從一道面試題開始
看到這個標題,你肯定以為我又要講這道面試題了
// 這行代碼創建了幾個對象?
String s3 = new String("1");
是的,沒錯,我確實要從這裏開始
這道題就算你沒做過也肯定看到,總所周知,它創建了兩個對象,一個位於堆上,一個位於常量池中。
這個答案粗看起來是沒有任何問題的,但是仔細思考確經不起推敲。
如果你覺得我說的不對的話,那麼可以思考下面這兩個問題
-
你說它創建了兩個對象,那麼這兩個對象分別是怎樣創建的呢?我們回顧下Java創建對象的方式,一共就這麼幾種
- 使用new關鍵字創建對象
- 使用反射創建對象(包括Class類的
newInstance方法,以及Constructor類的newInstance方法)
- 使用clone複製一個對象
- 反序列化得到一個對象
你說它創建了兩個對象,那你告訴我除了new出來那個對象外,另外一個對象怎麼創建出來的?
-
堆跟常量池到底什麼關係?不是說在JDK1.7之後(含1.7版本)常量池已經移到了堆中了嗎?如果說常量池本身就位於堆中的話,那麼這種一個對象在堆中,一個對象在常量池的說法還準確嗎?
如果你也產生過這些疑問的話,那麼請耐心看完這篇文章!要解釋上面的問題首先我們得對常量池有個準確的認知。
常量池
通常來說,我們提到的常量池分為三種
- class文件中的常量池
- 運行時常量池
- 字符串常量池
對於這三種常量池,我們需要搞懂下面幾個問題?
- 這個常量池在哪裡?
- 這個常量池用來干什麼呢?
- 這三者有什麼關係?
接下來,我們帶着這些問題往下看
class文件中的常量池
位置在哪?
顧名思義,class文件中的常量池當然是位於class文件中,而class文件又是位於磁盤上。
用來干什麼的?
在學習class文件中的常量池前,我們首選需要對class文件的結構有一定了解
Class文件是一組以8個字節為基礎單位的二進制流,各個數據項目嚴格按照順序緊湊地排列在文
件之中,中間沒有添加任何分隔符,這使得整個Class文件中存儲的內容幾乎全部是程序運行的必要數
據,沒有空隙存在。
————《深入理解Java虛擬機》
整個class文件的組成可以用下圖來表示
對本文而言,我們只關注其中的常量池部分,常量池可以理解為class文件中資源倉庫,它是class文件結構中與其它項目關聯最多的數據類型,主要用於存放編譯器生成的各種字面量(Literal)和符號引用(Symbolic References)。
字面量就是我們所說的常量概念,如文本字符串、被聲明為final的常量值等。
符號引用是一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能無歧義地定位到目標即可(它與直接引用區分一下,直接引用一般是指向方法區的本地指針,相對偏移量或是一個能間接定位到目標的句柄)。一般包括下面三類常量:
- 類和接口的全限定名
- 字段的名稱和描述符
- 方法的名稱和描述符
現在我們知道了class文件中常量池的作用:存放編譯器生成的各種字面量(Literal)和符號引用(Symbolic References)。很多時候知道了一個東西的概念並不能說你會了,對於程序員而言,如果你說你已經會了,那麼最好的證明是你能夠通過代碼將其描述出來,所以,接下來,我想以一種直觀的方式讓大家感受到常量池的存在。通過分析一段簡單代碼的字節碼,讓大家能更好感知常量池的作用。
talk is cheap ,show me code
我們以下面這段代碼為例,通過javap來查看class文件中的具體內容,代碼如下:
/**
* @author 程序員DMZ
* @Date Create in 22:59 2020/6/15
* @公眾號 微信搜索:程序員DMZ
*/
public class Main {
public static void main(String[] args) {
String name = "dmz";
}
}
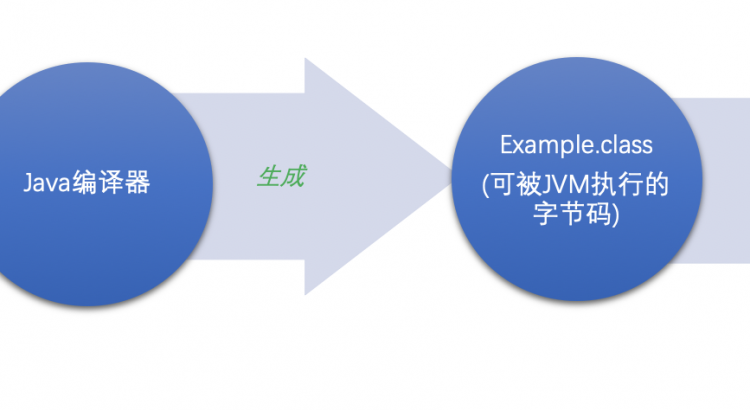
進入Main.java文件所在目錄,執行命令:javac Main.java ,那麼此時會在當前目錄下生成對應的Main.class文件。再執行命令:javap -v -c Main.class,此時會得到如下的解析后的字節碼信息
public class com.dmz.jvm.Main
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
// 這裏就是常量池了
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
#2 = String #21 // dmz
#3 = Class #22 // com/dmz/jvm/Main
#4 = Class #23 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/dmz/jvm/Main;
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
#16 = Utf8 name
#17 = Utf8 Ljava/lang/String;
#18 = Utf8 SourceFile
#19 = Utf8 Main.java
#20 = NameAndType #5:#6 // "<init>":()V
#21 = Utf8 dmz
#22 = Utf8 com/dmz/jvm/Main
#23 = Utf8 java/lang/Object
// 下面是方法表
{
public com.dmz.jvm.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 7: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/dmz/jvm/Main;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
// 可以看到方法表中的指令引用了常量池中的常量,這也是為什麼說常量池是資源倉庫的原因
// 因為它會被class文件中的其它結構引用
0: ldc #2 // String dmz
2: astore_1
3: return
LineNumberTable:
line 9: 0
line 10: 3
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 args [Ljava/lang/String;
3 1 1 name Ljava/lang/String;
}
SourceFile: "Main.java"
在上面的字節碼中,我們暫且關注常量池中的內容即可。主要看這兩行
#2 = String #14 // dmz
#14 = Utf8 dmz
如果要看懂這兩行代碼,我們需要對常量池中String類型常量的結構有一定了解,其結構如下:
| CONSTANT_String_info |
tag |
標誌常量類型的標籤 |
|
index |
指向字符串字面量的索引 |
對應到我們上面的字節碼中,tag=String,index=#14,所以我們可以知道,#2是一個字面量為#14的字符串類型常量。而#14對應的字面量信息(一個Utf8類型的常量)就是dmz。
常量池作為資源倉庫,最大的用處在於被class文件中的其它結構所引用,這個時候我們再將注意力放到main方法上來,對應的就是這三條指令
0: ldc #2 // String dmz
2: astore_1
3: return
ldc:這個指令的作用是將對應的常量的引用壓入操作數棧,在執行ldc指令時會觸發對它的符號引用進行解析,在上面例子中對應的符號引用就是#2,也就是常量池中的第二個元素(這裏就能看出方法表中就引用了常量池中的資源)
astore_1:將操作數棧底元素彈出,存儲到局部變量表中的1號元素
return:方法返回值為void,標誌方法執行完成,將方法對應棧幀從棧中彈出
下面我用畫圖的方式來畫出整個流程,主要分為四步
-
解析ldc指令的符號引用(#2)
-
將#2對應的常量的引用壓入到操作數棧頂
-
將操作數棧的元素彈出並存儲到局部變量表中
-
執行return指令,方法執行結束,彈出棧區該方法對應的棧幀
第一步:
在解析#2這個符號引用時,會先到字符串常量池中查找是否存在對應字符串實例的引用,如果有的話,那麼直接返回這個字符串實例的引用,如果沒有的話,會創建一個字符串實例,那麼將其添加到字符串常量池中(實際上是將其引用放入到一個哈希表中),之後再返回這個字符串實例對象的引用。
到這裏也能回答我們之前提出的那個問題了,一個對象是new出來的,另外一個是在解析常量池的時候JVM自動創建的
第二步:
將第一步得到的引用壓入到操作數棧,此時這個字符串實例同時被操作數棧以及字符串常量池引用。
第三步:
操作數棧中的引用彈出,並賦值給局部變量表中的1號位置元素,到這一步其實執行完了String name = "dmz"這行代碼。此時局部變量表中儲存着一個指向堆中字符串實例的引用,並且這個字符串實例同時也被字符串常量池引用。
第四步:
這一步我就不畫圖了,就是方法執行完成,棧幀彈出,非常簡單。
在上文中,我多次提到了字符串常量池,它到底是個什麼東西呢?我們還是分為兩部分討論
- 位置在哪?
- 用來干什麼的?
字符串常量池
位置在哪?
字符串常量池比較特殊,在JDK1.7之前,其存在於永久代中,到JDK1.7及之後,已經中永久代移到了堆中。當然,如果你非要說永久代也是堆的一部分那我也沒辦法。
另外還要說明一點,經常有同學會將方法區,元空間,永久代(permgen space)的概念混淆。請注意
方法區是JVM在內存分配時需要遵守的規範,是一個理論,具體的實現可以因人而異永久代是hotspot 的jdk1.8以前對方法區的實現,使用jdk1.7的老司機肯定以前經常遇到過java.lang.OutOfMemoryError: PremGen space異常。這裏的PermGen space其實指的就是方法區。不過方法區和PermGen space又有着本質的區別。前者是JVM的規範,而後者則是JVM規範的一種實現,並且只有HotSpot才有PermGen space。元空間是jdk1.8對方法區的實現,jdk1.8徹底移除了永久代,其實,移除永久代的工作從JDK 1.7就開始了。JDK 1.7中,存儲在永久代的部分數據就已經轉移到Java Heap或者Native Heap。但永久代仍存在於JDK 1.7中,並沒有完全移除,譬如符號引用(Symbols)轉移到了native heap;字面量(interned strings)轉移到了Java heap;類的靜態變量(class statics)轉移到了Java heap。到jdk1.8徹底移除了永久代,將JDK7中還剩餘的永久代信息全部移到元空間,元空間相比對永久代最大的差別是,元空間使用的是本地內存(Native Memory)。
用來干什麼的?
字符串常量池,顧名思義,肯定就是用來存儲字符串的嘛,準確來說存儲的是字符串實例對象的引用。我查閱了很多博客、資料,它們都會說,字符串常量池中存儲的就是字符串對象。其實我們可以類比下面這段代碼:
HashSet<Person> persons = new HashSet<Person>;
在persons這個集合中,存儲的是Person對象還是Person對象對應的引用呢?
所以,請大聲跟我念三遍
字符串常量池存儲的是字符串實例對象的引用!
字符串常量池存儲的是字符串實例對象的引用!
字符串常量池存儲的是字符串實例對象的引用!
下面我們來看R大博文下評論的一段話:
簡單來說,HotSpot VM里StringTable是個哈希表,裏面存的是駐留字符串的引用(而不是駐留字符串實例自身)。也就是說某些普通的字符串實例被這個StringTable引用之後就等同被賦予了“駐留字符串”的身份。這個StringTable在每個HotSpot VM的實例里只有一份,被所有的類共享。類的運行時常量池裡的CONSTANT_String類型的常量,經過解析(resolve)之後,同樣存的是字符串的引用;解析的過程會去查詢StringTable,以保證運行時常量池所引用的字符串與StringTable所引用的是一致的。
——R大博客
從上面我們可以知道
- 字符串常量池本質就是一個哈希表
- 字符串常量池中存儲的是字符串實例的引用
- 字符串常量池在被整個JVM共享
- 在解析運行時常量池中的符號引用時,會去查詢字符串常量池,確保運行時常量池中解析后的直接引用跟字符串常量池中的引用是一致的
為了更好理解上面的內容,我們需要去分析String中的一個方法—–intern()
intern方法分析
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class <code>String</code>.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this <code>String</code> object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this <code>String</code> object is added to the
* pool and a reference to this <code>String</code> object is returned.
* <p>
* It follows that for any two strings <code>s</code> and <code>t</code>,
* <code>s.intern() == t.intern()</code> is <code>true</code>
* if and only if <code>s.equals(t)</code> is <code>true</code>.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
String#intern方法中看到,這個方法是一個 native 的方法,但註釋寫的非常明了。“如果常量池中存在當前字符串, 就會直接返回當前字符串. 如果常量池中沒有此字符串, 會將此字符串放入常量池中后, 再返回”。
關於其詳細的分析可以參考:美團:深入解析String#intern
珠玉在前,所以本文着重就分析下intern方法在JDK不同版本下的差異,首先我們要知道引起差異的原因是因為JDK1.7及之後將字符串常量池從永久代挪到了堆中。
我這裏就以美團文章中的示例代碼來進行分析,代碼如下:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
打印結果是
- jdk6 下
false false
- jdk7 下
false true
在美團的文章中已經對這個結果做了詳細的解釋,接下來我就用我的圖解方式再分析一波這個過程
jdk6 執行流程
第一步:執行 String s = new String("1"),要清楚這行代碼的執行過程,我們還是得從字節碼入手,這行代碼對應的字節碼如下:
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String 1
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: return
new :創建了一個類的實例(還沒有調用構造器函數),並將其引用壓入操作數棧頂
dup:複製棧頂數值並將複製值壓入棧頂,這是因為invokespecial跟astore_1各需要消耗一個引用
ldc:解析常量池符號引用,將實際的直接引用壓入操作數棧頂
invokespecial:彈出此時棧頂的常量引用及對象引用,執行invokespecial指令,調用構造函數
astore_1:將此時操作數棧頂的元素彈出,賦值給局部變量表中1號元素(0號元素存的是main函數的參數)
我們可以將上面整個過程分為兩個階段
- 解析常量
- 調用構造函數創建對象並返回引用
在解析常量的過程中,因為該字符串常量是第一次解析,所以會先在永久代中創建一個字符串實例對象,並將其引用添加到字符串常量池中。此時內存狀態如下:
當真正通過new方式創建對象完成后,對應的內存狀態如下,因為在分析class文件中的常量池的時候已經對棧區做了詳細的分析,所以這裏就省略一些細節了,在執行完這行代碼后,棧區存在一個引用,指向 了堆區的一個字符串實例內存狀態對應如下:
第二步:緊接着,我們調用了s的intern方法,對應代碼就是 s.intern()
當intern方法執行時,因為此時字符串常量池中已經存在了一個字面量信息跟s相同的字符串的引用,所以此時內存狀態不會發生任何改變。
第三步:執行String s2 = "1",此時因為常量池中已經存在了字面量1的對應字符串實例的引用,所以,這裏就直接返回了這個引用並且賦值給了局部變量s2。對應的內存狀態如下:
到這裏就很清晰了,s跟s2指向兩個不同的對象,所以s==s2肯定是false嘛~
如果看過美團那篇文章的同學可能會有些疑惑,我在圖中對常量池的描述跟美團文章圖中略有差異,在美團那篇文章中,直接將具體的字符串實例放到了字符串常量池中,而在我上面的圖中,字符串常量池存的永遠時引用,它的圖是這樣畫的
就我查閱的資料而言,我個人不贊同這種說法,常量池中應該保存的僅僅是引用。關於這個問題,我已經向美團的團隊進行了留言,也請大佬出來糾錯!
接着我們分析s3跟s4,對應的就是這幾行代碼:
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
我們一行行分析,看看執行完后,內存的狀態是什麼樣的
第一步:String s3 = new String("1") + new String("1"),執行完成后,堆區多了兩個匿名對象,這個我們不用多關注,另外堆區還多了一個字面量為11的字符串實例,並且棧中存在一個引用指向這個實例
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-NVeeWKoO-1592334452491)(upload\image-20200617020742618.png)]
實際上上圖中還少了一個匿名的StringBuilder的對象,這是因為當我們在進行字符串拼接時,編譯器默認會創建一個StringBuilder對象並調用其append方法來進行拼接,最後再調用其toString方法來轉換成一個字符串,StringBuilder的toString方法其實就是new一個字符串
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
這也是為什麼在圖中會說在堆上多了一個字面量為11的字符串實例的原因,因為實際上就是new出來的嘛!
第二步:s3.intern()
調用intern方法后,因為字符串常量池中目前沒有11這個字面量對應的字符串實例的應用,所以JVM會先從堆區複製一個字符串實例到永久代中,再將其引用添加到字符串常量池中,最終的內存狀態就如下所示
第三步:String s4 = "11"
這應該沒啥好說的了吧,常量池中有了,直接指向對應的字符串實例
到這裏可以發現,s3跟s4指向的根本就是兩個不同的對象,所以也返回false
jdk7 執行流程
在jdk1.7中,s跟s2的執行結果還是一樣的,這是因為 String s = new String("1")這行代碼本身就創建了兩個字符串對象,一個屬於被常量池引用的駐留字符串,而另外一個只是堆上的一個普通字符串對象。跟1.6的區別在於,1.7中的駐留字符串位於堆上,而1.6中的位於方法區中,但是本質上它們還是兩個不同的對象,在下面代碼執行完后
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
內存狀態為:
但是對於s3跟s4確不同了,因為在jdk1.7中不會再去複製字符串實例了,在intern方法執行時在發現堆上有對應的對象之後,直接將這個對應的引用添加到字符串常量池中,所以代碼執行完,內存狀態對應如下:
看到了吧,s3跟s4指向的同一個對象,這是因為intern方法執行時,直接s3這個引用複製到了常量池,之後執行String s4= "11"的時候,直接再將常量池中的引用複製給了s4,所以s3==s4肯定為true啦。
在理解了它們之間的差異之後,我們再來思考一個問題,假設我現在將代碼改成這個樣子,那麼運行結果是什麼樣的呢?
public static void main(String[] args) {
String s = new String("1");
String sintern = s.intern();
String s2 = "1";
System.out.println(sintern == s2);
String s3 = new String("1") + new String("1");
String s3intern = s3.intern();
String s4 = "11";
System.out.println(s3intern == s4);
}
上面這段代碼運行起來結果會有差異嗎?大家可以自行思考~
在我們對字符串常量池有了一定理解之後會發現,其實通過String name = "dmz"這行代碼申明一個字符串,實際的執行邏輯就像下面這段偽代碼所示
/**
* 這段代碼邏輯類比於
* <code>String s = "字面量"</code>;這種方式申明一個字符串
* 其中字面量就是在""中的值
*
*/
public String declareString(字面量) {
String s;
// 這是一個偽方法,標明會根據字面量的值到字符串值中查找是否存在對應String實例的引用
s = findInStringTable(字面量);
// 說明字符串池中已經存在了這個引用,那麼直接返回
if (s != null) {
return s;
}
// 不存在這個引用,需要新建一個字符串實例,然後調用其intern方法將其拘留到字符串池中,
// 最後返回這個新建字符串的引用
s = new String(字面量);
// 調用intern方法,將創建好的字符串放入到StringTable中,
// 類似就是調用StringTable.add(s)這也的一個偽方法
s.intern();
return s;
}
按照這個邏輯,我們將我們將上面思考題中的所有字面量進行替換,會發現不管在哪個版本中結果都應該返回true。
運行時常量池
位置在哪?
位於方法區中,1.6在永久代,1.7在元空間中,永久代跟元空間都是對方法區的實現
用來干什麼?
jvm在執行某個類的時候,必須經過加載、連接、初始化,而連接又包括驗證# 位置在哪?
位於方法區中,1.6在永久代,1.7在元空間中,永久代跟元空間都是對方法區的實現
用來干什麼?
jvm在執行某個類的時候,必須經過加載、連接、初始化,而連接又包括驗證、準備、解析三個階段。而當類加載到內存中后,jvm就會將class常量池中的內容存放到運行時常量池中,由此可知,運行時常量池也是每個類都有一個。在上面我也說了,class常量池中存的是字面量和符號引用,也就是說他們存的並不是對象的實例,而是對象的符號引用值。而經過解析(resolve)之後,也就是把符號引用替換為直接引用,解析的過程會去查詢全局字符串池,也就是我們上面所說的StringTable,以保證運行時常量池所引用的字符串與全局字符串池中所引用的是一致的。
所以簡單來說,運行時常量池就是用來存放class常量池中的內容的。
總結
我們將三者進行一個比較
以一道測試題結束
// 環境1.7及以上
public class Clazz {
public static void main(String[] args) {
String s1 = new StringBuilder().append("ja").append("va1").toString();
String s2 = s1.intern();
System.out.println(s1==s2);
String s5 = "dmz";
String s3 = new StringBuilder().append("d").append("mz").toString();
String s4 = s3.intern();
System.out.println(s3 == s4);
String s7 = new StringBuilder().append("s").append("pring").toString();
String s8 = s7.intern();
String s6 = "spring";
System.out.println(s7 == s8);
}
}
答案是true,false,true。大家可以仔細思考為什麼,如有疑惑可以給我留言,或者進群交流!
如果本文對你有幫助的話,記得點個贊吧!也歡迎關注我的公眾號,微信搜索:程序員DMZ,或者掃描下方二維碼,跟着我一起認認真真學Java,踏踏實實做一個coder。
我叫DMZ,一個在學習路上匍匐前行的小菜鳥!
參考文章:
R大博文:請別再拿“String s = new String(“xyz”);創建了多少個String實例”來面試了吧
R大知乎回答:JVM 常量池中存儲的是對象還是引用呢?
Java中幾種常量池的區分
方法區,永久代和元空間
美團:深入解析String#intern
參考書籍:
《深入理解Java虛擬機》第二版
《深入理解Java虛擬機》第三版
《Java虛擬機規範》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心