Kubernetes簡介
Kubernetes是谷歌嚴格保密十幾年的秘密武器—Borg的一個開源版本,是Docker分佈式系統解決方案.2014年由Google公司啟動.
Kubernetes提供了面嚮應用的容器集群部署和管理系統。Kubernetes的目標旨在消除編排物理/虛擬計算,網絡和存儲基礎設施的負擔,並使應用程序運營商和開發人員完全將重點放在以容器為中心的原語上進行自助運營。Kubernetes 也提供穩定、兼容的基礎(平台),用於構建定製化的workflows 和更高級的自動化任務。 Kubernetes 具備完善的集群管理能力,包括多層次的安全防護和准入機制、多租戶應用支撐能力、透明的服務註冊和服務發現機制、內建負載均衡器、故障發現和自我修復能力、服務滾動升級和在線擴容、可擴展的資源自動調度機制、多粒度的資源配額管理能力。 Kubernetes 還提供完善的管理工具,涵蓋開發、部署測試、運維監控等各個環節。
Kubernetes作為雲原生應用的基石,相當於一個雲操作系統,其重要性不言而喻。
容器編排
容器編排引擎三足鼎立:
Mesos
Docker Swarm+compose
Kubernetes
早在 2015 年 5 月,Kubernetes 在 Google 上的搜索熱度就已經超過了 Mesos 和 Docker Swarm,從那兒之後更是一路飆升,將對手甩開了十幾條街,容器編排引擎領域的三足鼎立時代結束。
目前,AWS、Azure、Google、阿里雲、騰訊雲等主流公有雲提供的是基於 Kubernetes 的容器服務;Rancher、CoreOS、IBM、Mirantis、Oracle、Red Hat、VMWare 等無數廠商也在大力研發和推廣基於 Kubernetes 的容器 CaaS 或 PaaS 產品。可以說,Kubernetes 是當前容器行業最炙手可熱的明星。
Google 的數據中心裏運行着超過 20 億個容器,而且 Google 十年前就開始使用容器技術。
最初,Google 開發了一個叫 Borg 的系統(現在命名為 Omega)來調度如此龐大數量的容器和工作負載。在積累了這麼多年的經驗后,Google 決定重寫這個容器管理系統,並將其貢獻到開源社區,讓全世界都能受益。這個項目就是 Kubernetes。簡單的講,Kubernetes 是 Google Omega 的開源版本。
跟很多基礎設施領域先有工程實踐、後有方法論的發展路線不同,Kubernetes 項目的理論基礎則要比工程實踐走得靠前得多,這當然要歸功於 Google 公司在 2015 年 4 月發布的 Borg 論文了。
Borg 系統,一直以來都被譽為 Google 公司內部最強大的”秘密武器”。雖然略顯誇張,但這個說法倒不算是吹牛。
因為,相比於 Spanner、BigTable 等相對上層的項目,Borg 要承擔的責任,是承載 Google 公司整個基礎設施的核心依賴。在 Google 公司已經公開發表的基礎設施體系論文中,Borg 項目當仁不讓地位居整個基礎設施技術棧的最底層。
由於這樣的定位,Borg 可以說是 Google 最不可能開源的一個項目。而幸運地是,得益於 Docker 項目和容器技術的風靡,它卻終於得以以另一種方式與開源社區見面,這個方式就是 Kubernetes 項目。
所以,相比於”小打小鬧”的 Docker 公司、”舊瓶裝新酒”的 Mesos 社區,Kubernetes 項目從一開始就比較幸運地站上了一個他人難以企及的高度:在它的成長階段,這個項目每一個核心特性的提出,幾乎都脫胎於 Borg/Omega 系統的設計與經驗。更重要的是,這些特性在開源社區落地的過程中,又在整個社區的合力之下得到了極大的改進,修復了很多當年遺留在 Borg 體系中的缺陷和問題。
所以,儘管在發布之初被批評是”曲高和寡”,但是在逐漸覺察到 Docker 技術棧的”稚嫩”和 Mesos 社區的”老邁”之後,這個社區很快就明白了:k8s 項目在 Borg 體系的指導下,體現出了一種獨有的”先進性”與”完備性”,而這些特質才是一個基礎設施領域開源項目賴以生存的核心價值。
什麼是編排
一個正在運行的 Linux 容器,可以分成兩部分看待
1 . 容器的靜態視圖
一組聯合掛載在 /var/lib/docker/aufs/mnt 上的 rootfs,這一部分稱為”容器鏡像”(Container Image)
2 . 容器的動態視圖
一個由 Namespace+Cgroups 構成的隔離環境,這一部分稱為”容器運行時”(Container Runtime)
作為一名開發者,其實並不關心容器運行時的差異。在整個”開發 – 測試 – 發布”的流程中,真正承載着容器信息進行傳遞的,是容器鏡像,而不是容器運行時。
這正是容器技術圈在 Docker 項目成功后不久,就迅速走向了”容器編排”這個”上層建築”的主要原因:作為一家雲服務商或者基礎設施提供商,我只要能夠將用戶提交的 Docker 鏡像以容器的方式運行起來,就能成為這個非常熱鬧的容器生態圖上的一個承載點,從而將整個容器技術棧上的價值,沉澱在我的這個節點上。
更重要的是,只要從這個承載點向 Docker 鏡像製作者和使用者方向回溯,整條路徑上的各個服務節點,比如 CI/CD、監控、安全、網絡、存儲等等,都有可以發揮和盈利的餘地。這個邏輯,正是所有雲計算提供商如此熱衷於容器技術的重要原因:通過容器鏡像,它們可以和潛在用戶(即,開發者)直接關聯起來。
從一個開發者和單一的容器鏡像,到無數開發者和龐大的容器集群,容器技術實現了從”容器”到”容器雲”的飛躍,標志著它真正得到了市場和生態的認可。
這樣,容器就從一個開發者手裡的小工具,一躍成為了雲計算領域的絕對主角;而能夠定義容器組織和管理規範的”容器編排”技術,則當仁不讓地坐上了容器技術領域的”頭把交椅”。
最具代表性的容器編排工具
# 1. Docker 公司的 Compose+Swarm 組合
# 2. Google 與 RedHat 公司共同主導的 Kubernetes 項目
編排工具
Swarm與CoreOS
Docker 公司發布 Swarm 項目
Docker 公司在 2014 年發布 Swarm 項目. 一個有意思的事實:雖然通過”容器”這個概念完成了對經典 PaaS 項目的”降維打擊”,但是 Docker 項目和 Docker 公司,兜兜轉轉了一年多,卻還是回到了 PaaS 項目原本深耕多年的那個戰場:如何讓開發者把應用部署在我的項目上
Docker 項目從發布之初就全面發力,從技術、社區、商業、市場全方位爭取到的開發者群體,實際上是為此後吸引整個生態到自家”PaaS”上的一個鋪墊。只不過這時,”PaaS”的定義已經全然不是 Cloud Foundry 描述的那個樣子,而是變成了一套以 Docker 容器為技術核心,以 Docker 鏡像為打包標準的、全新的”容器化”思路。
這正是 Docker 項目從一開始悉心運作”容器化”理念和經營整個 Docker 生態的主要目的。
Docker 公司在 Docker 項目已經取得巨大成功后,執意要重新走回 PaaS 之路的原因:
雖然 Docker 項目備受追捧,但用戶們最終要部署的,還是他們的網站、服務、數據庫,甚至是雲計算業務。只有那些能夠為用戶提供平台層能力的工具,才會真正成為開發者們關心和願意付費的產品。而 Docker 項目這樣一個只能用來創建和啟停容器的小工具,最終只能充當這些平台項目的”幕後英雄”。
Docker 公司的老朋友和老對手 CoreOS:
CoreOS 是一個基礎設施領域創業公司。 核心產品是一個定製化的操作系統,用戶可以按照分佈式集群的方式,管理所有安裝了這個操作系統的節點。從而,用戶在集群里部署和管理應用就像使用單機一樣方便了。
Docker 項目發布后,CoreOS 公司很快就認識到可以把”容器”的概念無縫集成到自己的這套方案中,從而為用戶提供更高層次的 PaaS 能力。所以,CoreOS 很早就成了 Docker 項目的貢獻者,並在短時間內成為了 Docker 項目中第二重要的力量。
2014 年底,CoreOS 公司與 Docker 公司停止合作,並推出自己研製的 Rocket(後來叫 rkt)容器。
原因是 Docker 公司對 Docker 項目定位的不滿足。Docker 公司的解決方法是讓 Docker 項目提供更多的平台層能力,即向 PaaS 項目進化。這與 CoreOS 公司的核心產品和戰略發生了嚴重衝突。
Docker 公司在 2014 年就已經定好了平台化的發展方向,並且絕對不會跟 CoreOS 在平台層面開展任何合作。這樣看來,Docker 公司在 2014 年 12 月的 DockerCon 上發布 Swarm 的舉動,也就一點都不突然了。
CoreOS 項目
依託於一系列開源項目(比如 Container Linux 操作系統、Fleet 作業調度工具、systemd 進程管理和 rkt 容器),一層層搭建起來的平台產品
Swarm 項目:
以一個完整的整體來對外提供集群管理功能。Swarm 的最大亮點是它完全使用 Docker 項目原本的容器管理 API 來完成集群管理,比如:
單機 Docker 項目
docker run 我的容器
多機 Docker 項目
“docker run -H ” 我的 Swarm 集群 API 地址 ” ” 我的容器 “`
在部署了 Swarm 的多機環境下,用戶只需使用原先的 Docker 指令創建一個容器,這個請求就會被 Swarm 攔截下來處理,然後通過具體的調度算法找到一個合適的 Docker Daemon 運行起來。
這個操作方式簡潔明了,對於已經了解過 Docker 命令行的開發者們也很容易掌握。所以,這樣一個”原生”的 Docker 容器集群管理項目一經發布,就受到了已有 Docker 用戶群的熱捧。相比之下,CoreOS 的解決方案就顯得非常另類,更不用說用戶還要去接受完全讓人摸不着頭腦、新造的容器項目 rkt 了。
Swarm 項目只是 Docker 公司重新定義”PaaS”的關鍵一環。2014 年到 2015 年這段時間里,Docker 項目的迅速走紅催生出了一個非常繁榮的”Docker 生態”。在這個生態里,圍繞着 Docker 在各個層次進行集成和創新的項目層出不窮.
cncf(Fig/Compose)
Fig 項目
被docker收購后改名為 Compose
Fig 項目基本上只是靠兩個人全職開發和維護的,可它卻是當時 GitHub 上熱度堪比 Docker 項目的明星。
Fig 項目受歡迎的原因
是它在開發者面前第一次提出”容器編排”(Container Orchestration)的概念。
“編排”(Orchestration)在雲計算行業里不算是新詞彙,主要是指用戶如何通過某些工具或者配置來完成一組虛擬機以及關聯資源的定義、配置、創建、刪除等工作,然後由雲計算平台按照這些指定的邏輯來完成的過程。
容器時代,”編排”就是對 Docker 容器的一系列定義、配置和創建動作的管理。而 Fig 的工作實際上非常簡單:假如現在用戶需要部署的是應用容器 A、數據庫容器 B、負載均衡容器 C,那麼 Fig 就允許用戶把 A、B、C 三個容器定義在一個配置文件中,並且可以指定它們之間的關聯關係,比如容器 A 需要訪問數據庫容器 B。
接下來,只需執行一條非常簡單的指令:# fig up
Fig 就會把這些容器的定義和配置交給 Docker API 按照訪問邏輯依次創建,一系列容器就都啟動了;而容器 A 與 B 之間的關聯關係,也會交給 Docker 的 Link 功能通過寫入 hosts 文件的方式進行配置。更重要的是,你還可以在 Fig 的配置文件里定義各種容器的副本個數等編排參數,再加上 Swarm 的集群管理能力,一個活脫脫的 PaaS 呼之欲出。
它成了 Docker 公司到目前為止第二大受歡迎的項目,一直到今也依然被很多人使用。
當時的這個容器生態里,還有很多開源項目或公司。比如:
專門負責處理容器網絡的 SocketPlane 項目(後來被 Docker 公司收購)
專門負責處理容器存儲的 Flocker 項目(後來被 EMC 公司收購)
專門給 Docker 集群做圖形化管理界面和對外提供雲服務的 Tutum 項目(後來被 Docker 公司收購)等等。
Mesosphere與Mesos
老牌集群管理項目 Mesos 和它背後的創業公司 Mesosphere:Mesos 社區獨特的競爭力:
超大規模集群的管理經驗
Mesos 早已通過了萬台節點的驗證,2014 年之後又被廣泛使用在 eBay 等大型互聯網公司的生產環境中。
Mesos 是 Berkeley 主導的大數據套件之一,是大數據火熱時最受歡迎的資源管理項目,也是跟 Yarn 項目殺得難捨難分的實力派选手。
大數據所關注的計算密集型離線業務,其實並不像常規的 Web 服務那樣適合用容器進行託管和擴容,也沒有對應用打包的強烈需求,所以 Hadoop、Spark 等項目到現在也沒在容器技術上投下更大的賭注;
但對於 Mesos 來說,天生的兩層調度機制讓它非常容易從大數據領域抽身,轉而去支持受眾更加廣泛的 PaaS 業務。
在這種思路指導下,Mesosphere 公司發布了一個名為 Marathon 的項目,這個項目很快就成為 Docker Swarm 的一個有力競爭對手。
通過 Marathon 實現了諸如應用託管和負載均衡的 PaaS 功能之後,Mesos+Marathon 的組合實際上進化成了一個高度成熟的 PaaS 項目,同時還能很好地支持大數據業務。
Mesosphere 公司提出”DC/OS”(數據中心操作系統)的口號和產品:
旨在使用戶能夠像管理一台機器那樣管理一個萬級別的物理機集群,並且使用 Docker 容器在這個集群里自由地部署應用。這對很多大型企業來說具有着非同尋常的吸引力。
這時的容器技術生態, CoreOS 的 rkt 容器完全打不開局面,Fleet 集群管理項目更是少有人問津,CoreOS 完全被 Docker 公司壓制了。
RedHat 也是因為對 Docker 公司平台化戰略不滿而憤憤退出。但此時,它竟只剩下 OpenShift 這個跟 Cloud Foundry 同時代的經典 PaaS 一張牌可以打,跟 Docker Swarm 和轉型后的 Mesos 完全不在同一個”競技水平”之上。
google與k8s
2014 年 6 月,基礎設施領域的翹楚 Google 公司突然發力,正宣告了一個名叫 Kubernetes 項目的誕生。這個項目,不僅挽救了當時的 CoreOS 和 RedHat,還如同當年 Docker 項目的橫空出世一樣,再一次改變了整個容器市場的格局。
這段時間,也正是 Docker 生態創業公司們的春天,大量圍繞着 Docker 項目的網絡、存儲、監控、CI/CD,甚至 UI 項目紛紛出台,也湧現出了很多 Rancher、Tutum 這樣在開源與商業上均取得了巨大成功的創業公司。
在 2014~2015 年間,整個容器社區可謂熱鬧非凡。
這令人興奮的繁榮背後,卻浮現出了更多的擔憂。這其中最主要的負面情緒,是對 Docker 公司商業化戰略的種種顧慮。
事實上,很多從業者也都看得明白,Docker 項目此時已經成為 Docker 公司一個商業產品。而開源,只是 Docker 公司吸引開發者群體的一個重要手段。不過這麼多年來,開源社區的商業化其實都是類似的思路,無非是高不高調、心不心急的問題罷了。
而真正令大多數人不滿意的是,Docker 公司在 Docker 開源項目的發展上,始終保持着絕對的權威和發言權,並在多個場合用實際行動挑戰到了其他玩家(比如,CoreOS、RedHat,甚至谷歌和微軟)的切身利益。
那麼,這個時候,大家的不滿也就不再是在 GitHub 上發發牢騷這麼簡單了。
相信很多容器領域的老玩家們都聽說過,Docker 項目剛剛興起時,Google 也開源了一個在內部使用多年、經歷過生產環境驗證的 Linux 容器:lmctfy(Let Me Container That For You)。
然而,面對 Docker 項目的強勢崛起,這個對用戶沒那麼友好的 Google 容器項目根本沒有招架之力。所以,知難而退的 Google 公司,向 Docker 公司表示了合作的願望:關停這個項目,和 Docker 公司共同推進一个中立的容器運行時(container runtime)庫作為 Docker 項目的核心依賴。
不過,Docker 公司並沒有認同這個明顯會削弱自己地位的提議,還在不久后,自己發布了一個容器運行時庫 Libcontainer。這次匆忙的、由一家主導的、並帶有戰略性考量的重構,成了 Libcontainer 被社區長期詬病代碼可讀性差、可維護性不強的一個重要原因。
至此,Docker 公司在容器運行時層面上的強硬態度,以及 Docker 項目在高速迭代中表現出來的不穩定和頻繁變更的問題,開始讓社區叫苦不迭。
這種情緒在 2015 年達到了一個高潮,容器領域的其他幾位玩家開始商議”切割”Docker 項目的話語權。而”切割”的手段也非常經典,那就是成立一个中立的基金會。
於是,2015 年 6 月 22 日,由 Docker 公司牽頭,CoreOS、Google、RedHat 等公司共同宣布,Docker 公司將 Libcontainer 捐出,並改名為 RunC 項目,交由一個完全中立的基金會管理,然後以 RunC 為依據,大家共同制定一套容器和鏡像的標準和規範。
這套標準和規範,就是 OCI( Open Container Initiative )。OCI 的提出,意在將容器運行時和鏡像的實現從 Docker 項目中完全剝離出來。這樣做,一方面可以改善 Docker 公司在容器技術上一家獨大的現狀,另一方面也為其他玩家不依賴於 Docker 項目構建各自的平台層能力提供了可能。
不過,OCI 的成立更多的是這些容器玩家出於自身利益進行干涉的一個妥協結果。儘管 Docker 是 OCI 的發起者和創始成員,它卻很少在 OCI 的技術推進和標準制定等事務上扮演關鍵角色,也沒有動力去积極地推進這些所謂的標準。
這也是迄今為止 OCI 組織效率持續低下的根本原因。
OCI 並沒能改變 Docker 公司在容器領域一家獨大的現狀,Google 和 RedHat 等公司於是把第二把武器擺上了檯面。
Docker 之所以不擔心 OCI 的威脅,原因就在於它的 Docker 項目是容器生態的事實標準,而它所維護的 Docker 社區也足夠龐大。可是,一旦這場鬥爭被轉移到容器之上的平台層,或者說 PaaS 層,Docker 公司的競爭優勢便立刻捉襟見肘了。
在這個領域里,像 Google 和 RedHat 這樣的成熟公司,都擁有着深厚的技術積累;而像 CoreOS 這樣的創業公司,也擁有像 Etcd 這樣被廣泛使用的開源基礎設施項目。
可是 Docker 公司卻只有一個 Swarm。
所以這次,Google、RedHat 等開源基礎設施領域玩家們,共同牽頭髮起了一個名為 CNCF(Cloud Native Computing Foundation)的基金會。這個基金會的目的其實很容易理解:它希望,以 Kubernetes 項目為基礎,建立一個由開源基礎設施領域廠商主導的、按照獨立基金會方式運營的平台級社區,來對抗以 Docker 公司為核心的容器商業生態。
為了打造出一個圍繞 Kubernetes 項目的”護城河”,CNCF 社區就需要至少確保兩件事情:
# 1. Kubernetes 項目必須能夠在容器編排領域取得足夠大的競爭優勢
# 2. CNCF 社區必須以 Kubernetes 項目為核心,覆蓋足夠多的場景
CNCF 社區如何解決 Kubernetes 項目在編排領域的競爭力的問題:
在容器編排領域,Kubernetes 項目需要面對來自 Docker 公司和 Mesos 社區兩個方向的壓力。Swarm 和 Mesos 實際上分別從兩個不同的方向講出了自己最擅長的故事:Swarm 擅長的是跟 Docker 生態的無縫集成,而 Mesos 擅長的則是大規模集群的調度與管理。
這兩個方向,也是大多數人做容器集群管理項目時最容易想到的兩個出發點。也正因為如此,Kubernetes 項目如果繼續在這兩個方向上做文章恐怕就不太明智了。
Kubernetes 選擇的應對方式是:Borg
k8s 項目大多來自於 Borg 和 Omega 系統的內部特性,這些特性落到 k8s 項目上,就是 Pod、Sidecar 等功能和設計模式。
這就解釋了,為什麼 Kubernetes 發布后,很多人”抱怨”其設計思想過於”超前”的原因:Kubernetes 項目的基礎特性,並不是幾個工程師突然”拍腦袋”想出來的東西,而是 Google 公司在容器化基礎設施領域多年來實踐經驗的沉澱與升華。這正是 Kubernetes 項目能夠從一開始就避免同 Swarm 和 Mesos 社區同質化的重要手段。
CNCF 接下來的任務是如何把這些先進的思想通過技術手段在開源社區落地,並培育出一個認同這些理念的生態?
RedHat 發揮了重要作用。當時,Kubernetes 團隊規模很小,能夠投入的工程能力十分緊張,這恰恰是 RedHat 的長處。RedHat 更是世界上為數不多、能真正理解開源社區運作和項目研發真諦的合作夥伴。
RedHat 與 Google 聯盟的成立,不僅保證了 RedHat 在 Kubernetes 項目上的影響力,也正式開啟了容器編排領域”三國鼎立”的局面。
Mesos 社區與容器技術的關係,更像是”借勢”,而不是這個領域真正的參与者和領導者。這個事實,加上它所屬的 Apache 社區固有的封閉性,導致了 Mesos 社區雖然技術最為成熟,卻在容器編排領域鮮有創新。
一開始,Docker 公司就把應對 Kubernetes 項目的競爭擺在首要位置:
一方面,不斷強調”Docker Native”的”重要性”
一方面,與 k8s 項目在多個場合進行了直接的碰撞。這次競爭的發展態勢,很快就超過了 Docker 公司的預期。
Kubernetes 項目並沒有跟 Swarm 項目展開同質化的競爭
所以 “Docker Native”的說辭並沒有太大的殺傷力
相反 k8s 項目讓人耳目一新的設計理念和號召力,很快就構建出了一個與眾不同的容器編排與管理的生態。Kubernetes 項目在 GitHub 上的各項指標開始一騎絕塵,將 Swarm 項目遠遠地甩在了身後.
CNCF 社區如何解決第二個問題:
在已經囊括了容器監控事實標準的 Prometheus 項目后,CNCF 社區迅速在成員項目中添加了 Fluentd、OpenTracing、CNI 等一系列容器生態的知名工具和項目。
而在看到了 CNCF 社區對用戶表現出來的巨大吸引力之後,大量的公司和創業團隊也開始專門針對 CNCF 社區而非 Docker 公司制定推廣策略。
2016 年,Docker 公司宣布了一個震驚所有人的計劃:放棄現有的 Swarm 項目,將容器編排和集群管理功能全部內置到 Docker 項目當中。
Docker 公司意識到了 Swarm 項目目前唯一的競爭優勢,就是跟 Docker 項目的無縫集成。那麼,如何讓這種優勢最大化呢?那就是把 Swarm 內置到 Docker 項目當中。
從工程角度來看,這種做法的風險很大。內置容器編排、集群管理和負載均衡能力,固然可以使得 Docker 項目的邊界直接擴大到一個完整的 PaaS 項目的範疇,但這種變更帶來的技術複雜度和維護難度,長遠來看對 Docker 項目是不利的。
不過,在當時的大環境下,Docker 公司的選擇恐怕也帶有一絲孤注一擲的意味。
k8s 的應對策略
是反其道而行之,開始在整個社區推進”民主化”架構,即:從 API 到容器運行時的每一層,Kubernetes 項目都為開發者暴露出了可以擴展的插件機制,鼓勵用戶通過代碼的方式介入到 Kubernetes 項目的每一個階段。
Kubernetes 項目的這個變革的效果立竿見影,很快在整個容器社區中催生出了大量的、基於 Kubernetes API 和擴展接口的二次創新工作,比如:
目前熱度極高的微服務治理項目 Istio;
被廣泛採用的有狀態應用部署框架 Operator;
還有像 Rook 這樣的開源創業項目,它通過 Kubernetes 的可擴展接口,把 Ceph 這樣的重量級產品封裝成了簡單易用的容器存儲插件。在鼓勵二次創新的整體氛圍當中,k8s 社區在 2016 年後得到了空前的發展。更重要的是,不同於之前局限於”打包、發布”這樣的 PaaS 化路線,這一次容器社區的繁榮,是一次完全以 Kubernetes 項目為核心的”百花爭鳴”。
面對 Kubernetes 社區的崛起和壯大,Docker 公司也不得不面對自己豪賭失敗的現實。但在早前拒絕了微軟的天價收購之後,Docker 公司實際上已經沒有什麼迴旋餘地,只能選擇逐步放棄開源社區而專註於自己的商業化轉型。
所以,從 2017 年開始,Docker 公司先是將 Docker 項目的容器運行時部分 Containerd 捐贈給 CNCF 社區,標志著 Docker 項目已經全面升級成為一個 PaaS 平台;緊接着,Docker 公司宣布將 Docker 項目改名為 Moby,然後交給社區自行維護,而 Docker 公司的商業產品將佔有 Docker 這個註冊商標。
Docker 公司這些舉措背後的含義非常明確:它將全面放棄在開源社區同 Kubernetes 生態的競爭,轉而專註於自己的商業業務,並且通過將 Docker 項目改名為 Moby 的舉動,將原本屬於 Docker 社區的用戶轉化成了自己的客戶。
2017 年 10 月,Docker 公司出人意料地宣布,將在自己的主打產品 Docker 企業版中內置 Kubernetes 項目,這標志著持續了近兩年之久的”編排之爭”至此落下帷幕。
2018 年 1 月 30 日,RedHat 宣布斥資 2.5 億美元收購 CoreOS。
2018 年 3 月 28 日,這一切紛爭的始作俑者,Docker 公司的 CTO Solomon Hykes 宣布辭職,曾經紛紛擾擾的容器技術圈子,到此塵埃落定。
容器技術圈子在短短几年裡發生了很多變數,但很多事情其實也都在情理之中。就像 Docker 這樣一家創業公司,在通過開源社區的運作取得了巨大的成功之後,就不得不面對來自整個雲計算產業的競爭和圍剿。而這個產業的垄斷特性,對於 Docker 這樣的技術型創業公司其實天生就不友好。
在這種局勢下,接受微軟的天價收購,在大多數人看來都是一個非常明智和實際的選擇。可是 Solomon Hykes 卻多少帶有一些理想主義的影子,既然不甘於”寄人籬下”,那他就必須帶領 Docker 公司去對抗來自整個雲計算產業的壓力。
只不過,Docker 公司最後選擇的對抗方式,是將開源項目與商業產品緊密綁定,打造了一個極端封閉的技術生態。而這,其實違背了 Docker 項目與開發者保持親密關係的初衷。相比之下,Kubernetes 社區,正是以一種更加溫和的方式,承接了 Docker 項目的未盡事業,即:以開發者為核心,構建一個相對民主和開放的容器生態。
這也是為何,Kubernetes 項目的成功其實是必然的。
很難想象如果 Docker 公司最初選擇了跟 Kubernetes 社區合作,如今的容器生態又將會是怎樣的一番景象。不過我們可以肯定的是,Docker 公司在過去五年裡的風雲變幻,以及 Solomon Hykes 本人的傳奇經歷,都已經在雲計算的長河中留下了濃墨重彩的一筆。
小結
# 1. 容器技術的興起源於 PaaS 技術的普及;
# 2. Docker 公司發布的 Docker 項目具有里程碑式的意義;
# 3. Docker 項目通過"容器鏡像",解決了應用打包這個根本性難題。
# 容器本身沒有價值,有價值的是"容器編排"。
# 也正因為如此,容器技術生態才爆發了一場關於"容器編排"的"戰爭"。而這次戰爭,最終以 Kubernetes 項目和 CNCF 社區的勝利而告終。
Kubernetes核心概念
什麼是Kubernetes?
Kubernetes是一個完備的分佈式系統支撐平台。
Kubernetes具有完備的集群管理能力,包括多層次的安全防護和准入機制/多租戶應用支撐能力、透明的服務註冊和服務發現機制、內建智能負載均衡器、強大的故障發現和自我修復功能、服務滾動升級和在線擴容能力、可擴展的資源自動調度機制,以及多粒度的資源配額管理能力。同時kubernetes提供了完善的管理工具,這些工具覆蓋了包括開發、測試部署、運維監控在內的各個環節;因此kubernetes是一個全新的基於容器技術的分佈式架構解決方案,並且是一個一站式的完備的分佈式系統開發和支撐平台.
Kubernetes Service介紹
Service是分佈式集群結構的核心,一個Server對象有以下關鍵特徵:
# 1. 擁有一個唯一指定的名字(比如mysql-server)
# 2. 擁有一個虛擬IP(Cluster IP,Service IP或VIP和端口號)
# 3. 能夠提供某種遠程服務能力
# 4. 被映射到了提供這種服務能力的一組容器應用上.
Service的服務進程目前都基於Socker通信方式對外提供服務,比如redis、memcache、MySQL、Web Server,或者是實現了某個具體業務的一個特定的TCP Server進程。雖然一個Service通常由多個相關的服務進程來提供服務,每個服務進程都有一個獨立的Endpoint(IP+Port)訪問點,但Kubernetes 能夠讓我們通過Service
虛擬Cluster IP+Service Port連接到指定的Service上。有了Kubernetes內建的透明負載均衡和故障恢復機制,不管後端有多少服務進程,也不管某個服務進程是否會由於發生故障而重新部署到其他機器,都不會影響到我們對服務的正常調用。更重要的是這個Service本身一旦創建就不再變化,這意味着Kubernetes集群中,我們再也不用為了服務的IP地址變來變去的問題而頭疼。
Kubernetes Pod介紹
Pod概念 Pod運行在一個我們稱之為Node的環境中,可以是私有雲也可以是公有雲的虛擬機或者物理機上,通常在一個節點上運行幾百個Pod,每個Pod運行着一個特殊的稱之為Pause的容器,其他容器則為業務容器,這些業務容器共享着Pause容器的網絡棧和Volume掛載卷,因此他們之間的通訊和數據交換更為高效,在設計時我們充分利用這一特徵將一組密切相關的服務進程放入同一個Pod中.
並不是每個Pod和它裏面的容器都映射到一個Service上,只是那些提供服務(無論是內還是對外)的一組Pod才會被映射成一個服務.
Service和Pod如何關聯
容器提供了強大的隔離功能,所以有必要把Service提供服務的這組容器放入到容器中隔離,Kubernetes設計了Pod服務,將每個服務進程包裝成相應的Pod中,使其成為Pod中運行的一個容器Container,為了建立Service和Pod間的關聯關係,Kubernetes首先給每個Pod貼上了一個標籤Label,給運行Mysql的Pod貼上了name=mysql標籤,給運行PHP貼上name=php標籤,然後給相應的Service定義標籤選擇器Label Selector,比如Mysql Service的標籤選擇器選擇條件為name=mysql,意為該Service要作用於所有包含name=mysql Label的Pod上,這樣就巧妙的解決了Service和Pod關聯的問題.
Kubernetes RC介紹
RC介紹在Kubernetes集群中,你只需要為需要擴容的Service關聯的Pod創建一個RC(Replication Controller),則該Service的擴容以至於後來的Service升級等頭疼問題都可以迎刃而解,定義一個RC文件包含以下3個關鍵點.
# 1. 目標Pod的定義
# 2. 目標Pod需要運行的副本數量(Replicas)
# 3. 要監控的目標Pod的標籤(Label)
在創建好RC系統自動創建號Pod后,Kubernetes會通過RC中定義的Label篩選出對應的Pod實例並監控其狀態和數量,如果實例數量少於定義的副本數量Replicas則會用RC中定義的Pod模板來創建一個新的Pod,然後將Pod調度到合適的Node上運行,直到Pod實例的數量達到預定目標,這個過程完全是自動化的,無需人干預,只需要修改RC中的副本數量即可.
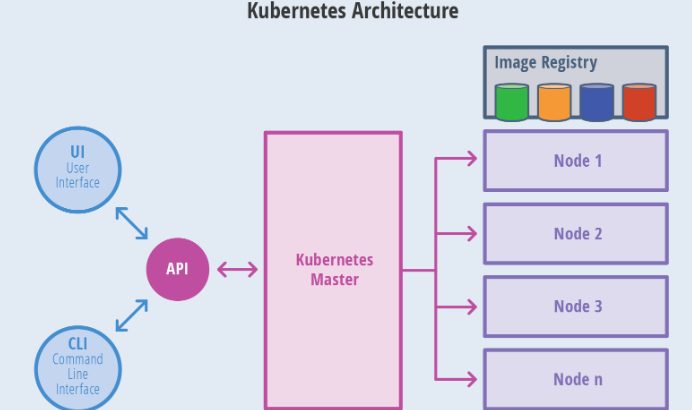
Kubernetes Master介紹
Kubernetes 里的Master指的是集群控制節點,每個Kubernetes集群里需要有一個Master節點來負責整個集群的管理和控制,基本上Kubernetes所有的控制命令都發給它,它負責具體的執行過程,我們後面執行的所有命令基本上都是在Master節點上運行的。如果Master宕機或不可用,那麼集群內容器的管理都將失效.
Master節點上運行一下一組關鍵進程:
- Kubernetes API Server: 提供了HTTP Rest接口的關鍵服務進程,是Kubernetes里所有資源的增刪改查等操作的唯一入口,也是集群控制的入門進程.
- Kubernetes Controller Manager 里所有的資源對象的自動化控制中心.
- Kubernetes Scheduler: 負責資源調度(Pod調度)的進程
另外在Master節點還需要啟動一個etcd服務,因為Kubernetes里所有資源對象的數據全部保存在etcd中.
Kubernetes Node介紹
除了Master,集群中其他機器稱為Node節點,每個Node都會被分配一些工作負載Docker容器,當某個Node宕機,其上的工作負載都會被Master自動轉移到其他節點上去.
每個Node節點上都運行着以下一組關鍵進程
# 1. kubelet: 負責Pod對應的創建、停止等服務,同時與Master節點密切協作,實現集群管理的基本功能.
# 2. kube-proxy: 實現Kubernetes Service的通信與負載均衡機制的重要組件.
# 3. Docker Engine: Docker引擎,負責本機的容器創建和管理工作
在集群管理方面,Kubernetes將集群中的機器劃分為一個Master節點和一群工作節點(Node)中,在Master節點上運行着集群管理相關的一組進程kube-apiserver,kube-controller-manager和kube-scheduler,這些進程實現了整個集群的資源管理,Pod調度,彈性伸縮,安全控制,系統監控和糾錯等管理功能,並且都是全自動完成的、Node作為集群中的工作節點,運行真正的應用程序,在Node上Kubernetes最小運行單元是Pod,Node上運行着Kubernetes的Kubelet、kube-proxy服務進程,這些服務進程負責Pod創建、啟動、監控、重啟、銷毀以及軟件模式的負載均衡.
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!