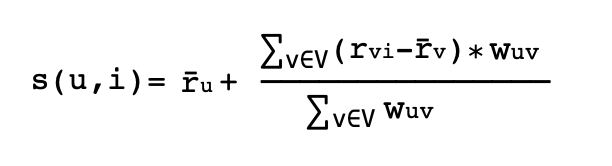1.概述
之前介紹了如何構建一個推薦系統,今天給大家介紹如何基於用戶的協同過濾來構建推薦的實戰篇。
2.內容
協同過濾技術在推薦系統中應用的比較廣泛,它是一個快速發展的研究領域。它比較常用的兩種方法是基於內存(Memory-Based)和基於模型(Model-Based)。
- 基於內存:主要通過計算近似度來進行推薦,比如基於用戶(Used-Based)和基於物品(Item-Based)的協同過濾,這兩個模式中都會首先構建用戶交互矩陣,然後矩陣的行向量和列向量可以用來表示用戶和物品,然後計算用戶和物品的相似度來進行推薦;
- 基於模型:主要是對交互矩陣進行填充,預測用戶購買某個物品的可能性。
為了解決這些問題,可以通過建立協同過濾模型,利用購買數據向客戶推薦產品。下面,我們通過基於用戶的協同過濾(基於內存),通過實戰來一步步實現其中的細節。基於用戶的系統過濾體現在具有相似特徵的人擁有相似的喜好。比如,用戶A向用戶B推薦了物品C,而B購買過很多類似C的物品,並且評價也高。那麼,在未來,用戶B也會有很大的可能會去購買物品C,並且用戶B會基於相似度度量來推薦物品C。
2.1 基於用戶與用戶的協同過濾
這種方式識別與查詢用戶相似的用戶,並估計期望的評分為這些相似用戶評分的加權平均值。實戰所使用的Python語言,這裏需要依賴的庫如下:
Python環境:
2.2 評分函數
這裏給非個性化協同過濾(不包含活躍用戶的喜歡、不喜歡、以及歷史評分),返回一個以用戶U和物品I作為輸入參數的分數。該函數輸出一個分數,用於量化用戶U喜歡 / 偏愛物品I的程度。這通常是通過對與用戶相似的人的評分來完成的。涉及的公式如下:
這裏其中s為預測得分,u為用戶,i為物品,r為用戶給出的評分,w為權重。在這種情況下,我們的分數等於每個用戶對該項目的評價減去該用戶的平均評價再乘以某個權重的總和,這個權重表示該用戶與其他用戶有多少相似之處,或者對其他用戶的預測有多少貢獻。這是用戶u和v之間的權重,分數在0到1之間,其中0是最低的,1是最高的。理論上看起來非常完美,那為啥需要從每個用戶的評分中減去平均評分,為啥要使用加權平均而不是簡單平均?這是因為我們所處理的用戶類型,首先,人們通常在不同的尺度上打分,用戶A可能是一個积極樂觀的用戶,會給用戶A自己喜歡的電影平均高分(例如4分、或者5分)。而用戶B是一個不樂觀或者對評分標準比較高的用戶,他可能對最喜歡的電影評分為2分到5分之間。用戶B的2分對應到用戶A的4分。改進之處是可以通過規範化用戶評分來提高算法效率。一種方法是計算s(u,i)的分數,它是用戶對每件物品的平均評價加上一些偏差。通過使用餘弦相似度來計算上述公式中給出的權重,同時,按照上述方式對數據進行歸一化,在pandas中進行一些數據分析。
2.2.1 導入Python依賴包
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics import pairwise_distances
2.2.2 加載數據源
加載數據示例代碼如下所示:
movies = pd.read_csv("data/movies.csv")
Ratings = pd.read_csv("data/ratings.csv")
Tags = pd.read_csv("data/tags.csv")
結果預覽如下:
print(movies.head())
print(Ratings.head())
print(Tags.head())
構建數據:
Mean = Ratings.groupby(by="userId", as_index=False)['rating'].mean()
Rating_avg = pd.merge(Ratings, Mean, on='userId')
Rating_avg['adg_rating'] = Rating_avg['rating_x'] - Rating_avg['rating_y']
print(Rating_avg.head())
結果如下:
2.3 餘弦相似度
對於上面的公式,我們需要找到有相似想法的用戶。找到一個喜歡和不喜歡的用戶聽起來很有意思,但是我們如何找到相似性呢?那麼這裏我們就需要用到餘弦相似度,看看用戶有多相似。它通常是根據用戶過去的評分來計算的。
這裏使用到Python的的sklearn的cosine_similarity函數來計算相似性,並做一些數據預處理和數據清洗。實例代碼如下:
check = pd.pivot_table(Rating_avg,values='rating_x',index='userId',columns='movieId')
print(check.head())
final = pd.pivot_table(Rating_avg,values='adg_rating',index='userId',columns='movieId')
print(final.head())
結果如下:
上圖中包含了很多NaN的值,這是因為每個用戶都沒有看過所有的電影,所以這種類型的矩陣被稱為稀疏矩陣。類似矩陣分解的方法被用來處理這種稀疏性,接下來,我們來對這些NaN值做相關替換。
這裏通常有兩種方式:
- 使用行上的用戶平均值;
- 用戶在列上的電影平均值
代碼如下:
# Replacing NaN by Movie Average
final_movie = final.fillna(final.mean(axis=0))
print(final_movie.head())
# Replacing NaN by user Average
final_user = final.apply(lambda row: row.fillna(row.mean()), axis=1)
print(final_user.head())
結果如下:
接着,我們開始計算用戶之間的相似性,代碼如下:
# user similarity on replacing NAN by item(movie) avg
cosine = cosine_similarity(final_movie)
np.fill_diagonal(cosine, 0)
similarity_with_movie = pd.DataFrame(cosine, index=final_movie.index)
similarity_with_movie.columns = final_user.index
# print(similarity_with_movie.head())
# user similarity on replacing NAN by user avg
b = cosine_similarity(final_user)
np.fill_diagonal(b, 0 )
similarity_with_user = pd.DataFrame(b,index=final_user.index)
similarity_with_user.columns=final_user.index
# print(similarity_with_user.head())
結果如下:
然後,我們來檢驗一下我們的相似度是否有效,代碼如下:
def get_user_similar_movies( user1, user2 ):
common_movies = Rating_avg[Rating_avg.userId == user1].merge(
Rating_avg[Rating_avg.userId == user2],
on = "movieId",
how = "inner" )
return common_movies.merge( movies, on = 'movieId' )
a = get_user_similar_movies(370,86309)
a = a.loc[ : , ['rating_x_x','rating_x_y','title']]
print(a.head())
結果如下:
從上圖中,我們可以看出產生的相似度幾乎是相同的,符合真實性。
2.4 相鄰用戶
在2.3中計算了所有用戶的相似度,但是在大數據領域,推薦系統與大數據相結合是至關重要的。以電影推薦為例子,構建一個矩陣(862 * 862),這個與實際的用戶數據(百萬、千萬或者更多)相比,這是一個很小的矩陣。因此在計算任何物品的分數時,如果總是查看所有其他用戶將不是一個好的解決方案或者方法。因此,採用相鄰用戶的思路,對於特定用戶,只取K個類似用戶的集合。
下面,我們對K取值30,所有的用戶都有30個相鄰用戶,代碼如下:
def find_n_neighbours(df,n):
order = np.argsort(df.values, axis=1)[:, :n]
df = df.apply(lambda x: pd.Series(x.sort_values(ascending=False)
.iloc[:n].index,
index=['top{}'.format(i) for i in range(1, n+1)]), axis=1)
return df
# top 30 neighbours for each user
sim_user_30_u = find_n_neighbours(similarity_with_user,30)
print(sim_user_30_u.head())
sim_user_30_m = find_n_neighbours(similarity_with_movie,30)
print(sim_user_30_m.head())
結果如下:
2.5 計算最後得分
實現代碼如下所示:
def User_item_score(user,item):
a = sim_user_30_m[sim_user_30_m.index==user].values
b = a.squeeze().tolist()
c = final_movie.loc[:,item]
d = c[c.index.isin(b)]
f = d[d.notnull()]
avg_user = Mean.loc[Mean['userId'] == user,'rating'].values[0]
index = f.index.values.squeeze().tolist()
corr = similarity_with_movie.loc[user,index]
fin = pd.concat([f, corr], axis=1)
fin.columns = ['adg_score','correlation']
fin['score']=fin.apply(lambda x:x['adg_score'] * x['correlation'],axis=1)
nume = fin['score'].sum()
deno = fin['correlation'].sum()
final_score = avg_user + (nume/deno)
return final_score
score = User_item_score(320,7371)
print("score (u,i) is",score)
結果如下:
這裏我們算出來的預測分數是4.25,因此可以認為用戶(370),可能喜歡ID(7371)的電影。接下來,我們給用戶(370)做電影推薦,實現代碼如下:
Rating_avg = Rating_avg.astype({"movieId": str})
Movie_user = Rating_avg.groupby(by = 'userId')['movieId'].apply(lambda x:','.join(x))
def User_item_score1(user):
Movie_seen_by_user = check.columns[check[check.index==user].notna().any()].tolist()
a = sim_user_30_m[sim_user_30_m.index==user].values
b = a.squeeze().tolist()
d = Movie_user[Movie_user.index.isin(b)]
l = ','.join(d.values)
Movie_seen_by_similar_users = l.split(',')
Movies_under_consideration = list(set(Movie_seen_by_similar_users)-set(list(map(str, Movie_seen_by_user))))
Movies_under_consideration = list(map(int, Movies_under_consideration))
score = []
for item in Movies_under_consideration:
c = final_movie.loc[:,item]
d = c[c.index.isin(b)]
f = d[d.notnull()]
avg_user = Mean.loc[Mean['userId'] == user,'rating'].values[0]
index = f.index.values.squeeze().tolist()
corr = similarity_with_movie.loc[user,index]
fin = pd.concat([f, corr], axis=1)
fin.columns = ['adg_score','correlation']
fin['score']=fin.apply(lambda x:x['adg_score'] * x['correlation'],axis=1)
nume = fin['score'].sum()
deno = fin['correlation'].sum()
final_score = avg_user + (nume/deno)
score.append(final_score)
data = pd.DataFrame({'movieId':Movies_under_consideration,'score':score})
top_5_recommendation = data.sort_values(by='score',ascending=False).head(5)
Movie_Name = top_5_recommendation.merge(movies, how='inner', on='movieId')
Movie_Names = Movie_Name.title.values.tolist()
return Movie_Names
user = int(input("Enter the user id to whom you want to recommend : "))
predicted_movies = User_item_score1(user)
print(" ")
print("The Recommendations for User Id : 370")
print(" ")
for i in predicted_movies:
print(i)
結果如下:
3.總結
基於用戶的協同過濾,流程簡述如下:
- 採集數據 & 存儲數據
- 加載數據
- 數據建模(數據預處理 & 數據清洗)
- 計算相似性(餘弦相似度、相鄰計算)
- 得分預測(預測和最終得分計算)
- 物品推薦
4.結束語
這篇博客就和大家分享到這裏,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,博主出書了《Kafka並不難學》和《Hadoop大數據挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點擊購買鏈接購買博主的書進行學習,在此感謝大家的支持。關注下面公眾號,根據提示,可免費獲取書籍的教學視頻
,
這篇博客就和大家分享到這裏,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,博主出書了《Kafka並不難學》和《Hadoop大數據挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點擊購買鏈接購買博主的書進行學習,在此感謝大家的支持。關注下面公眾號,根據提示,可免費獲取書籍的教學視頻
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!