有一個 ?
遇到這樣一個疑問:當where查詢中In一個索引字段作為條件,那麼在查詢中還會使用到索引嗎?
SELECT * FROM table_name WHERE column_index in (expr)
上面的sql語句檢索會使用到索引嗎?帶着這個問題,在網上查找了很多文章,但是有的說 in 會導致放棄索引,全表掃描;有的說Mysql5.5之前的版本不會走,之後的innodb版本會走索引…
越看越迷糊,那答案到底是怎樣的呢?
唯有實踐是檢驗真理的唯一方式!
拿出我們的利刃——EXPLAIN,去剖析 SELECT 語句,一探究竟!
EXPLAIN 的用法
在 SELECT 語句前加上 EXPLAIN 就可以了 ,例如:
EXPLAIN SELECT * FROM table_name [WHERE Clause]
EXPLAIN 的輸出
EXPLAIN 命令的輸出內容為一個表格形式,表的每一個字段含義如下:
| 列名 | 解釋 |
|---|---|
| id | SELECT 查詢的標識符. 每個 SELECT 都會自動分配一個唯一的標識符 |
| select_type | SELECT 查詢的類型 |
| table | 查詢的是哪個表 |
| partitions | 匹配的分區 |
| type | join 類型 |
| possible_keys | 此次查詢中可能選用的索引 |
| key | 此次查詢中確切使用到的索引 |
| ref | 哪個字段或常數與 key 一起被使用;與索引比較的列 |
| rows | 显示此查詢一共掃描了多少行, 這個是一個估計值 |
| filtered | 表示此查詢條件所過濾的數據的百分比 |
| extra | 額外的信息 |
select_type
| 查詢類型 | 解釋 |
|---|---|
| SIMPLE | 表示此查詢不包含 UNION 查詢或子查詢 |
| PRIMARY | 表示此查詢是最外層的查詢 |
| UNION | 表示此查詢是 UNION 的第二或隨後的查詢 |
| DEPENDENT UNION | UNION 中的第二個或後面的查詢語句, 取決於外面的查詢 |
| UNION RESULT | UNION 的結果 |
| SUBQUERY | 子查詢中的第一個 SELECT |
| DEPENDENT SUBQUERY | 子查詢中的第一個 SELECT,取決於外面的查詢。子查詢依賴於外層查詢的結果 |
| MATERIALIZED | Materialized subquery |
table
表示查詢涉及的表或衍生表 。 這也可以是以下值之一:
- <unionM,N>:該行指的是具有和id值的行 的 M並集 N。
- :該行是指用於與該行的派生表結果id的值 N。派生表可能來自FROM子句中的子查詢 。
- :該行是指該行的物化子查詢的結果,其id 值為N。
partitions
查詢將匹配記錄的分區。該值適用NULL於未分區的表。
type
聯接類型。 提供了判斷查詢是否高效的重要依據依據。通過 type 字段,我們判斷此次查詢是全表掃描還是索引掃描等。 從最佳類型到最差類型:
-
system: 該表只有一行(=系統表)。這是const聯接類型的特例 。
-
const: 針對主鍵或唯一索引的等值查詢掃描,最多只返回一行數據。const 查詢速度非常快,因為它僅僅讀取一次即可 。
SELECT * FROM tbl_name WHERE primary_key=1; SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2; -
eq_ref: 此類型通常出現在多表的 join 查詢,表示對於前表的每一個結果,都只能匹配到后表的一行結果。並且查詢的比較操作通常是 =,查詢效率較高
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
ref : 此類型通常出現在多表的 join 查詢,針對於非唯一或非主鍵索引,或者是使用了最左前綴規則索引的查詢。ref可以用於使用=或<=> 運算符進行比較的索引列。
SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
ref_or_null: 這種連接類型類似於
ref,但是除了MySQL會額外搜索包含NULL值的行。此聯接類型優化最常用於解析子查詢。SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL; -
unique_subquery: 只是一個索引查找函數,它完全替代了子查詢以提高效率。
value IN (SELECT primary_key FROM single_table WHERE some_expr) -
index_subquery:此連接類型類似於 unique_subquery。它代替IN子查詢,但適用於以下形式的子查詢中的非唯一索引。
-
range: 表示使用索引範圍查詢, 通過索引字段範圍獲取表中部分數據記錄。這個類型通常出現在 =,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN,IN() 操作中。
當 type 是 range 時,那麼 EXPLAIN 輸出的 ref 字段為 NULL,並且 key_len 字段是此次查詢中使用到的索引的最長的那個 。
SELECT * FROM tbl_name WHERE key_column = 10; SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30); SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30); -
index: 表示全索引掃描(full index scan)和 ALL 類型類似,只不過 ALL 類型是全表掃描,而 index 類型則僅僅掃描所有的索引,而不掃描數據。
index 類型通常出現在: 所要查詢的數據直接在索引樹中就可以獲取到,而不需要掃描數據。當是這種情況時,Extra 字段 會显示 Using index
-
ALL: 表示全表掃描,這個類型的查詢是性能最差的查詢之一。
我們的查詢不應該出現 ALL 類型的查詢,因為這樣的查詢在數據量大的情況下,對數據庫的性能是巨大的災難。如一個查詢是 ALL 類型查詢,那麼一般來說可以對相應的字段添加索引來避免 。
possible_keys
表示 MySQL 在查詢時,能夠使用到的索引。
即使有些索引在 possible_keys 中出現,但是並不表示此索引會真正地被 MySQL 使用到。MySQL 在查詢時具體使用了哪些索引,由 key 字段決定。
key
是 MySQL 在當前查詢時所真正使用到的索引。
key_len
表示查詢優化器使用了索引的字節數。
這個字段可以評估組合索引是否完全被使用,或只有最左部分字段被使用到。key_len 的計算規則如下:
- 字符串
- char(n): n 字節長度
- varchar(n): 如果是 utf8 編碼, 則是 3n + 2字節; 如果是 utf8mb4 編碼, 則是 4n + 2 字節
- 數值類型
- TINYINT: 1字節
- SMALLINT: 2字節
- MEDIUMINT: 3字節
- INT: 4字節
- BIGINT: 8字節
- 時間類型
- DATE: 3字節
- TIMESTAMP: 4字節
- DATETIME: 8字節
- 字段屬性: NULL 屬性 佔用一個字節。如果一個字段是 NOT NULL 的, 則沒有此屬性
rows
查詢優化器根據統計信息,估算 SQL 要查找到結果集需要掃描讀取的數據行數。這個值非常直觀显示 SQL 的效率好壞,原則上 rows 越少越好。
這個 rows 就是 mysql 認為必須要逐行去檢查和判斷的記錄的條數。舉個例子來說,假如有一個語句 select * from t where column_a = 1 and column_b = 2; 全表假設有 100 條記錄,column_a 字段有索引(非聯合索引),column_b沒有索引。column_a = 1 的記錄有 20 條, column_a = 1 and column_b = 2 的記錄有 5 條。
Extra
EXplain 中的很多額外的信息會在 Extra 字段显示,常見的有以下幾種內容:
- Using filesort:當 Extra 中有 Using filesort 時,表示 MySQL 需額外的排序操作,不能通過索引順序達到排序效果。一般有 Using filesort,都建議優化去掉,因為這樣的查詢 CPU 資源消耗大。
- Using index:”覆蓋索引掃描”,表示查詢在索引樹中就可查找所需數據,不用掃描表數據文件,往往說明性能不錯
- Using temporary:查詢有使用臨時表,一般出現於排序,分組和多表 join 的情況,查詢效率不高,建議優化
- Using where: WHERE子句用於限制哪些行與下一個表匹配或發送給客戶端 。
得出結論
說到最後,那 WHERE column_index in (expr) 到底走不走索引呢? 答案是不確定的。
走不走索引是由 expr 來決定的,不是一概而論走還是不走。
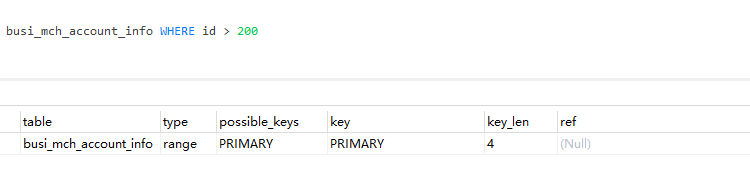
SELECT * FROM a WHERE id in (1,23,456,7,8)
-- id 是主鍵,查詢是走索引的。type = range,key = PRIMARY
SELECT * FROM a WHERE id in (SELECT b.a_id FROM b WHERE some_expr)
-- id 是主鍵,如果 some_expr 是一個索引查詢,那麼 select a 將走索引;
-- some_expr 不是索引查詢,那麼 select a 將全表掃描;
上面是兩個通用案例,但到底對不對了,還是自己去實踐最好了,拿起EXPLAIN去剖析吧~
參考文章: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!