類人比第一類人多很多。
但是當我了解到這個 Bug 的來龍去脈的時候,再看這個描述,其實寫的很清楚了,也很好理解。我就變成第一類人了。
但是變成第一類人是有前提的,前提就是我已經了解到了這個地方 Bug 了。可惜,現在是提問,而被提問的人,還對這個 Bug 不是特別了解。
即使,這個被提問的人是 Doug Lea。
可以看到,2014 年 11 月 04 日 Martin 提出這個問題后, Doug Lea 在不到一個小時內就進行了回復,我給大家翻譯一下,老爺子回復的啥:
首先,你說你發現了 ConcurrentHashMap 的問題,但是我沒有看到的測試用例。那麼我就猜測一下是不是有其他線程在計算值的時候被卡住了,但是從你的描述中我也看不到相應的點。
簡單來說就是:Talk is cheap. Show me the code.(屁話少說,放碼過來。)
於是另一個哥們 Pardeep 在一個月後提交了一個測試案例,就是我們前面看到的測試案例:
Pardeep 給 Martin 回復到下面這段話:
他開門見山的說:我注意這個 bug 很長時間了,然後我還有一個測試用例。
可以說這個測試案例的出現,才是真正的轉折點。
然後他提出了自己的看法,這段描述簡短有力的說出了問題的所在(後面我們會講到),然後他還提出了自己的意見。
不到一個小時,這個回到得到了 Doug Lea 的回復:
他說:小伙子的建議還是不錯的,但是現在還不是我們解決這個問題的時候。我們也許會通過代碼改進死鎖檢查機制,以幫助用戶 debug 他們的程序。但是目前而言,這種機制就算做出來,工作效率也是非常低下的,比如在當前的這個案例下。但是現在我們至少清楚的知道,是否要實現這種機制是不能確定的。
總之一句話:問題我知道了,但是目前我還沒想到好的解決方法。
但是,在 19 天以後,老爺子又回來處理這個問題了:
這次的回答可謂是峰迴路轉,他說:請忽略我之前的話。我們發現了一些可行的改進方法,這些改進可以處理更多的用戶錯誤,包括本報告中所提供的測試用例,即解決在 computeIfAbsent 中提供的函數中進行遞歸映射更新導致死鎖這樣的問題。我們會在 JDK 9 裏面解決這個問題。
所以,回顧這個 Bug 被提出的過程。
首先是 Martin 提出了這個問題,並進行了詳細的描述。可惜的是他的描述很專業,是站在你已經了解了這個 Bug 的立場上去描述的,讓人看的很懵逼。
所以 Doug Lea 看到后也表示這啥呀,沒搞懂。
然後是 Pardeep 跟進這個問題,轉折點在於他拋出的這個測試案例。而我相信,既然 Martin 能把這個問題描述的很清楚,他一定是有一個自己的測試案例的,但是他沒有展現出來。
所以,朋友們,測試案例的重要性不言而喻了。問問題的時候不要只是拋出異常,你至少給段對應的代碼,或者日誌,或者一次性描述清楚,寫在文檔裏面發出來也行呀。
Bug 的原因
導致這個 Bug 的原因也是一句話就能說清楚,前面的 Pardeep 老哥也說了:
問題在於我們在進行 computeIfAbsent 的時候,裏面還有一個 computeIfAbsent。而這兩個 computeIfAbsent 它們的 key 對應的 hashCode 是一樣的。
你說巧不巧。
當它們的 hashCode 是一樣的時候,說明它們要往同一個槽放東西。
而當第二個元素進來的時候,發現坑位已經被前一個元素佔領了,可能就是這樣的畫風:
接下來我們就解析一下 computeIfAbsent 方法的工作流程:
第一步是計算 key 對應的 hashCode 應該放到哪個槽裏面。
然後是進入1649 行的這個 for 循環,而這個 for 循環是一個死循環,它在循環體內部判斷各種情況,如果滿足條件則 break 循環。
首先,我們看一下 “AaAa” 和 “BBBB” 經過 spread 計算(右移 16 位高效計算)后的 h 值是什麼:
哇塞,好巧啊,從框起來的這兩部分可以看到,都是 2031775 呢。
說明他們要在同一個槽裏面搞事情。
先是 “AaAa” 進入 computeIfAbsent 方法:
在第一次循環的時候 initTable,沒啥說的。
第二次循環先是在 1653 行計算出數組的下標,並取出該下標的 node。發現這個 node 是空的。於是進入分支判斷:
在標號為 ① 的地方進行 cas 操作,先用 r(即 ReservationNode)進行一個佔位的操作。
在標號為 ② 的地方進行 mappingFunction.apply 的操作,計算 value 值。如果計算出來不為 null,則把 value 組裝成最終的 node。
在標號為 ③ 的東西把之前佔位的 ReservationNode 替換成標號為 ② 的地方組裝成的node 。
問題就出現標號為 ② 的地方。可以看到這裏去進行了 mappingFunction.apply 的操作,而這個操作在我們的案例下,會觸發另一次 computeIfAbsent 操作。
現在 “AaAa” 就等着這個 computeIfAbsent 操作的返回值,然後進行下一步操作,也就是進行標號為 ③ 的操作了。
接着 “BBBB” 就來了。
通過前面我們知道了 “BBBB” 的 hashCode 經過計算后也是和 “AaAa” 一樣。所以它也要想要去那個槽裏面搞事情。
可惜它來晚了一步。
帶大家看一下對應的代碼:
當 key 為 “BBBB” 的時候,算出來的 h 值也是 2031775。
它也會進入 1649 行的這個死循環。然後進行各種判斷。
接下來我要論證的是:
在本文的示例代碼中,當運行到 key 為 “BBBB” 的時候,進入 1649 行這個死循環后,就退不出來了。程序一直在裏面循環運行。
在標號為 ① 的地方,由於這個時候 tab 已經不為 null 了,所以不會進入這個分支。
在標號為 ② 的地方,由於之前 “AaAa” 已經扔了一個 ReservationNode 進去佔位置了,所以不等於 null。所以,也就不會進入這個分支。
怕你懵逼,給你配個圖,真是暖男作者石錘了:
接下來到標號為 ③ 的地方,裏面有一個 MOVED,這個 MOVED 是幹啥的呢?
表示當前的 ConcurrentHashMap 是否是在進行擴容。
很明顯,現在還沒有到該擴容的時候:
第 1678 行的 f 就是之前 “AaAa” 扔進去的 ReservationNode ,這個 Node 的 hash 是 -3,不等於MOVED(-1)。
所以,不會進入這個分支判斷。
接下來,能進的只有標號為 ④ 的地方了,所以我們只需要把這個地方攻破,就徹底了解這個 Bug 了。
走起:
通過前面的分析我們知道了,當前案例情況下,只會進入 1672 行這個分支。
而這個分支裏面,還有四個判斷。我們一個個的攻破:
標號為 ⑤ 的地方,tabAt 方法取出來的對象,就是之前 “AaAa” 放進去的佔位的 ReservationNode ,也就是這個 f 。所以可以進入這個分支判斷。
標號為 ⑥ 的地方,fh >=0 。而 fh 是當前 node 的 hash 值,大於 0 說明當前是按照鏈表存儲的數據。之前我們分析過了,當前的 hash 值是 -3。所以,不會進入這個分支。
標號為 ⑦ 的地方,判斷 f 節點是否是紅黑樹存儲。當然不是的。所以,不會進入這個分支。
標號為 ⑧ 的地方,binCount 代表的是該下標裏面,有幾個 node 節點。很明顯,現在一個都沒有。所以當前的 binCount 還是 0 。所以,不會進入這個分支。
完了。分析完了。
Bug 也就出來了,一次 for 循環結束后,沒有 break。苦就苦在這個 for 循環還是個死循環。
再來一個上帝視角,看看當 key 為 “BBBB” 的時候發生了什麼事情:
進入無限循環內:
①.經過 “AaAa” 之後,tab 就不為 null 了。
②.當前的槽中已經被 “AaAa” 先放了一個 ReservationNode 進行佔位了,所以不為 null。
③.當前的 map 並沒有進行擴容操作。
④.包含⑤、⑥、⑦、⑧。
⑤.tabAt 方法取出來的對象,就是之前 “AaAa” 放進去的佔位的 ReservationNode,所以滿足條件進入分支。
⑥.判斷當前是否是鏈表存儲,不滿足條件,跳過。
⑦.判斷當前是否是紅黑樹存儲,不滿足條件,跳過。
⑧.判斷當前下標裏面是否放了 node,不滿足條件(“AaAa” 只有個佔位的Node ,並沒有初始完成,所以還沒有放到該下標裏面),進入下一次循環。
然後它就在死循環裏面出不來了!
我相信現在大家對於這個 Bug 的來路了解清楚了。
如果你是在 idea 裏面跑這個測試用例,也可以這樣直觀的看一眼:
點擊這個照相機圖標:
從線程快照裏面其實也是可以看到端倪的,大家可以去分析分析。
有的觀點說的是由於線程安全的導致的死循環,經過分析我覺得這個觀點是不對的。
它存在死循環,不是由於線程安全導致的,純粹是自己進入了死循環。
或者說,這是一個“彩蛋”?
或者……自信點,就說這事 Bug ,能穩定復現的那種。
那麼我們如果是使用 JDK 8 怎麼避免踩到這個“彩蛋”呢?
看看 Dubbo 裏面是怎麼解決的:
先調用了 get 方法,如果返回為 null,則調用 putIfAbsent 方法,這樣就能實現和之前一樣的效果了。
如果你在項目中也有使用 computeIfAbsent 的地方,建議也這樣去修改。
說到 ConcurrentHashMap get 方法返回 null,我就想起了之前討論的一個面試題了:
答案都寫在這個文章裏面了,有興趣的可以了解一下《這道面試題我真不知道面試官想要的回答是什麼》
Bug 的解決 其實徹底理解了這個 Bug 之後,我們再來看一下 JDK 9 裏面的解決方案,看一下官方源碼對比:
http://gee.cs.oswego.edu/cgi-bin/viewcvs.cgi/jsr166/src/main/java/util/concurrent/ConcurrentHashMap.java?r1=1.258&r2=1.259&sortby=date&diff_format=f
就加了兩行代碼,判斷完是否是紅黑樹節點后,再判斷一下是否是 ReservationNode 節點,因為這個節點就是個佔位節點。如果是,則拋出異常。
就這麼簡單。沒有什麼神秘的。
所以,如果你在 JDK 9 裏面執行文本的測試用例,就會拋出 IllegalStateException。
這就是 Doug Lea 之前提到的解決方案:
了解了這個 Bug 的來龍去脈后,特別是看到解決方案后,我們就能輕描淡寫的說一句:
害,就這?沒聽說過!
另外,我看 JDK 9 修復的時候還不止修復了一個問題:
http://hg.openjdk.java.net/jdk9/jdk9/jdk/file/6dd59c01f011/src/java.base/share/classes/java/util/concurrent/ConcurrentHashMap.java
你去翻一翻。發現,啊,全是知識點啊,學不動了。
釣魚執法
為什麼我在文章的一開始就說了這是 Doug Lea 在釣魚執法呢?
因為在最開始提問的藝術那一部分,我相信,Doug Lea 跑完那個測試案例之後,心裏也有點數了。
大概知道問題在哪了,而且從他的回答和他寫的文檔中我也有理由相信,他寫的這個方法的時候就知道可能會出問題。
而且,Pardeep 的回復中提到了文檔,那我們就去看看官方文檔對於該方法的描述是怎樣的:
https://docs.oracle.com/javase/8/docs/api/
文檔中說函數方法應該簡短,簡單。而且不能在更新的映射的時候更新映射。就是說不能套娃。
套娃,用程序說就是recursive(遞歸),按照文檔說如果存在遞歸,則會拋出 IllegalStateException 。
而提到遞歸,你想到了什麼?
我首先就想到了斐波拉契函數。我們用 computeIfAbsent 實現一個斐波拉契函數如下:
public class Test {
static Map<Integer, Integer> cache = new ConcurrentHashMap<>();
public static void main(String[] args) {
System.out.println("f(" + 14 + ") =" + fibonacci(14));
}
static int fibonacci(int i) {
if (i == 0)
return i;
if (i == 1)
return 1;
return cache.computeIfAbsent(i, (key) -> {
System.out.println("Slow calculation of " + key);
return fibonacci(i - 2) + fibonacci(i - 1);
});
}
}
這就是遞歸調用,我用 JDK 1.8 跑的時候並沒有拋出 IllegalStateException,只是程序假死了,原因和我們前面分析的是一樣一樣的。我理解這個地方是和文檔不符的。
所以,我懷疑是 Doug Lea 在這個地方釣魚執法。
CHM一定線程安全嗎?
既然都說到 currentHashMap(CHM)了,那我說一個相關的注意點吧。
首先 CHM 一定能保證線程安全嗎?
是的,CHM 本身一定是線程安全的。但是,如果你使用不當還是有可能會出現線程不安全的情況。
給大家看一點 Spring 中的源碼吧:
org.springframework.core.SimpleAliasRegistry
在這個類中,aliasMap 是 ConcurrentHashMap 類型的:
在 registerAlias 和 getAliases 方法中,都有對 aliasMap 進行操作的代碼,但是在操作之前都是用 synchronized 把 aliasMap 鎖住了。
為什麼?為什麼我們操作 ConcurrentHashMap 的時候還要加鎖呢?
這個是根據場景而定的,這個別名管理器,在這裏加鎖應該是為了避免多個線程操作 ConcurrentHashMap 。
雖然 ConcurrentHashMap 是線程安全的,但是假設如果一個線程 put,一個線程 get,在這個代碼的場景裏面是不允許的。
如果覺得不太好理解的話我舉一個 redis 的例子。
redis 的 get、set 方法都是線程安全的吧。但是你如果先 get 再 set,那麼在多線程的情況下還是會有問題的。
因為這兩個操作不是原子性的。所以 incr 就應運而生了。
我舉這個例子的是想說線程安全與否不是絕對的,要看場景。給你一個線程安全的容器,你使用不當還是會有線程安全的問題。
再比如,HashMap 一定是線程不安全的嗎?
說不能說的這麼死吧。它是一個線程不安全的容器。但是如果我的使用場景是只讀呢?
在這個只讀的場景下,它就是線程安全的。
總之,看場景。道理,就是這麼一個道理。
最後說兩句(求關注)
所以點個“贊”吧,周更很累的,不要白嫖我,需要一點正反饋。
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,還請你留言指出來,我對其加以修改。
感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個被代碼耽誤的文學創作者,不是大佬,但是喜歡分享,是一個又暖又有料的四川好男人。
歡迎關注我的微信公眾號:why技術。在這裏我會分享一些java技術相關的知識,用匠心敲代碼,對每一行代碼負責。偶爾也會荒腔走板的聊一聊生活,寫一寫書評、影評。感謝你的關注,願你我共同進步。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!