說明:設計模式系列文章是讀劉偉所著《設計模式的藝術之道(軟件開發人員內功修鍊之道)》一書的閱讀筆記。個人感覺這本書講的不錯,有興趣推薦讀一讀。詳細內容也可以看看此書作者的博客https://blog.csdn.net/LoveLion/article/details/17517213
模式概述
樹形結構在軟件中隨處可見,例如操作系統中的目錄結構、應用軟件中的菜單、辦公系統中的公司組織結構等等,如何運用面向對象的方式來處理這種樹形結構是組合模式需要解決的問題。組合模式通過一種巧妙的設計方案使得用戶可以一致性地處理整個樹形結構或者樹形結構的一部分,也可以一致性地處理樹形結構中的恭弘=叶 恭弘子節點(不包含子節點的節點)和容器節點(包含子節點的節點)。
模式定義
組合模式(Composite Pattern):組合多個對象形成樹形結構以表示具有“整體—部分”關係的層次結構。組合模式對單個對象(即恭弘=叶 恭弘子對象)和組合對象(即容器對象)的使用具有一致性,組合模式又可以稱為“整體—部分”(Part-Whole)模式,它是一種對象結構型模式。
模式結構圖
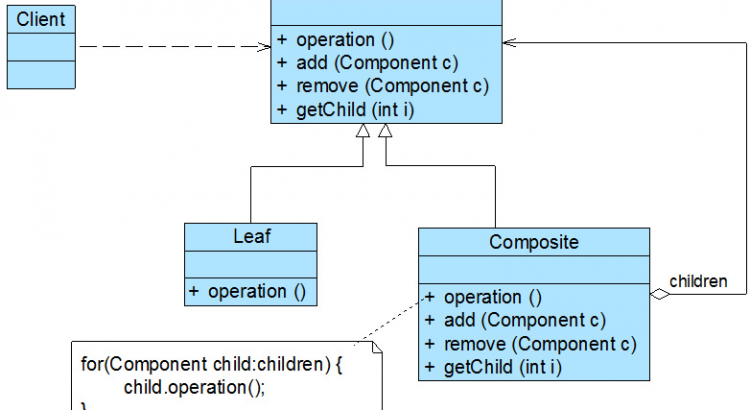
組合模式結構圖如下所示:
在組合模式結構圖中包含如下幾個角色:
-
Component(抽象構件):它可以是接口或抽象類,為恭弘=叶 恭弘子構件和容器構件對象聲明接口,在該角色中可以包含所有子類共有行為的聲明和實現。在抽象構件中定義了訪問及管理它的子構件的方法,如增加子構件、刪除子構件、獲取子構件等。 -
Leaf(恭弘=叶 恭弘子構件):它在組合結構中表示恭弘=叶 恭弘子節點對象,恭弘=叶 恭弘子節點沒有子節點,它實現了在抽象構件中定義的行為。對於那些訪問及管理子構件的方法,可以通過異常等方式進行處理。 -
Composite(容器構件):它在組合結構中表示容器節點對象,容器節點包含子節點,其子節點可以是恭弘=叶 恭弘子節點,也可以是容器節點,它提供一個集合用於存儲子節點,實現了在抽象構件中定義的行為,包括那些訪問及管理子構件的方法,在其業務方法中可以遞歸調用其子節點的業務方法。
組合模式的關鍵是定義了一個
抽象構件類,它既可以代表恭弘=叶 恭弘子,又可以代表容器,而客戶端針對該抽象構件類進行編程,無須知道它到底表示的是恭弘=叶 恭弘子還是容器,可以對其進行統一處理。同時容器對象與抽象構件類之間還建立一個聚合關聯關係,在容器對象中既可以包含恭弘=叶 恭弘子,也可以包含容器,以此實現遞歸組合,形成一個樹形結構。
模式偽代碼
對於客戶端而言,一般針對抽象構件編程,而無須關心其具體子類是容器構件還是恭弘=叶 恭弘子構件。抽象構建類典型代碼如下:
public abstract class Component {
public abstract void add(Component c); //增加成員
public abstract void remove(Component c); //刪除成員
public abstract Component getChild(int i); //獲取成員
public abstract void operation(); //業務方法
}
如果繼承抽象構件的是恭弘=叶 恭弘子構件,則其典型代碼如下所示:
public class Leaf extends Component {
@Override
public void add(Component c) {
//異常處理或錯誤提示
}
@Override
public void remove(Component c) {
//異常處理或錯誤提示
}
@Override
public Component getChild(int i) {
//異常處理或錯誤提示
return null;
}
@Override
public void operation() {
//恭弘=叶 恭弘子構件具體業務方法的實現
}
}
如果繼承抽象構件的是容器構件,則其典型代碼如下所示:
public class Composite extends Component {
private List<Component> list = new ArrayList<>();
@Override
public void add(Component c) {
list.add(c);
}
@Override
public void remove(Component c) {
list.remove(c);
}
@Override
public Component getChild(int i) {
return (Component) list.get(i);
}
@Override
public void operation() {
//容器構件具體業務方法的實現
//遞歸調用成員構件的業務方法
for (Object obj : list) {
((Component) obj).operation();
}
}
}
客戶端對抽象構件類進行編程
public class Client {
public static void main(String[] args) {
Component component;
component = new Leaf();
//component = new Composite();
// 無須知道到底是恭弘=叶 恭弘子還是容器
// 可以對其進行統一處理
component.operation();
}
}
模式簡化
透明組合模式
透明組合模式中,抽象構件Component中聲明了所有用於管理成員對象的方法,包括add()、remove()以及getChild()等方法,這樣做的好處是確保所有的構件類都有相同的接口。在客戶端看來,恭弘=叶 恭弘子對象與容器對象所提供的方法是一致的,客戶端可以相同地對待所有的對象。透明組合模式也是組合模式的標準形式。
透明組合模式的完整結構圖如下:
也可以將恭弘=叶 恭弘子構件的add()、remove()等方法的實現代碼移至Component中,由Component提供統一的默認實現,這樣子類就不必強制去實現管理子Component。代碼如下所示:
public abstract class Component {
public void add(Component c) {
throw new RuntimeException("不支持的操作");
}
public void remove(Component c) {
throw new RuntimeException("不支持的操作");
}
public Component getChild(int i) {
throw new RuntimeException("不支持的操作");
}
public abstract void operation(); //業務方法
}
透明組合模式的缺點是不夠安全,因為恭弘=叶 恭弘子對象和容器對象在本質上是有區別的。恭弘=叶 恭弘子對象不可能有下一個層次的對象,即不可能包含成員對象,因此為其提供add()、remove()以及getChild()等方法是沒有意義的,這在編譯階段不會出錯,但在運行階段如果調用這些方法可能會出錯(如果沒有提供相應的錯誤處理代碼)。
安全組合模式
安全組合模式中,在抽象構件Component中沒有聲明任何用於管理成員對象的方法,而是在Composite類中聲明並實現這些方法。
安全組合模式的完整結構圖如下:
此時Component就應該這樣定義了
public abstract class Component {
// 業務方法
public abstract void operation();
}
安全組合模式的缺點是不夠透明,因為恭弘=叶 恭弘子構件和容器構件具有不同的方法,且容器構件中那些用於管理成員對象的方法沒有在抽象構件類中定義,因此客戶端不能完全針對抽象編程,必須有區別地對待恭弘=叶 恭弘子構件和容器構件。在實際應用中,安全組合模式的使用頻率也非常高,在Java AWT中使用的組合模式就是安全組合模式。
模式應用
模式在JDK中的應用
Java SE中的AWT和Swing包的設計就基於組合模式,在這些界麵包中為用戶提供了大量的容器構件(如Container)和成員構件(如Checkbox、Button和TextComponent等),其結構如下圖所示
Component類是抽象構件,Checkbox、Button和TextComponent是恭弘=叶 恭弘子構件,而Container是容器構件,在AWT中包含的恭弘=叶 恭弘子構件還有很多。在一個容器構件中可以包含恭弘=叶 恭弘子構件,也可以繼續包含容器構件,這些恭弘=叶 恭弘子構件和容器構件一起組成了複雜的GUI界面。除此以外,在XML解析、組織結構樹處理、文件系統設計等領域,組合模式都得到了廣泛應用。
模式在開源項目中的應用
Spring中org.springframework.web.method.support.HandlerMethodArgumentResolver使用了安全組合模式。提取關鍵代碼如下:
public interface HandlerMethodArgumentResolver {
boolean supportsParameter(MethodParameter parameter);
Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception;
}
再看下它的一個實現類org.springframework.web.method.support.HandlerMethodArgumentResolverComposite
public class HandlerMethodArgumentResolverComposite implements HandlerMethodArgumentResolver {
private final List<HandlerMethodArgumentResolver> argumentResolvers = new LinkedList<>();
/**
* Add the given {@link HandlerMethodArgumentResolver}.
*/
public HandlerMethodArgumentResolverComposite addResolver(HandlerMethodArgumentResolver resolver) {
this.argumentResolvers.add(resolver);
return this;
}
/**
* Add the given {@link HandlerMethodArgumentResolver HandlerMethodArgumentResolvers}.
*/
public HandlerMethodArgumentResolverComposite addResolvers(
@Nullable HandlerMethodArgumentResolver... resolvers) {
if (resolvers != null) {
Collections.addAll(this.argumentResolvers, resolvers);
}
return this;
}
/**
* Clear the list of configured resolvers.
*/
public void clear() {
this.argumentResolvers.clear();
}
@Override
public boolean supportsParameter(MethodParameter parameter) {
return getArgumentResolver(parameter) != null;
}
@Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
HandlerMethodArgumentResolver resolver = getArgumentResolver(parameter);
if (resolver == null) {
throw new IllegalArgumentException("Unsupported parameter type [" +
parameter.getParameterType().getName() + "]. supportsParameter should be called first.");
}
return resolver.resolveArgument(parameter, mavContainer, webRequest, binderFactory);
}
}
模式總結
主要優點
-
組合模式可以清楚地定義分層次的複雜對象,表示對象的全部或部分層次,它讓客戶端忽略了層次的差異,方便對整個層次結構進行控制。
-
客戶端可以一致地使用一個組合結構或其中單個對象,不必關心處理的是單個對象還是整個組合結構,簡化了客戶端代碼。
-
組合模式為樹形結構的面向對象實現提供了一種靈活的解決方案,通過恭弘=叶 恭弘子對象和容器對象的遞歸組合,可以形成複雜的樹形結構,但對樹形結構的控制卻非常簡單。
適用場景
(1) 在具有整體和部分的層次結構中,希望通過一種方式忽略整體與部分的差異,客戶端可以一致地對待它們。
(2) 在一個使用面向對象語言開發的系統中需要處理一個樹形結構。
(3) 在一個系統中能夠分離出恭弘=叶 恭弘子對象和容器對象,而且它們的類型不固定,需要增加一些新的類型。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!