- 場景
- 分流方式
- 如何分流
- 使用Filter分流
- 使用Split分流
- 使用Side Output分流
場景
獲取流數據的時候,通常需要根據所需把流拆分出其他多個流,根據不同的流再去作相應的處理。
舉個例子:創建一個商品實時流,商品有季節標籤,需要對不同標籤的商品做統計處理,這個時候就需要把商品數據流根據季節標籤分流。
分流方式
- 使用Filter分流
- 使用Split分流
- 使用Side Output分流
如何分流
先模擬一個實時的數據流
import lombok.Data;
@Data
public class Product {
public Integer id;
public String seasonType;
}
自定義Source
import common.Product;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.ArrayList;
import java.util.Random;
public class ProductStremingSource implements SourceFunction<Product> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Product> ctx) throws Exception {
while (isRunning){
// 每一秒鐘產生一條數據
Product product = generateProduct();
ctx.collect(product);
Thread.sleep(1000);
}
}
private Product generateProduct(){
int i = new Random().nextInt(100);
ArrayList<String> list = new ArrayList();
list.add("spring");
list.add("summer");
list.add("autumn");
list.add("winter");
Product product = new Product();
product.setSeasonType(list.get(new Random().nextInt(4)));
product.setId(i);
return product;
}
@Override
public void cancel() {
}
}
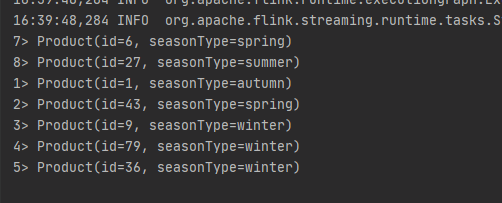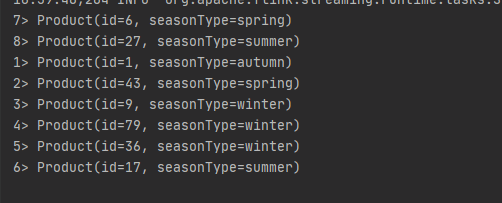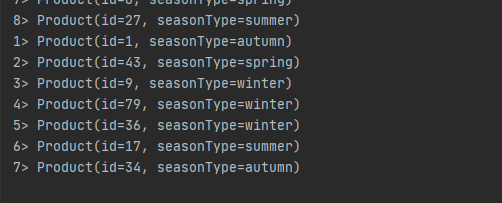
輸出:
使用Filter分流
使用 filter 算子根據數據的字段進行過濾。
import common.Product;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import source.ProductStremingSource;
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Filter分流
SingleOutputStreamOperator<Product> spring = source.filter(product -> "spring".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> summer = source.filter(product -> "summer".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> autumn = source.filter(product -> "autumn".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> winter = source.filter(product -> "winter".equals(product.getSeasonType()));
source.print();
winter.printToErr();
env.execute("output");
}
}
結果輸出(紅色為季節標籤是winter的分流輸出):
使用Split分流
重寫OutputSelector內部類的select()方法,根據數據所需要分流的類型反正不同的標籤下,返回SplitStream,通過SplitStream的select()方法去選擇相應的數據流。
只分流一次是沒有問題的,但是不能使用它來做連續的分流。
SplitStream已經標記過時了
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Split分流
SplitStream<Product> dataSelect = source.split(new OutputSelector<Product>() {
@Override
public Iterable<String> select(Product product) {
List<String> seasonTypes = new ArrayList<>();
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
seasonTypes.add(seasonType);
break;
case "summer":
seasonTypes.add(seasonType);
break;
case "autumn":
seasonTypes.add(seasonType);
break;
case "winter":
seasonTypes.add(seasonType);
break;
default:
break;
}
return seasonTypes;
}
});
DataStream<Product> spring = dataSelect.select("machine");
DataStream<Product> summer = dataSelect.select("docker");
DataStream<Product> autumn = dataSelect.select("application");
DataStream<Product> winter = dataSelect.select("middleware");
source.print();
winter.printToErr();
env.execute("output");
}
}
使用Side Output分流
推薦使用這種方式
首先需要定義一個OutputTag用於標識不同流
可以使用下面的幾種函數處理流發送到分流中:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
之後再用getSideOutput(OutputTag)選擇流。
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Side Output分流
final OutputTag<Product> spring = new OutputTag<Product>("spring");
final OutputTag<Product> summer = new OutputTag<Product>("summer");
final OutputTag<Product> autumn = new OutputTag<Product>("autumn");
final OutputTag<Product> winter = new OutputTag<Product>("winter");
SingleOutputStreamOperator<Product> sideOutputData = source.process(new ProcessFunction<Product, Product>() {
@Override
public void processElement(Product product, Context ctx, Collector<Product> out) throws Exception {
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
ctx.output(spring,product);
break;
case "summer":
ctx.output(summer,product);
break;
case "autumn":
ctx.output(autumn,product);
break;
case "winter":
ctx.output(winter,product);
break;
default:
out.collect(product);
}
}
});
DataStream<Product> springStream = sideOutputData.getSideOutput(spring);
DataStream<Product> summerStream = sideOutputData.getSideOutput(summer);
DataStream<Product> autumnStream = sideOutputData.getSideOutput(autumn);
DataStream<Product> winterStream = sideOutputData.getSideOutput(winter);
// 輸出標籤為:winter 的數據流
winterStream.print();
env.execute("output");
}
}
結果輸出:
更多文章:www.ipooli.com
掃碼關注公眾號《ipoo》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
