jdk1.7中的底層實現過程(底層基於數組+鏈表)
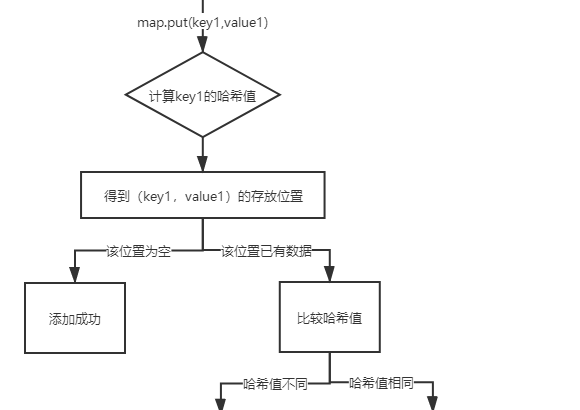
在我們new HashMap()時,底層創建了默認長度為16的一維數組Entry[ ] table。當我們調用map.put(key1,value1)方法向HashMap里添加數據的時候:
首先,調用key1所在類的hashCode()計算key1的哈希值,通過key1的hash值與數組的最大索引進行位運算以後,得到了在 Entry數組中的存放位置:
如果此位置上的數據為空,此時的key1-value1添加成功。
如果此位置上的數據不為空(意味着此位置已經存在一個或多個數據),比較key1和已經存在的一個或多個數據的哈希值:
如果key1的哈希值與已經存在的數據的哈希值都不相同,此時key1-value1添加成功。
如果key1的哈希值與已經存在的數據的某一個數據的哈希值相同,繼續比較:調用key1所在類的equals()方法:
如果equals()返回false,此時key1-value1添加成功;
如果equals()返回true,使用value1替換value2。
需要注意的是,若原來位置已有數據,則此時key1-value1和原來的數據以鏈表的方式存儲。
在不斷的添加過程中,會涉及到擴容問題,當數組容量大於數組現有長度乘以加載因子(如16*0.75,默認的加載因子為0.75)的時候,就會進行數組擴容,以減少哈希衝突(哈希衝突是指哈希函數算出來的地址被別的元素佔用了),提高查詢效率。默認的擴容方式,擴容為原來容量的2倍,並將原有的數據複製過來。
jdk1.8的底層實現過程(底層基於數組+鏈表+紅黑樹)
jdk1.8與jdk1.7中底層的創建過程相似,但有不同,首先,new HashMap()底層沒有創建出一個長度為16的數組,在調用put()方法時,判斷數組是否存在,如果不存在創建長度為16的Node[ ]數組。接下來的過程與jdk1.7相似。最後,當某一個索引位置上的元素以鏈表形式存在的數據個數>8且當前數組的長度>64時,此時此索引位置上的所有數據改為使用紅黑樹存儲。
在jdk1.7中,即使在“數組容量大於數組現有長度乘以加載因子”時擴容,也不可避免地會有哈希衝突存在,因此,在jdk1.8中引入紅黑樹是為了進一步減少哈希衝突,提高查詢效率。
紅黑樹是一種自平衡的二叉查找樹,是一種數據結構,典型的用途是實現關聯數組。根節點必須是黑色,其他每個節點要麼是紅色,要麼是黑色。
結論:HashMap鍵是不能重複的,去除重複的條件是依賴鍵的hashCode方法和equals方法,如果鍵是自己的對象類型,必須要重寫hashCode方法和equals方法,否則,不能去除重複的鍵。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案