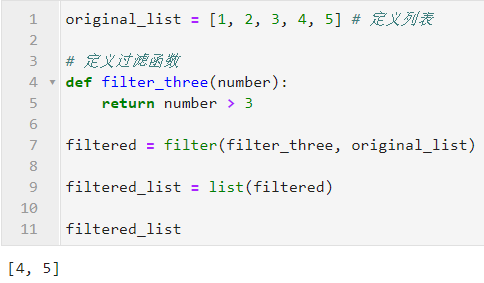
介紹
使用Spring Bboot是快樂並且簡單的,不需要繁瑣的配置就能夠完成一套非常強大的應用。
spring boot 2.3.1
Spring Boot 2.3.1 發佈於:2020/06/12,現在已經提交到 Spring 倉庫和 Maven 中央倉庫了。
這個版本包括 127 個 bug 修復、Spring Boot 文檔改進增強、依賴升級等,另外還新增了一些新特性:
•提供基於新的 Maven 坐標 com.oracle.database 對 Oracle JDBC driver 的依賴管理;
•優化 Spring Cloud 的 CachedRandomPropertySource 不能正確適配的問題;•限制使用定製的 YAML 類型;
•增強對 NoSuchMethodErrors 異常失敗分析,能显示基類從哪被加載的;•提供更佳的錯誤消息,如果 Docker 停止運行了;
•優化 SystemEnvironmentPropertyMapper 類;
•提供更佳的診斷信息,當構建 OCI 鏡像失敗時 Docker 響應的 500 錯誤;
•支持通過 alwaysUseFullPath=true 參數來配置 UrlPathHelper;•支持在 Elasticsearch URIs 中使用用戶信息;
•支持在 Spring WebFlux 框架中使用歡迎頁面;
這個小版本還增加了蠻多東西的,大家也沒有必要跟着版本走,可以根據需要進行升級。疫情也擋不住外國友人更新的熱情。
實現
使用STS,可以去官方網站下載最新版。網站地址 https://Spring.io/tools/sts/ Spring Tool Suite™是基於eclipse開發的專門為Spring開發使用的工具包。
新建工程
選擇Spring Starter Project,
輸入工程名 對應的Name 打包方式 對應的Packaging,可以選擇jar或者war的方式。
輸入組織名 對應的Group 輸入描述 對應的Description
輸入包名 對應的Package 點擊next,然後選擇web和mysql
這裏的版本用的是2.3.1 如果沒有本地maven庫或者私庫會下載很長時間。
添加默認請求
進入 Chapter0301Application 添加
@RestController @SpringBootApplication public class Chapter0301Application { @RequestMapping("/") String home() { return "歡迎使用Spring Boot!"; } public static void main(String[] args) { SpringApplication.run(Chapter0301Application.class, args); } }
使用@RestController 相當於@Controller 和 @RequestBody。是Sspring Bboot 基於Sspring MVC的基礎上進行了改進, 將@Controller 與@ResponseBody 進行了合併形成的一個新的註解。 @EnableAutoConfiguration 作用 從classpath中搜索所有META-INF/spring.factories配置文件然後,將其中org.springframework.boot.autoconfigure.EnableAutoConfiguration key對應的配置項加載到spring容器 只有spring.boot.enableautoconfiguration為true(默認為true)的時候,才啟用自動配置 @EnableAutoConfiguration還可以進行排除,排除方式有2種,一是根據class來排除(exclude),二是根據class name(excludeName)來排除 其內部實現的關鍵點有
1.ImportSelector 該接口的方法的返回值都會被納入到spring容器管理中
2.SpringFactoriesLoader 該類可以從classpath中搜索所有META-INF/spring.factories配置文件,並讀取配置
啟動spring boot
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.3.1.RELEASE) 2020-06-23 13:30:11.611 INFO 9916 --- [ main] com.cloud.sky.Chapter0301Application : Starting Chapter0301Application on DADI-PC with PID 9916 (D:\java\microservice\chapter0301\target\classes started by Administrator in D:\java\microservice\chapter0301) 2020-06-23 13:30:11.614 INFO 9916 --- [ main] com.cloud.sky.Chapter0301Application : No active profile set, falling back to default profiles: default 2020-06-23 13:30:12.415 INFO 9916 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2020-06-23 13:30:12.423 INFO 9916 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2020-06-23 13:30:12.424 INFO 9916 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.36] 2020-06-23 13:30:12.512 INFO 9916 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2020-06-23 13:30:12.512 INFO 9916 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 830 ms 2020-06-23 13:30:12.665 INFO 9916 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2020-06-23 13:30:12.809 INFO 9916 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2020-06-23 13:30:12.818 INFO 9916 --- [ main] com.cloud.sky.Chapter0301Application : Started Chapter0301Application in 1.492 seconds (JVM running for 3.109) 2020-06-23 13:30:20.675 INFO 9916 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2020-06-23 13:30:20.676 INFO 9916 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2020-06-23 13:30:20.680 INFO 9916 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 4 ms
打開瀏覽器訪問 http://localhost:8080/ 可以得到如下頁面
遇到問題
構建的過程中遇到問題
[INFO] Scanning for projects... [ERROR] [ERROR] Some problems were encountered while processing the POMs: [FATAL] Non-parseable POM D:\java\apache-maven-3.1.1\repo\org\jetbrains\kotlin\kotlin-bom\1.3.72\kotlin-bom-1.3.72.pom: entity reference names can not start with character ')' (position: START_TAG seen ...ost,s="";function qs(n){var u=D.URL;var t=u.match(eval(\'/(\\?|#|&)... @1:243) @ D:\java\apache-maven-3.1.1\repo\org\jetbrains\kotlin\kotlin-bom\1.3.72\kotlin-bom-1.3.72.pom, line 1, column 243 @ [ERROR] The build could not read 1 project -> [Help 1] [ERROR] [ERROR] The project com.cloudskyme:chapter0301:0.0.1 (D:\java\microservice\chapter0301\pom.xml) has 1 error [ERROR] Non-parseable POM D:\java\apache-maven-3.1.1\repo\org\jetbrains\kotlin\kotlin-bom\1.3.72\kotlin-bom-1.3.72.pom: entity reference names can not start with character ')' (position: START_TAG seen ...ost,s="";function qs(n){var u=D.URL;var t=u.match(eval(\'/(\\?|#|&)... @1:243) @ D:\java\apache-maven-3.1.1\repo\org\jetbrains\kotlin\kotlin-bom\1.3.72\kotlin-bom-1.3.72.pom, line 1, column 243 -> [Help 2] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/ProjectBuildingException [ERROR] [Help 2] http://cwiki.apache.org/confluence/display/MAVEN/ModelParseException
1. 解決
修改maven默認源配置
我使用的是阿里的maven倉庫,國外的東西沒個代理還真麻煩。
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>sonatype-nexus-snapshots</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
然後執行 mvn help:system
成功可以看到如下界面:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?