動手造輪子:實現一個簡單的 AOP 框架
Intro
最近實現了一個 AOP 框架 — FluentAspects,API 基本穩定了,寫篇文章分享一下這個 AOP 框架的設計。
整體設計
概覽
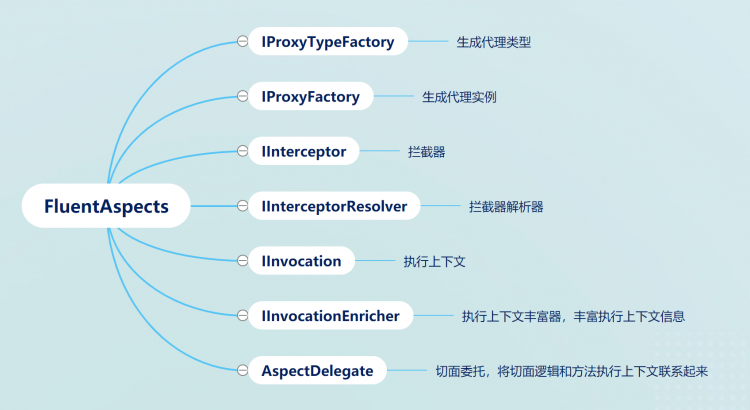
IProxyTypeFactory
用來生成代理類型,默認提供了基於 Emit 動態代理的實現,基於接口設計,可以擴展為其他實現方式
接口定義如下:
public interface IProxyTypeFactory
{
Type CreateProxyType(Type serviceType);
Type CreateProxyType(Type serviceType, Type implementType);
}
IProxyFactory
用來生成代理實例,默認實現是基於 IProxyTypeFactory 生成代理類型之後創建實例
接口定義如下:
public interface IProxyFactory
{
object CreateProxy(Type serviceType, object[] arguments);
object CreateProxy(Type serviceType, Type implementType, params object[] arguments);
object CreateProxyWithTarget(Type serviceType, object implement, object[] arguments);
}
IInvocation
執行上下文,默認實現就是方法執行的上下文,包含了代理方法信息、被代理的方法信息、方法參數,返回值以及用來自定義擴展的一個 Properties 屬性
public interface IInvocation
{
MethodInfo ProxyMethod { get; }
object ProxyTarget { get; }
MethodInfo Method { get; }
object Target { get; }
object[] Arguments { get; }
Type[] GenericArguments { get; }
object ReturnValue { get; set; }
Dictionary<string, object> Properties { get; }
}
IInterceptor
攔截器,用來定義公用的處理邏輯,方法攔截處理方法
接口定義如下:
public interface IInterceptor
{
Task Invoke(IInvocation invocation, Func<Task> next);
}
invocation 是方法執行的上下文,next 代表後續的邏輯處理,類似於 asp.net core 里的 next ,如果不想執行方面的方法不執行 next 邏輯即可
IInterceptorResolver
用來根據當前的執行上下文獲取到要執行的攔截器,默認是基於 FluentAPI 的實現,但是如果你特別想用基於 Attribute 的也是可以的,默認提供了一個 AttributeInterceotorResovler,你也可以自定義一個適合自己的 InterceptorResolver
public interface IInterceptorResolver
{
IReadOnlyList<IInterceptor> ResolveInterceptors(IInvocation invocation);
}
IInvocationEnricher
上面 IInvocation 的定義中有一個用於擴展的 Properties,這個 enricher 主要就是基於 Properties 來豐富執行上下文信息的,比如說記錄 TraceId 等請求鏈路追蹤數據,構建方法執行鏈路等
public interface IEnricher<in TContext>
{
void Enrich(TContext context);
}
public interface IInvocationEnricher : IEnricher<IInvocation>
{
}
AspectDelegate
AspectDelegate 是用來將構建要執行的代理方法的方法體的,首先執行註冊的 InvocationEnricher,豐富上下文信息,然後根據執行上下文獲取要執行的攔截器,構建一個執行委託,生成委託使用了之前分享過的 PipelineBuilder 構建中間件模式的攔截器,執行攔截器邏輯
// apply enrichers
foreach (var enricher in FluentAspects.AspectOptions.Enrichers)
{
try
{
enricher.Enrich(invocation);
}
catch (Exception ex)
{
InvokeHelper.OnInvokeException?.Invoke(ex);
}
}
// get delegate
var builder = PipelineBuilder.CreateAsync(completeFunc);
foreach (var interceptor in interceptors)
{
builder.Use(interceptor.Invoke);
}
return builder.Build();
更多信息可以參考源碼: https://github.com/WeihanLi/WeihanLi.Common/blob/dev/src/WeihanLi.Common/Aspect/AspectDelegate.cs
使用示例
推薦和依賴注入結合使用,主要分為以微軟的注入框架為例,有兩種使用方式,一種是手動註冊代理服務,一種是自動批量註冊代理服務,來看下面的實例就明白了
手動註冊代理服務
使用方式一,手動註冊代理服務:
為了方便使用,提供了一些 AddProxy 的擴展方法:
IServiceCollection services = new ServiceCollection();
services.AddFluentAspects(options =>
{
// 註冊攔截器配置
options.NoInterceptProperty<IFly>(f => f.Name);
options.InterceptAll()
.With<LogInterceptor>()
;
options.InterceptMethod<DbContext>(x => x.Name == nameof(DbContext.SaveChanges)
|| x.Name == nameof(DbContext.SaveChangesAsync))
.With<DbContextSaveInterceptor>()
;
options.InterceptMethod<IFly>(f => f.Fly())
.With<LogInterceptor>();
options.InterceptType<IFly>()
.With<LogInterceptor>();
// 註冊 InvocationEnricher
options
.WithProperty("TraceId", "121212")
;
});
// 使用 Castle 生成代理
services.AddFluentAspects(options =>
{
// 註冊攔截器配置
options.NoInterceptProperty<IFly>(f => f.Name);
options.InterceptAll()
.With<LogInterceptor>()
;
options.InterceptMethod<DbContext>(x => x.Name == nameof(DbContext.SaveChanges)
|| x.Name == nameof(DbContext.SaveChangesAsync))
.With<DbContextSaveInterceptor>()
;
options.InterceptMethod<IFly>(f => f.Fly())
.With<LogInterceptor>();
options.InterceptType<IFly>()
.With<LogInterceptor>();
// 註冊 InvocationEnricher
options
.WithProperty("TraceId", "121212")
;
}, builder => builder.UseCastle());
services.AddTransientProxy<IFly, MonkeyKing>();
services.AddSingletonProxy<IEventBus, EventBus>();
services.AddDbContext<TestDbContext>(options =>
{
options.UseInMemoryDatabase("Test");
});
services.AddScopedProxy<TestDbContext>();
var serviceProvider = services.BuildServiceProvider();
批量自動註冊代理服務
使用方式二,批量自動註冊代理服務:
IServiceCollection services = new ServiceCollection();
services.AddTransient<IFly, MonkeyKing>();
services.AddSingleton<IEventBus, EventBus>();
services.AddDbContext<TestDbContext>(options =>
{
options.UseInMemoryDatabase("Test");
});
var serviceProvider = services.BuildFluentAspectsProvider(options =>
{
options.InterceptAll()
.With<TestOutputInterceptor>(output);
});
// 使用 Castle 來生成代理
var serviceProvider = services.BuildFluentAspectsProvider(options =>
{
options.InterceptAll()
.With<TestOutputInterceptor>(output);
}, builder => builder.UseCastle());
// 忽略命名空間為 Microsoft/System 的服務類型
var serviceProvider = services.BuildFluentAspectsProvider(options =>
{
options.InterceptAll()
.With<TestOutputInterceptor>(output);
}, builder => builder.UseCastle(), t=> t.Namespace != null && (t.Namespace.StartWith("Microsft") ||t.Namespace.StartWith("Microsft")));
More
上面的兩種方式個人比較推薦使用第一種方式,需要攔截什麼就註冊什麼代理服務,自動註冊可能會生成很多不必要的代理服務,個人還是比較喜歡按需註冊的方式,更為可控。
這個框架還不是很完善,有一些地方還是需要優化的,目前還是在我自己的類庫中,因為我的類庫里要支持 net45,所以有一些不好的設計改起來不太方便,打算遷移出來作為一個單獨的組件,直接基於 netstandard2.0/netstandard2.1, 甩掉 netfx 的包袱。
Reference
- https://github.com/WeihanLi/WeihanLi.Common/blob/dev/src/WeihanLi.Common/Aspect
- https://www.cnblogs.com/weihanli/p/12700006.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?