系統架構設計師-軟件水平考試(高級)-論文-可靠性
前言
首先說一下為什麼這兩個月又沒消息了,因為這兩個月忙啊。
首先是接收上半年系統分析師的證書,並完成總結。其次是九月份PMP考試(4A通過,尚需努力),然後是十一月的軟考高項的考試。工作的事情就不談了,還好沒什麼私人事情需要處理。所以這兩個月沒什麼空寫博客,不過接下來應該會有一些時間來寫博客。
關於系統架構師這個分支,原本都打算完結了的。然後突然發現大家對系統架構師的論文比較感興趣,並且自從我上次透露了我有一個架構師/分析師的群后,陸陸續續不斷有人私信我加群。所以,就回過頭,再發一篇系統架構師的論文。並打算找時間,將自己系統分析師,PMP,項目管理師的知識整理出來。畢竟在過去的一年的時間,我連續通過系統架構師,系統分析師,PMP,並完成,參加了高項(雖然目前還不知道通過沒),我認為我的學習方法,知識體系等還是有一定作用的,希望對大家有所幫助。嘻嘻。
哦。差點忘了。由於我的架構師/分析師群是邀請制的,所以給你們群號,也是無法添加的。所以,如果有參加架構師/分析師的朋友,請私聊我。謝謝。
一,理論
(強調一下,圖片絕對清晰。如果看不清,請從新的頁面打開,或者下載下來)
論文
摘要:
本人於2015年11月參与浙江省某在線教育平台“外教一對一在線教育”項目,該項目為客戶提供了一對一歐美外教視頻教學,社交圈,公眾直播等功能提供全方位的軟件支撐,在該項目組中我擔任系統架構師崗位,主要負責整體架構設計與中間件選型。本文以該教育平台為例,主要討論了該系統有關可靠性方面的設計與應用,以及遇到的問題與解決方案。一方面通過負載均衡進行容錯技術中冗餘設計的實現,另一方面通過層次架構風格來明確系統結構體系,從而降低系統設計複雜度,提高系統可靠性。整個系統開發工作歷時18個月。目前,該系統已經穩定運行近一年半的時間。實踐證明,通過容錯設計,降低複雜度設計等,系統有效提高了可靠性,從而為公司業務提供持續穩定的服務支撐。
正文:
隨着國家對教育的越發重視,英語教育的市場份額逐步上升,其中用戶口語提升的需求越來越大。為此,一些公司開始提供與外國人聊天的平台。我所在公司決定從國際通訊領域進軍口語教育領域。為了這項戰略轉變,公司於2015年11月設計某在線教育平台系統(一下簡稱為“系統”)。該系統幫助人們與歐美外教進行面對面的口語交流和教學。其中隨意聊提供了一種類似QQ視頻通話,而正式課程還提供了H5互動課件與課後點評等,以提高教學質量。與此同時,還有公眾直播用於拉新,AI測試用於評定學院能力,降低成本。我參与了該項目的開發工作,擔任系統架構設計師職務,負責設計系統架構。本項目組全體成員共9人,我主要負責項目計劃制定,需求分析,整體架構設計與技術選型,以及部分底層設計。該項目的架構工作與次年2月完成,選擇了層次架構風格。整個項目耗時18個月,於2017年5月完成。
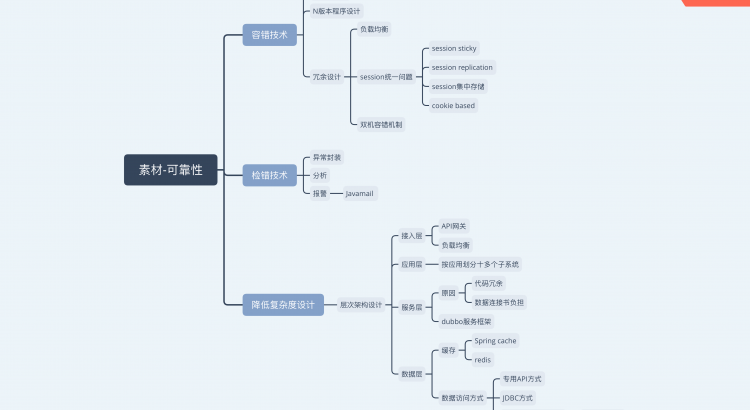
目前主流的可靠性設計技術有容錯設計,檢錯設計,降低複雜度設計等技術。容錯設計技術分為恢復塊設計,N版本程序設計和冗餘設計。其中恢復塊設計是選擇一組軟件操作作為容錯設計單元,將普通的程序塊編程恢復塊。N版本程序設計的核心是通過設計出多個模塊或不同版本,對於相同初始條件和相同輸入的操作結果,實現多數表決,防止其中某一軟件模塊/版本的故障提供錯誤的服務,以實現軟件容錯。冗餘設計是在一套完整的軟件系統之外,設計一種不同路徑,不同算法或不同實現方法的模塊或系統作為備份,在出現故障時可以使用冗餘的部分進行替換,從而維持軟件系統的正常運行。缺點是費用和資源的消耗會有所增加。檢錯技術是在軟件出現故障后能及時發現並報警。其缺點是不能自動解決故障。降低複雜度設計是因為軟件複雜性與軟件可靠性有着密切關係,是產生軟件缺陷的重要根源。在設計時考慮降低軟件的複雜性,是提高軟件可靠性的有效方法。
在了解系統需求后,我們決定聽從公司技術顧問的建議,容錯設計主要應用在冗餘設計方面,通過負載均衡,雙機容錯等機制完成冗餘設計。檢錯設計則是通過對Java異常處理機制的設計與封裝處理完成。至於降低複雜度方面,採用層次架構風格,使得系統的結構明確,立體,從而提高系統可靠性。接下來,我將從系統的冗餘設計,複雜度降低設計介紹可靠性在系統中的設計與應用,以及應用過程中遇到的問題與解決方案。
1.冗餘設計:
首先說冗餘設計,冗餘包含邏輯冗餘,數據冗餘,應用冗餘等。這裏以應用冗餘為例。為了提高系統的性能,可靠性,可拓展性等,我們採用了負載均衡技術。常見的負載均衡技術有F5硬件,LVS軟件,Nginx服務器配置等。出於便捷與成本的考慮,我們採用了Nginx服務器配置負載均衡技術。通過對Nginx服務器中upstream模塊的配置,就可以實現在多台服務器的反向代理家在負載均衡。採用負載均衡后,應用服務器集群存在Session問題無法統一的問題。解決方法有Session Sticky,Session Replication,Session數據集中存儲,Cookie Based四個方案。Session Sticky是通過確保同一個會話的請求都在同一個Web服務器上處理實現。Session Replication是增加Web服務器間會話數據的同步來保證不同Web服務器間的Session數據的一致。Cookie Based就是通過Cookie傳遞Session數據完成。經過考慮,我們採用了Session數據集中存儲。Session數據集中存儲通過令每台服務器從專門的session服務器獲取session數據來解決問題。優點是可靠性,可移植性與可拓展性的大幅提高。缺點是一方面讀寫Session數據引入了網絡操作,對數據讀取存在時延和不穩定性,但對於使用內網通信的系統並沒有太大影響。另一方面,如果Session服務器或集群出現問題,將會影響整個應用。我們通過雙機容錯機制解決該問題。除此之外,還有心跳線,看門狗等技術。限於篇幅,不再贅述。
2.降低複雜度設計:
再者就是降低複雜度設計,由於系統的複雜性和綜合性,我們決定採用層次架構風格,將系統架構分為接入層,應用層,服務層,數據層四個層次。這裏以應用層與服務層為例。應用層分為視圖層與業務邏輯層,視圖層負責App與網站的表現效果,業務邏輯層負責業務層的邏輯處理。為了解決系統日益複雜,應用日益臃腫問題,我們將系統按照應用橫向劃分,將系統劃分為課件管理系統,課程管理系統等十餘個子系統。如課件管理系統負責學員上課所用課件,有課件編輯,課件預覽,課件交互等多個功能模塊。功能模塊需調用服務層的服務支撐,如課件交互模塊需要調用stomp通信服務,實現學生與老師間課件的交互功能。另外,課件交互模塊通過對賬戶服務的調用,確立課件雙方的身份,從而明確雙方在課件交互過程中對課件交互部分的交互權限。該劃分使得系統體系變得清晰明了,極大降低系統複雜度,提高系統可靠性。應用層採用基於J2ee的MVC框架-Structs框架,主要通過Servlet和JSP技術實現。另外還有動靜分離,動態資源靜態化等,這裏不再贅述。
服務層提供通用服務。系統在應用層中按照應用橫向劃分,有效降低系統複雜度。但系統代碼仍然存在冗餘,比如用戶信息的調用在諸多應用子系統中都有相關模塊。另外應用的大小依舊十分巨大,複雜,而過小的應用劃分會增加數據庫連接數負擔,故我們提出服務化解決方案。服務化方案就是提取出各個應用的通用服務,如賬戶服務,Session服務等。出於技術成熟度與技術支持等考慮,我們最終採用了阿里的dubbo服務框架,建立服務層。開發過程中,產生了服務框架部署問題與實現服務框架的jar包和應用自身依賴的jar包衝突的問題。前者,我們通過Tomcat作為Web容器,而服務框架作為容器的一部分來解決。後者,我們通過Java的ClassLoader將服務框架自身用的類與應用的類進行隔離。除此之外,我們通過服務線程池隔離,分佈請求合併,服務調用端的流程控制來降低系統複雜度,提高系統可靠性。詳情限於篇幅,不再贅述。
最終項目成功上線,正常運行了近一年半,收到各方好評。尤其是H5課件的良好互動性,使得大量業界同行爭相模仿,改用H5製作課件。還有我們的服務化方案架構被作為許多傳統互聯網企業系統重構的經典方案。在系統的架構設計中,我們引入了層次架構的設計思想,有效地降低了維護成本,提高了系統的開放性,可擴展性,可重用性以及可移植性。當然還是存在一些問題的。如H5課件採用http協議,易被非法劫持,嵌入廣告,可以將協議修改為https來解決。還有我們採用的負載均衡算法是加權輪轉算法,過於簡單,常常出現資源分配不合理的現象,可以將算法改為加權最小連接數算法來解決。這些都是我在今後的系統設計和開發中需要注意與改進的地方,也是日後我應該努力的方向。
三,總結
這篇論文的項目,依舊是之前那片論文的項目-在線教育系統。但是其中很多技術,其實在原有項目中是沒有涉及的。
另外這篇論文與之前論文存在一個結構上的不同之處,那就是這次的核心論點只有兩個分論點。不過,第二個論點-降低複雜度設計,是通過兩個方面進行闡述的。這也算是論文中核心論點的一種回答方式。往往論文的核心論點,推薦使用三個分論點進行論述,而部分論文的核心論點就只能拆分為兩個分論點(或者,三個論點的拆分維度,自己不熟悉)。這時候就需要靈活的轉變自己的思想,將核心論點的兩個分論點氛圍主次論點回答,實際體現就是主論點兩個段落,次論點一個段落。
既然說到這裏,也說一下,如果核心論點可以拆分出多個分論點。如架構風格的層次架構完全可以拆分為接入層,應用層,服務層(基礎服務層,通用服務層,業務服務層),數據接入層,數據源等。那麼這種情況,我們完全可以從中挑選三點自己熟悉的部分,進行闡述。如果擔心這樣寫,文章顯得比較僵硬,就在相關位置寫上“此處,我們以XXX,XXX,XXX為重點,進行論述”這樣的話語即可。
附錄
早期未修改的論文:
摘要:
本人於2015年11月參与浙江省某在線教育平台“外教一對一在線教育”項目,該項目為客戶提供了一對一歐美外教視頻教學,社交圈,公眾直播等功能提供全方位的軟件支撐,在該項目組中我擔任系統架構師崗位,主要負責整體架構設計與中間件選型。本文以該教育平台為例,主要討論了該系統有關可靠性方面的設計與應用。一方面通過負載均衡與應用服務器集群實現容錯技術中冗餘設計的實現,另一方面通過建立了接入層,應用層,服務層,數據層四層層次的架構來降低明確系統結構,從而系統設計複雜度,提高系統可靠性。整個系統開發工作歷時18個月。目前,該系統已經穩定運行近一年半的時間。實踐證明,通過容錯設計,降低複雜度設計等,系統有效提高了可靠性,從而為公司業務提供持續穩定的服務支撐。
正文:
隨着國家對教育的越發重視,英語教育的市場份額逐步上升,其中用戶口語提升的需求越來越大。為此,一些公司開始提供與外國人聊天的平台。我所在公司決定從國際通訊領域進軍口語教育領域。為了這項戰略轉變,公司於2015年11月設計某在線教育平台系統(一下簡稱為“系統”)。該系統幫助人們與歐美外教進行面對面的口語交流和教學。其中隨意聊提供了一種類似QQ視頻通話,而正式課程還提供了H5互動課件與課後點評等,以提高教學質量。與此同時,還有公眾直播用於拉新,AI測試用於評定學院能力,降低成本。我參与了該項目的開發工作,擔任系統架構設計師職務,負責設計系統架構。本項目組全體成員共9人,我主要負責項目計劃制定,需求分析,整體架構設計與技術選型,以及部分底層設計。該項目的架構工作與次年2月完成,選擇了層次架構風格。整個項目耗時18個月,於2017年5月完成。
目前主流的可靠性設計技術有容錯設計,檢錯設計,降低複雜度設計等技術。容錯設計技術分為恢復塊設計,N版本程序設計和冗餘設計。其中恢復塊設計是選擇一組軟件操作作為容錯設計單元,將普通的程序塊編程恢復塊。N版本程序設計的核心是通過設計出多個模塊或不同版本,對於相同初始條件和相同輸入的操作結果,實現多數表決,防止其中某一軟件模塊/版本的故障提供錯誤的服務,以實現軟件容錯。冗餘設計是在一套完整的軟件系統之外,設計一種不同路徑,不同算法或不同實現方法的模塊或系統作為備份,在出現故障時可以使用冗餘的部分進行替換,從而維持軟件系統的正常運行。缺點是費用和資源的消耗會有所增加。檢錯技術是在軟件出現故障后能及時發現並報警。其缺點是不能自動解決故障。降低複雜度設計是因為軟件複雜性與軟件可靠性有着密切關係,是產生軟件缺陷的重要根源。在設計時考慮降低軟件的複雜性,是提高軟件可靠性的有效方法。
在了解系統需求后,我們決定聽從公司技術顧問的建議,在容錯設計,檢錯設計,降低複雜度設計三個主流方向分別作出相應處理和應用。容錯設計主要應用在冗餘設計方面,通過負載均衡,雙機容錯等機制完成冗餘設計。檢錯設計則是通過對Java異常處理機制的設計與封裝處理完成。至於降低複雜度,我們應用層次清晰的四層層次架構。通過將系統劃分為接入層,應用層,服務層,數據層,使得系統的結構明確,立體,從而降低系統複雜度。限於篇幅,接下來,我將從系統的冗餘設計,複雜度降低設計兩個方面介紹可靠性在系統中的設計與應用,以及應用過程中遇到的問題。
首先說冗餘設計,冗餘包含邏輯冗餘,數據冗餘,應用冗餘等。這裏以應用冗餘為例。一方面為了提高應用服務器性能,另一方面為了提高系統的可靠性,可拓展性等,我們採用了負載均衡技術。常見的負載均衡技術有F5硬件,LVS軟件,Nginx服務器配置等。出於便捷與成本的考慮,我們採用了Nginx服務器配置負載均衡技術。通過對Nginx服務器中upstream模塊的配置,就可以實現在多台服務器的反向代理家在負載均衡。為了提高負載均衡服務器可靠性,我們採用雙機熱備機制。但採用負載均衡后,應用服務器集群出現了Session問題無法統一的問題。解決方法有Session Sticky,Session Replication,Session數據集中存儲,Cookie Based四個方案。Session Sticky是通過確保同一個會話的請求都在同一個Web服務器上處理實現。Session Replication是增加Web服務器間會話數據的同步來保證不同Web服務器間的Session數據的一致。但一方面同步Session數據會造成網絡帶寬的開銷。另一方面,每台Web服務器都要保存所有Session數據,消耗大量內存。經過考慮,我們採用了第三種方案-Session數據集中存儲。Session數據集中存儲通過令每台服務器從專門的session服務器獲取session數據來解決問題。優點是可靠性,可移植性與可拓展性的大幅提高。缺點是一方面讀寫Session數據引入了網絡操作,對數據讀取存在時延和不穩定性,但對於使用內網通信的系統並沒有太大影響。另一方面,如果Session服務器或集群出現問題,將會影響整個應用。我們通過雙機容錯機制解決該問題。Cookie Based就是通過Cookie傳遞Session數據完成。實現簡單,但是存在如Cookie長度限制等問題。除此之外,還有心跳線,看門狗等諸多技術。限於篇幅,不再贅述。
再者就是降低複雜度設計,我們從架構風格選擇,技術選型等角度實現。由於系統的複雜性和綜合性,我們決定採用層次架構風格,將系統架構分為接入層,應用層,服務層,數據層四個層次。接入層負責多平台的接入,以及API網關,負載均衡等方面。API網關的使用使得對外資源與服務獲得統一,保持系統結構的明確,從而提高了系統可靠性。應用層分為視圖層與業務邏輯層,視圖層負責App與網站的表現效果,業務邏輯層負責業務層的邏輯處理。為了解決系統日益複雜,應用日益臃腫問題,我們將系統按照應用橫向劃分,將系統劃分為課件管理系統,課程管理系統等十餘個子系統。這樣的劃分使得系統體系變得清晰明了,極大降低系統複雜度,提高系統可靠性。應用層採用基於J2ee的MVC框架-Structs框架。服務層提供通用服務。系統在應用層中按照應用橫向劃分,有效降低系統複雜度。但系統代碼仍然存在冗餘,比如用戶信息的調用在諸多應用子系統中都有相關模塊。另外應用的大小依舊十分巨大,複雜,而過小的應用劃分會增加數據庫連接數負擔,故我們提出服務化解決方案。服務化方案就是提取出各個應用的通用服務,如賬戶服務,Session服務等。出於技術成熟度與技術支持等考慮,我們最終採用了阿里的dubbo服務框架,建立服務層。數據層涉及緩存,文件系統,數據庫,數據通知服務,搜索系統等模塊。由於用戶對數據訪問具有集中性,故我們基於Spring Cache與Redis實現緩存機制。數據訪問方面,Java已經有很多成熟技術,大致分為專用API方式,JDBC方式,給予ORM或類ORM接口方式三種。最終我們採用了成熟的ORM框架-Mybatis框架,再將框架包裝一層。這樣一方面提高系統開發效率,另一方面提高系統可移植性與可靠性。除此之外,還採用了solr作為數據層搜索引擎,數據訪問層物理部署採用Proxy方式。限於篇幅,不再贅述。
最終項目成功上線,正常運行了近一年半,收到各方好評。尤其是H5課件的良好互動性,使得大量業界同行爭相模仿,改用H5製作課件。還有我們的服務化方案架構被作為許多傳統互聯網企業系統重構的經典方案。在系統的架構設計中,我們引入了層次架構的設計思想,有效地降低了維護成本,提高了系統的開放性,可擴展性,可重用性以及可移植性。當然還是存在一些問題的。如H5課件採用http協議,易被非法劫持,嵌入廣告,可以將協議修改為https來解決。還有我們採用的負載均衡算法是加權輪轉算法,過於簡單,常常出現資源分配不合理的現象,可以將算法改為加權最小連接數算法來解決。這些都是我在今後的系統設計和開發中需要注意與改進的地方,也是日後我應該努力的方向。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務