上一篇文章我們主要介紹了什麼是 Kafka,Kafka 的基本概念是什麼,Kafka 單機和集群版的搭建,以及對基本的配置文件進行了大致的介紹,還對 Kafka 的幾個主要角色進行了描述,我們知道,不管是把 Kafka 用作消息隊列、消息總線還是數據存儲平台來使用,最終是繞不過消息這個詞的,這也是 Kafka 最最核心的內容,Kafka 的消息從哪裡來?到哪裡去?都干什麼了?別著急,一步一步來,先說說 Kafka 的消息從哪來。
生產者概述
在 Kafka 中,我們把產生消息的那一方稱為生產者,比如我們經常回去淘寶購物,你打開淘寶的那一刻,你的登陸信息,登陸次數都會作為消息傳輸到 Kafka 後台,當你瀏覽購物的時候,你的瀏覽信息,你的搜索指數,你的購物愛好都會作為一個個消息傳遞給 Kafka 後台,然後淘寶會根據你的愛好做智能推薦,致使你的錢包從來都禁不住誘惑,那麼這些生產者產生的消息是怎麼傳到 Kafka 應用程序的呢?發送過程是怎麼樣的呢?
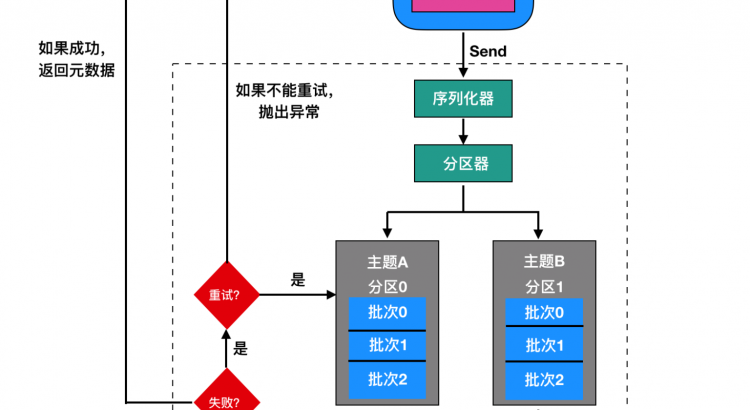
儘管消息的產生非常簡單,但是消息的發送過程還是比較複雜的,如圖
我們從創建一個ProducerRecord 對象開始,ProducerRecord 是 Kafka 中的一個核心類,它代表了一組 Kafka 需要發送的 key/value 鍵值對,它由記錄要發送到的主題名稱(Topic Name),可選的分區號(Partition Number)以及可選的鍵值對構成。
在發送 ProducerRecord 時,我們需要將鍵值對對象由序列化器轉換為字節數組,這樣它們才能夠在網絡上傳輸。然後消息到達了分區器。
如果發送過程中指定了有效的分區號,那麼在發送記錄時將使用該分區。如果發送過程中未指定分區,則將使用key 的 hash 函數映射指定一個分區。如果發送的過程中既沒有分區號也沒有,則將以循環的方式分配一個分區。選好分區后,生產者就知道向哪個主題和分區發送數據了。
ProducerRecord 還有關聯的時間戳,如果用戶沒有提供時間戳,那麼生產者將會在記錄中使用當前的時間作為時間戳。Kafka 最終使用的時間戳取決於 topic 主題配置的時間戳類型。
- 如果將主題配置為使用
CreateTime,則生產者記錄中的時間戳將由 broker 使用。
- 如果將主題配置為使用
LogAppendTime,則生產者記錄中的時間戳在將消息添加到其日誌中時,將由 broker 重寫。
然後,這條消息被存放在一個記錄批次里,這個批次里的所有消息會被發送到相同的主題和分區上。由一個獨立的線程負責把它們發到 Kafka Broker 上。
Kafka Broker 在收到消息時會返回一個響應,如果寫入成功,會返回一個 RecordMetaData 對象,它包含了主題和分區信息,以及記錄在分區里的偏移量,上面兩種的時間戳類型也會返回給用戶。如果寫入失敗,會返回一個錯誤。生產者在收到錯誤之後會嘗試重新發送消息,幾次之後如果還是失敗的話,就返回錯誤消息。
創建 Kafka 生產者
要往 Kafka 寫入消息,首先需要創建一個生產者對象,並設置一些屬性。Kafka 生產者有3個必選的屬性
該屬性指定 broker 的地址清單,地址的格式為 host:port。清單里不需要包含所有的 broker 地址,生產者會從給定的 broker 里查找到其他的 broker 信息。不過建議至少要提供兩個 broker 信息,一旦其中一個宕機,生產者仍然能夠連接到集群上。
broker 需要接收到序列化之後的 key/value值,所以生產者發送的消息需要經過序列化之後才傳遞給 Kafka Broker。生產者需要知道採用何種方式把 Java 對象轉換為字節數組。key.serializer 必須被設置為一個實現了org.apache.kafka.common.serialization.Serializer 接口的類,生產者會使用這個類把鍵對象序列化為字節數組。這裏拓展一下 Serializer 類
Serializer 是一個接口,它表示類將會採用何種方式序列化,它的作用是把對象轉換為字節,實現了 Serializer 接口的類主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默認使用的序列化器,其他的序列化器還有很多,你可以通過 查看其他序列化器。要注意的一點:key.serializer 是必須要設置的,即使你打算只發送值的內容。
與 key.serializer 一樣,value.serializer 指定的類會將值序列化。
下面代碼演示了如何創建一個 Kafka 生產者,這裏只指定了必要的屬性,其他使用默認的配置
private Properties properties = new Properties();
properties.put("bootstrap.servers","broker1:9092,broker2:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties = new KafkaProducer<String,String>(properties);
來解釋一下這段代碼
- 首先創建了一個 Properties 對象
- 使用
StringSerializer 序列化器序列化 key / value 鍵值對
- 在這裏我們創建了一個新的生產者對象,併為鍵值設置了恰當的類型,然後把 Properties 對象傳遞給他。
實例化生產者對象后,接下來就可以開始發送消息了,發送消息主要由下面幾種方式
直接發送,不考慮結果
使用這種發送方式,不會關心消息是否到達,會丟失一些消息,因為 Kafka 是高可用的,生產者會自動嘗試重發,這種發送方式和 UDP 運輸層協議很相似。
同步發送
同步發送仍然使用 send() 方法發送消息,它會返回一個 Future 對象,調用 get() 方法進行等待,就可以知道消息時候否發送成功。
異步發送
異步發送指的是我們調用 send() 方法,並制定一個回調函數,服務器在返迴響應時調用該函數。
下一節我們會重新討論這三種實現。
向 Kafka 發送消息
簡單消息發送
Kafka 最簡單的消息發送如下:
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
producer.send(record);
代碼中生產者(producer)的 send() 方法需要把 ProducerRecord 的對象作為參數進行發送,ProducerRecord 有很多構造函數,這個我們下面討論,這裏調用的是
public ProducerRecord(String topic, K key, V value) {}
這個構造函數,需要傳遞的是 topic主題,key 和 value。
把對應的參數傳遞完成后,生產者調用 send() 方法發送消息(ProducerRecord對象)。我們可以從生產者的架構圖中看出,消息是先被寫入分區中的緩衝區中,然後分批次發送給 Kafka Broker。
發送成功后,send() 方法會返回一個 Future(java.util.concurrent) 對象,Future 對象的類型是 RecordMetadata 類型,我們上面這段代碼沒有考慮返回值,所以沒有生成對應的 Future 對象,所以沒有辦法知道消息是否發送成功。如果不是很重要的信息或者對結果不會產生影響的信息,可以使用這種方式進行發送。
我們可以忽略發送消息時可能發生的錯誤或者在服務器端可能發生的錯誤,但在消息發送之前,生產者還可能發生其他的異常。這些異常有可能是 SerializationException(序列化失敗),BufferedExhaustedException 或 TimeoutException(說明緩衝區已滿),又或是 InterruptedException(說明發送線程被中斷)
同步發送消息
第二種消息發送機制如下所示
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
try{
RecordMetadata recordMetadata = producer.send(record).get();
}catch(Exception e){
e.printStackTrace();
}
這種發送消息的方式較上面的發送方式有了改進,首先調用 send() 方法,然後再調用 get() 方法等待 Kafka 響應。如果服務器返回錯誤,get() 方法會拋出異常,如果沒有發生錯誤,我們會得到 RecordMetadata 對象,可以用它來查看消息記錄。
生產者(KafkaProducer)在發送的過程中會出現兩類錯誤:其中一類是重試錯誤,這類錯誤可以通過重發消息來解決。比如連接的錯誤,可以通過再次建立連接來解決;無主錯誤則可以通過重新為分區選舉首領來解決。KafkaProducer 被配置為自動重試,如果多次重試后仍無法解決問題,則會拋出重試異常。另一類錯誤是無法通過重試來解決的,比如消息過大對於這類錯誤,KafkaProducer 不會進行重試,直接拋出異常。
異步發送消息
同步發送消息都有個問題,那就是同一時間只能有一個消息在發送,這會造成許多消息無法直接發送,造成消息滯后,無法發揮效益最大化。
比如消息在應用程序和 Kafka 集群之間一個來回需要 10ms。如果發送完每個消息后都等待響應的話,那麼發送100個消息需要 1 秒,但是如果是異步方式的話,發送 100 條消息所需要的時間就會少很多很多。大多數時候,雖然Kafka 會返回 RecordMetadata 消息,但是我們並不需要等待響應。
為了在異步發送消息的同時能夠對異常情況進行處理,生產者提供了回掉支持。下面是回調的一個例子
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("CustomerCountry", "Huston", "America");
producer.send(producerRecord,new DemoProducerCallBack());
class DemoProducerCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null){
exception.printStackTrace();;
}
}
}
首先實現回調需要定義一個實現了org.apache.kafka.clients.producer.Callback的類,這個接口只有一個 onCompletion方法。如果 kafka 返回一個錯誤,onCompletion 方法會拋出一個非空(non null)異常,這裏我們只是簡單的把它打印出來,如果是生產環境需要更詳細的處理,然後在 send() 方法發送的時候傳遞一個 Callback 回調的對象。
生產者分區機制
Kafka 對於數據的讀寫是以分區為粒度的,分區可以分佈在多個主機(Broker)中,這樣每個節點能夠實現獨立的數據寫入和讀取,並且能夠通過增加新的節點來增加 Kafka 集群的吞吐量,通過分區部署在多個 Broker 來實現負載均衡的效果。
上面我們介紹了生產者的發送方式有三種:不管結果如何直接發送、發送並返回結果、發送並回調。由於消息是存在主題(topic)的分區(partition)中的,所以當 Producer 生產者發送產生一條消息發給 topic 的時候,你如何判斷這條消息會存在哪個分區中呢?
這其實就設計到 Kafka 的分區機制了。
分區策略
Kafka 的分區策略指的就是將生產者發送到哪個分區的算法。Kafka 為我們提供了默認的分區策略,同時它也支持你自定義分區策略。
如果要自定義分區策略的話,你需要显示配置生產者端的參數 Partitioner.class,我們可以看一下這個類它位於 org.apache.kafka.clients.producer 包下
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {}
}
Partitioner 類有三個方法,分別來解釋一下
- partition(): 這個類有幾個參數:
topic,表示需要傳遞的主題;key 表示消息中的鍵值;keyBytes表示分區中序列化過後的key,byte數組的形式傳遞;value 表示消息的 value 值;valueBytes 表示分區中序列化后的值數組;cluster表示當前集群的原數據。Kafka 給你這麼多信息,就是希望讓你能夠充分地利用這些信息對消息進行分區,計算出它要被發送到哪個分區中。
- close() : 繼承了
Closeable 接口能夠實現 close() 方法,在分區關閉時調用。
- onNewBatch(): 表示通知分區程序用來創建新的批次
其中與分區策略息息相關的就是 partition() 方法了,分區策略有下面這幾種
順序輪訓
順序分配,消息是均勻的分配給每個 partition,即每個分區存儲一次消息。就像下面這樣
上圖表示的就是輪訓策略,輪訓策略是 Kafka Producer 提供的默認策略,如果你不使用指定的輪訓策略的話,Kafka 默認會使用順序輪訓策略的方式。
隨機輪訓
隨機輪訓簡而言之就是隨機的向 partition 中保存消息,如下圖所示
實現隨機分配的代碼只需要兩行,如下
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先計算出該主題總的分區數,然後隨機地返回一個小於它的正整數。
本質上看隨機策略也是力求將數據均勻地打散到各個分區,但從實際表現來看,它要遜於輪詢策略,所以如果追求數據的均勻分佈,還是使用輪詢策略比較好。事實上,隨機策略是老版本生產者使用的分區策略,在新版本中已經改為輪詢了。
按照 key 進行消息保存
這個策略也叫做 key-ordering 策略,Kafka 中每條消息都會有自己的key,一旦消息被定義了 Key,那麼你就可以保證同一個 Key 的所有消息都進入到相同的分區裏面,由於每個分區下的消息處理都是有順序的,故這個策略被稱為按消息鍵保序策略,如下圖所示
實現這個策略的 partition 方法同樣簡單,只需要下面兩行代碼即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
上面這幾種分區策略都是比較基礎的策略,除此之外,你還可以自定義分區策略。
生產者壓縮機制
壓縮一詞簡單來講就是一種互換思想,它是一種經典的用 CPU 時間去換磁盤空間或者 I/O 傳輸量的思想,希望以較小的 CPU 開銷帶來更少的磁盤佔用或更少的網絡 I/O 傳輸。如果你還不了解的話我希望你先讀完這篇文章 ,然後你就明白壓縮是怎麼回事了。
Kafka 壓縮是什麼
Kafka 的消息分為兩層:消息集合 和 消息。一個消息集合中包含若干條日誌項,而日誌項才是真正封裝消息的地方。Kafka 底層的消息日誌由一系列消息集合日誌項組成。Kafka 通常不會直接操作具體的一條條消息,它總是在消息集合這個層面上進行寫入操作。
在 Kafka 中,壓縮會發生在兩個地方:Kafka Producer 和 Kafka Consumer,為什麼啟用壓縮?說白了就是消息太大,需要變小一點 來使消息發的更快一些。
Kafka Producer 中使用 compression.type 來開啟壓縮
private Properties properties = new Properties();
properties.put("bootstrap.servers","192.168.1.9:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("compression.type", "gzip");
Producer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","Precision Products","France");
上面代碼錶明該 Producer 的壓縮算法使用的是 GZIP
有壓縮必有解壓縮,Producer 使用壓縮算法壓縮消息后併發送給服務器后,由 Consumer 消費者進行解壓縮,因為採用的何種壓縮算法是隨着 key、value 一起發送過去的,所以消費者知道採用何種壓縮算法。
Kafka 重要參數配置
在上一篇文章 中,我們主要介紹了一下 kafka 集群搭建的參數,本篇文章我們來介紹一下 Kafka 生產者重要的配置,生產者有很多可配置的參數,在文檔里(
key.serializer
用於 key 鍵的序列化,它實現了 org.apache.kafka.common.serialization.Serializer 接口
value.serializer
用於 value 值的序列化,實現了 org.apache.kafka.common.serialization.Serializer 接口
acks
acks 參數指定了要有多少個分區副本接收消息,生產者才認為消息是寫入成功的。此參數對消息丟失的影響較大
- 如果 acks = 0,就表示生產者也不知道自己產生的消息是否被服務器接收了,它才知道它寫成功了。如果發送的途中產生了錯誤,生產者也不知道,它也比較懵逼,因為沒有返回任何消息。這就類似於 UDP 的運輸層協議,只管發,服務器接受不接受它也不關心。
- 如果 acks = 1,只要集群的 Leader 接收到消息,就會給生產者返回一條消息,告訴它寫入成功。如果發送途中造成了網絡異常或者 Leader 還沒選舉出來等其他情況導致消息寫入失敗,生產者會受到錯誤消息,這時候生產者往往會再次重發數據。因為消息的發送也分為
同步 和 異步,Kafka 為了保證消息的高效傳輸會決定是同步發送還是異步發送。如果讓客戶端等待服務器的響應(通過調用 Future 中的 get() 方法),顯然會增加延遲,如果客戶端使用回調,就會解決這個問題。
- 如果 acks = all,這種情況下是只有當所有參与複製的節點都收到消息時,生產者才會接收到一個來自服務器的消息。不過,它的延遲比 acks =1 時更高,因為我們要等待不只一個服務器節點接收消息。
buffer.memory
此參數用來設置生產者內存緩衝區的大小,生產者用它緩衝要發送到服務器的消息。如果應用程序發送消息的速度超過發送到服務器的速度,會導致生產者空間不足。這個時候,send() 方法調用要麼被阻塞,要麼拋出異常,具體取決於 block.on.buffer.null 參數的設置。
compression.type
此參數來表示生產者啟用何種壓縮算法,默認情況下,消息發送時不會被壓縮。該參數可以設置為 snappy、gzip 和 lz4,它指定了消息發送給 broker 之前使用哪一種壓縮算法進行壓縮。下面是各壓縮算法的對比
retries
生產者從服務器收到的錯誤有可能是臨時性的錯誤(比如分區找不到首領),在這種情況下,reteis 參數的值決定了生產者可以重發的消息次數,如果達到這個次數,生產者會放棄重試並返回錯誤。默認情況下,生產者在每次重試之間等待 100ms,這個等待參數可以通過 retry.backoff.ms 進行修改。
batch.size
當有多個消息需要被發送到同一個分區時,生產者會把它們放在同一個批次里。該參數指定了一個批次可以使用的內存大小,按照字節數計算。當批次被填滿,批次里的所有消息會被發送出去。不過生產者井不一定都會等到批次被填滿才發送,任意條數的消息都可能被發送。
client.id
此參數可以是任意的字符串,服務器會用它來識別消息的來源,一般配置在日誌里
max.in.flight.requests.per.connection
此參數指定了生產者在收到服務器響應之前可以發送多少消息,它的值越高,就會佔用越多的內存,不過也會提高吞吐量。把它設為1 可以保證消息是按照發送的順序寫入服務器。
timeout.ms、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 指定了生產者在發送數據時等待服務器返回的響應時間,metadata.fetch.timeout.ms 指定了生產者在獲取元數據(比如目標分區的首領是誰)時等待服務器返迴響應的時間。如果等待時間超時,生產者要麼重試發送數據,要麼返回一個錯誤。timeout.ms 指定了 broker 等待同步副本返回消息確認的時間,與 asks 的配置相匹配—-如果在指定時間內沒有收到同步副本的確認,那麼 broker 就會返回一個錯誤。
max.block.ms
此參數指定了在調用 send() 方法或使用 partitionFor() 方法獲取元數據時生產者的阻塞時間當生產者的發送緩衝區已捕,或者沒有可用的元數據時,這些方法就會阻塞。在阻塞時間達到 max.block.ms 時,生產者會拋出超時異常。
max.request.size
該參數用於控制生產者發送的請求大小。它可以指能發送的單個消息的最大值,也可以指單個請求里所有消息的總大小。
receive.buffer.bytes 和 send.buffer.bytes
Kafka 是基於 TCP 實現的,為了保證可靠的消息傳輸,這兩個參數分別指定了 TCP Socket 接收和發送數據包的緩衝區的大小。如果它們被設置為 -1,就使用操作系統的默認值。如果生產者或消費者與 broker 處於不同的數據中心,那麼可以適當增大這些值。
文章參考:
《Kafka 權威指南》
極客時間 -《Kafka 核心技術與實戰》
Kafka 源碼
關注公眾號獲取更多優質电子書,關注一下你就知道資源是有多好了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開