文:宋瑞文
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
摘錄自2020年5月7日轉角國際報導
3月底正當日本疫情嚴峻、還在為是否宣告緊急事態而苦惱的時候,3月31日政府中央防災會議,公佈了富士山大噴發的災難模擬報告;只是報告當天,日本的感染確診病例暴增,這份研究因此沒有得到太多新聞關注;但看似不相關的火山爆發與病毒爆發,近期才又因為口罩匱乏的問題引發社會討論。
在這份富士山噴發的模擬資料中,若富士山出現嚴重大爆發,推估首都圈(包括東京等一都三縣)會降下至少2到10公分厚度的火山灰,約莫三個小時後從橫濱市到千葉市的交通機能全面中斷,東京、神奈川、埼玉等地大規模停電。同時受到火山灰的影響,通訊基地塔台訊號失能,各地將會陸續出現通訊斷絕、食物和水源匱乏的危機。
4月中之後,有關這份富士大噴火的防災報告,才漸漸有新聞媒體討論。「無關是不是新型冠狀病毒的問題,防災準備不能鬆懈。」東大火山研究學者荒牧重雄表示。
公害污染
污染治理
國際新聞
日本
火山爆發
災害防範
災難應變
武漢肺炎
防治
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
摘錄自2020年5月12日聯合報報導
海洋動物每逢大遷徙時,或現離群迷路甚至受傷的意外,幸獲人類幫助才可保命重回大海。日本江之島最近就有一條海豚因為意外被沖上沙灘,嚴重脫水下奄奄一息,無法自行返回水面。附近的水族館人員隨即到達現場協助救援,成功把海豚送回屬於牠的海洋。
江之島民眾於周六(9日)早上在沙灘發現一隻海豚被沖到岸上,隨即打電話聯絡新江之島水族館,希望派人前往現場幫忙。館內數位職員包括獸醫迅速到場並在沙灘發現該尾奄奄一息的海豚,職員馬上用毛巾包起牠,並進行檢查。
獸醫發現海豚屬雌性,身長超過2米,估計是迷路而闖到沙灘。但當時因為脫水顯得非常虛弱,故先為牠在身上澆水之外,亦打營養針補充體力。經歷3小時的救援,海豚的情況有所好轉,數位職員遂馬上合力抬起海豚,把牠送回大海。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
摘錄自2020年5月10日中國新聞網報導
5月10日正在昆明舉行的政協雲南省第12屆委員會第三次會議上,中國農工民主黨雲南省委提交集體提案,建議構建瀾滄江-湄公河次區域國家間大氣污染防控合作機制,共同治理大氣區域性污染。
具體而言,合作平台方面:瀾湄次區域國家應構建對話平台及跨國生態環境保護新模式,制定共同防控污染的政策制度,共同推動制定實施多邊區域生態環保戰略與行動計劃;進一步構建跨國技術交流平台,開展大氣環境數據共享,建立預警應急響應機制。
合作框架方面,建議建立一套瀾湄次區域各國間的伙伴關係系統,制定越境空氣污染防控制度和法律規範,從而使瀾湄各國在深化越境空氣污染合作治理時能更為系統化、更具可行性。
公害污染
污染治理
國際新聞
中國雲南省
東南亞國家
區域發展
大氣汙染
環境監測數據
防治
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
這個階段會給cute-dl添加循環層,使之能夠支持RNN–循環神經網絡. 具體目標包括:
RNN模型用來捕捉序列數據的特徵. 給定一個長度為T的輸入系列\(X=(x_1, x_2, .., X_T)\), RNN層輸出一個長度為T的序列\(H=(h_1, h_2, …, H_T)\), 對於任意時間步t, 可以表示為:
\[H_t = δ(X_tW_x + H_{t-1}W_h + b), \quad t = 2, 3, .., T \]
函數δ是sigmoid函數:
\[δ = \frac{1}{1 + e^{-x}} \]
\(H_t\)包含了前面第1到t-1步的所有信息。 和CNN層類似, CNN層在空間上共享參數, RNN層在時間步上共享參數\(W_x, W_h, b\).
RNN層中隱藏層的數量為T-2, 如果T較大(超過10), 反向傳播是很容易出現梯度爆炸. GRU和LSTM就是為了解決這個問題而誕生, 這兩種模型,可以讓RNN能夠支持長度超過1000的輸入序列。
GRU使用了不同功能的門控單元, 分別捕捉序列上不同時間跨度的的依賴關係。每個門控單元都會都有獨立的參數, 這些參數在時間步上共享。
GRU的門控單元有:
\(R_t = δ(X_tW^r_x + H_{t-1}W^r_h + b^r)\), 重置門用於捕捉短期依賴關係.
\(U_t = δ(X_tW^u_x + H_{t-1}W^u_h + b^u)\), 更新門用於捕捉長期依賴關係
\(\bar{H}_t = tanh(X_t\bar{W}_x + (R_t * H_{t-1})\bar{W}_h + \bar{b})\)
除此之外, 還有一個輸出單元:
\(H_t = U_t * H_{t-1} + (1-U_t)*\bar{H}_t\)
LSTM的設計思路和GRU類似, 同樣使用了多個門控單元:
\(I_t = δ(X_tW^i_x + H_{t-1}W^i_h + b^i)\), 輸入門,過濾記憶門的輸出.
\(F_t = δ(X_tW^f_x + H_{t-1}W^f_h + b^f)\), 遺忘門, 過濾前面時間步的記憶.
\(O_t = δ(X_tW^o_x + H_{t-1}W^o_h + b^o)\), 輸出門, 過濾當前時間步的記憶.
\(M_t = tanh(X_tW^m_x + H_{t-1}W^m_h + b^m)\), 記憶門.
它還有自己獨有的記憶單元和輸出單元:
\(\bar{M}_t = F_t * \bar{M}_{t-1} + I_t * M_t\)
\(H_t = O_t * tanh(\bar{M}_t)\)
設計要求:
文件: cutedl/rnn_layers.py, 類名: RNN
這個類是RNN層基類, 它主要功能是控制向前傳播和向後傳播的主流程.
初始化參數:
'''
out_units 輸出單元數
in_units 輸入單元數
stateful 保留當前批次的最後一個時間步的狀態作為下一個批次的輸入狀態, 默認False不保留
RNN 的輸入形狀是(m, t, in_units)
m: batch_size
t: 輸入系列的長度
in_units: 輸入單元數頁是輸入向量的維數
輸出形狀是(m, t, out_units)
'''
def __init__(self, out_units, in_units=None, stateful=False, activation='linear'):
向前傳播
def forward(self, in_batch, training):
m, T, n = in_batch.shape
out_units = self.__out_units
#所有時間步的輸出
hstatus = np.zeros((m, T, out_units))
#上一步的輸出
pre_hs = self.__pre_hs
if pre_hs is None:
pre_hs = np.zeros((m, out_units))
#隱藏層循環過程, 沿時間步執行
for t in range(T):
hstatus[:, t, :] = self.hiden_forward(in_batch[:,t,:], pre_hs, training)
pre_hs = hstatus[:, t, :]
self.__pre_hs = pre_hs
#pdb.set_trace()
if not self.stateful:
self.__pre_hs = None
return hstatus
反向傳播
def backward(self, gradient):
m, T, n = gradient.shape
in_units = self.__in_units
grad_x = np.zeros((m, T, in_units))
#pdb.set_trace()
#從最後一個梯度開始反向執行.
for t in range(T-1, -1, -1):
grad_x[:,t,:], grad_hs = self.hiden_backward(gradient[:,t,:])
#pdb.set_trace()
if t - 1 >= 0:
gradient[:,t-1,:] = gradient[:,t-1,:] + grad_hs
#pdb.set_trace()
return grad_x
\[sigmoid = \frac{1}{1+e^{-x}} \]
\[\frac{d}{dx}sigmoid = sigmoid(1-sigmoid) \]
\[tanh = \frac{e^x – e^{-x}}{e^x + e^{-x}} \]
\[\frac{d}{dx}tanh = 1 – tanh^2 \]
文件: cutedl/rnn_layers.py, 類名: GateUint
門控單元是RNN層基礎的參數單元. 和Dense層類似,它是Layer的子類,負責學習和使用參數。但在學習和使用參數的方式上有很大的不同:
下面我們會主要看一下GateUnit特別之處的代碼.
在__ init__方法中定義參數和棧:
#3個參數
self.__W = None #當前時間步in_batch權重參數
self.__Wh = None #上一步輸出的權重參數
self.__b = None #偏置量參數
#輸入棧
self.__hs = [] #上一步輸出
self.__in_batchs = [] #當前時間步的in_batch
正向傳播:
def forward(self, in_batch, hs, training):
W = self.__W.value
b = self.__b.value
Wh = self.__Wh.value
out = in_batch @ W + hs @ Wh + b
if training:
#向前傳播訓練時把上一個時間步的輸出和當前時間步的in_batch壓棧
self.__hs.append(hs)
self.__in_batchs.append(in_batch)
#確保反向傳播開始時參數的梯度為空
self.__W.gradient = None
self.__Wh.gradient = None
self.__b.gradient = None
return self.activation(out)
反向傳播:
def backward(self, gradient):
grad = self.activation.grad(gradient)
W = self.__W.value
Wh = self.__Wh.value
pre_hs = self.__hs.pop()
in_batch = self.__in_batchs.pop()
grad_in_batch = grad @ W.T
grad_W = in_batch.T @ grad
grad_hs = grad @ Wh.T
grad_Wh = pre_hs.T @ grad
grad_b = grad.sum(axis=0)
#反向傳播計算
if self.__W.gradient is None:
#當前批次第一次
self.__W.gradient = grad_W
else:
#累積當前批次的所有梯度
self.__W.gradient = self.__W.gradient + grad_W
if self.__Wh.gradient is None:
self.__Wh.gradient = grad_Wh
else:
self.__Wh.gradient = self.__Wh.gradient + grad_Wh
if self.__b.gradient is None:
self.__b.gradient = grad_b
else:
self.__b.gradient = self.__b.gradient + grad_b
return grad_in_batch, grad_hs
文件: cutedl/rnn_layers.py, 類名: GRU
隱藏單初始化:
def set_parent(self, parent):
super().set_parent(parent)
out_units = self.out_units
in_units = self.in_units
#pdb.set_trace()
#重置門
self.__g_reset = GateUnit(out_units, in_units)
#更新門
self.__g_update = GateUnit(out_units, in_units)
#候選輸出門
self.__g_cddout = GateUnit(out_units, in_units, activation='tanh')
self.__g_reset.set_parent(self)
self.__g_update.set_parent(self)
self.__g_cddout.set_parent(self)
#重置門乘法單元
self.__u_gr = MultiplyUnit()
#輸出單元
self.__u_out = GRUOutUnit()
向前傳播:
def hiden_forward(self, in_batch, pre_hs, training):
gr = self.__g_reset.forward(in_batch, pre_hs, training)
gu = self.__g_update.forward(in_batch, pre_hs, training)
ugr = self.__u_gr.forward(gr, pre_hs, training)
cddo = self.__g_cddout.forward(in_batch, ugr, training)
hs = self.__u_out.forward(gu, pre_hs, cddo, training)
return hs
反向傳播:
def hiden_backward(self, gradient):
grad_gu, grad_pre_hs, grad_cddo = self.__u_out.backward(gradient)
#pdb.set_trace()
grad_in_batch, grad_ugr = self.__g_cddout.backward(grad_cddo)
#計算梯度的過程中需要累積上一層輸出的梯度
grad_gr, g_pre_hs = self.__u_gr.backward(grad_ugr)
grad_pre_hs = grad_pre_hs + g_pre_hs
g_in_batch, g_pre_hs = self.__g_update.backward(grad_gu)
grad_in_batch = grad_in_batch + g_in_batch
grad_pre_hs = grad_pre_hs + g_pre_hs
g_in_batch, g_pre_hs = self.__g_reset.backward(grad_gr)
grad_in_batch = grad_in_batch + g_in_batch
grad_pre_hs = grad_pre_hs + g_pre_hs
#pdb.set_trace()
return grad_in_batch, grad_pre_hs
文件: cutedl/rnn_layers.py, 類名: LSTM
隱藏單元初始化:
def set_parent(self, layer):
super().set_parent(layer)
in_units = self.in_units
out_units = self.out_units
#輸入門
self.__g_in = GateUnit(out_units, in_units)
#遺忘門
self.__g_forget = GateUnit(out_units, in_units)
#輸出門
self.__g_out = GateUnit(out_units, in_units)
#記憶門
self.__g_memory = GateUnit(out_units, in_units, activation='tanh')
self.__g_in.set_parent(self)
self.__g_forget.set_parent(self)
self.__g_out.set_parent(self)
self.__g_memory.set_parent(self)
#記憶單元
self.__memory_unit =LSTMMemoryUnit()
#輸出單元
self.__out_unit = LSTMOutUnit()
向前傳播:
def hiden_forward(self, in_batch, hs, training):
g_in = self.__g_in.forward(in_batch, hs, training)
#pdb.set_trace()
g_forget = self.__g_forget.forward(in_batch, hs, training)
g_out = self.__g_out.forward(in_batch, hs, training)
g_memory = self.__g_memory.forward(in_batch, hs, training)
memory = self.__memory_unit.forward(g_forget, g_in, g_memory, training)
cur_hs = self.__out_unit.forward(g_out, memory, training)
return cur_hs
反向傳播:
def hiden_backward(self, gradient):
#pdb.set_trace()
grad_out, grad_memory = self.__out_unit.backward(gradient)
grad_forget, grad_in, grad_gm = self.__memory_unit.backward(grad_memory)
grad_in_batch, grad_hs = self.__g_memory.backward(grad_gm)
tmp1, tmp2 = self.__g_out.backward(grad_out)
grad_in_batch += tmp1
grad_hs += tmp2
tmp1, tmp2 = self.__g_forget.backward(grad_forget)
grad_in_batch += tmp1
grad_hs += tmp2
tmp1, tmp2 = self.__g_in.backward(grad_in)
grad_in_batch += tmp1
grad_hs += tmp2
return grad_in_batch, grad_hs
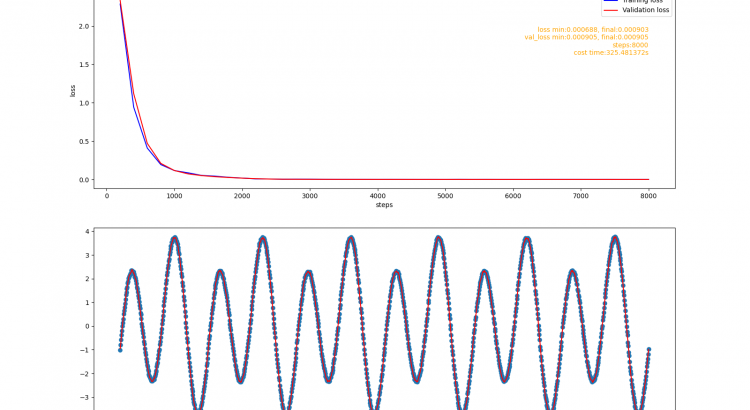
接下來, 驗證示例將會構建一個簡單的RNN模型, 使用該模型擬合一個正餘弦疊加函數:
#採樣函數
def sample_function(x):
y = 3*np.sin(2 * x * np.pi) + np.cos(x * np.pi) + np.random.uniform(-0.05,0.05,len(x))
return y
訓練數據集和測試數據集在這個函數的不同定義域區間內樣. 訓練數據集的採樣區間為[1, 200.01), 測試數據集的採樣區間為[200.02, 240.002). 模型任務是預測這個函數值的序列.
示例代碼在examples/rnn/fit_function.py文件中.
def fit_gru():
model = Model([
rnn.GRU(32, 1),
nn.Filter(),
nn.Dense(32),
nn.Dense(1, activation='linear')
])
model.assemble()
fit('gru', model)
訓練報告:
def fit_lstm():
model = Model([
rnn.LSTM(32, 1),
nn.Filter(),
nn.Dense(2),
nn.Dense(1, activation='linear')
])
model.assemble()
fit('lstm', model)
訓練報告:
這個階段,框架新增了RNN的兩個最常見的實現:GRU和LSTM, 相應地增加了它需要的激活函數. cute-dl已經具備了構建最基礎RNN模型的能力。通過驗證發現, GRU模型和LSTM模型在簡單任務上都表現出了很好的性能。會添加嵌入層,使框架能夠構建文本分類任務的模型,然後在imdb-review(電影評價)數據集上進行驗證.
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
Spring容器中的組件默認是單例的,在Spring啟動時就會實例化並初始化這些對象,將其放到Spring容器中,之後,每次獲取對象時,直接從Spring容器中獲取,而不再創建對象。如果每次從Spring容器中獲取對象時,都要創建一個新的實例對象,該如何處理呢?此時就需要使用@Scope註解設置組件的作用域。
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
@Scope註解能夠設置組件的作用域,我們先來看@Scope註解類的源碼,如下所示。
package org.springframework.context.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.core.annotation.AliasFor;
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Scope {
@AliasFor("scopeName")
String value() default "";
/**
* Specifies the name of the scope to use for the annotated component/bean.
* <p>Defaults to an empty string ({@code ""}) which implies
* {@link ConfigurableBeanFactory#SCOPE_SINGLETON SCOPE_SINGLETON}.
* @since 4.2
* @see ConfigurableBeanFactory#SCOPE_PROTOTYPE
* @see ConfigurableBeanFactory#SCOPE_SINGLETON
* @see org.springframework.web.context.WebApplicationContext#SCOPE_REQUEST
* @see org.springframework.web.context.WebApplicationContext#SCOPE_SESSION
* @see #value
*/
@AliasFor("value")
String scopeName() default "";
ScopedProxyMode proxyMode() default ScopedProxyMode.DEFAULT;
}
從源碼中可以看出,在@Scope註解中可以設置如下值。
ConfigurableBeanFactory#SCOPE_PROTOTYPE
ConfigurableBeanFactory#SCOPE_SINGLETON
org.springframework.web.context.WebApplicationContext#SCOPE_REQUEST
org.springframework.web.context.WebApplicationContext#SCOPE_SESSION
很明顯,在@Scope註解中可以設置的值包括ConfigurableBeanFactory接口中的SCOPE_PROTOTYPE和SCOPE_SINGLETON,以及WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION。這些都是什麼鬼?別急,我們來一個個查看。
首先,我們進入到ConfigurableBeanFactory接口中,發現在ConfigurableBeanFactory類中存在兩個常量的定義,如下所示。
public interface ConfigurableBeanFactory extends HierarchicalBeanFactory, SingletonBeanRegistry {
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
/*****************此處省略N多行代碼*******************/
}
沒錯,SCOPE_SINGLETON就是singleton,SCOPE_PROTOTYPE就是prototype。
那麼,WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION又是什麼鬼呢?就是說,當我們使用了Web容器來運行Spring應用時,在@Scope註解中可以設置WebApplicationContext類中SCOPE_REQUEST和SCOPE_SESSION的值,而SCOPE_REQUEST的值就是request,SCOPE_SESSION的值就是session。
綜上,在@Scope註解中的取值如下所示。
其中,request和session作用域是需要Web環境支持的,這兩個值基本上使用不到,如果我們使用Web容器來運行Spring應用時,如果需要將組件的實例對象的作用域設置為request和session,我們通常會使用request.setAttribute(“key”,object)和session.setAttribute(“key”, object)的形式來將對象實例設置到request和session中,通常不會使用@Scope註解來進行設置。
首先,我們在io.mykit.spring.plugins.register.config包下創建PersonConfig2配置類,在PersonConfig2配置類中實例化一個Person對象,並將其放置在Spring容器中,如下所示。
package io.mykit.spring.plugins.register.config;
import io.mykit.spring.bean.Person;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author binghe
* @version 1.0.0
* @description 測試@Scope註解設置的作用域
*/
@Configuration
public class PersonConfig2 {
@Bean("person")
public Person person(){
return new Person("binghe002", 18);
}
}
接下來,在SpringBeanTest類中創建testAnnotationConfig2()測試方法,在testAnnotationConfig2()方法中,創建ApplicationContext對象,創建完畢后,從Spring容器中按照id獲取兩個Person對象,並打印兩個對象是否是同一個對象,代碼如下所示。
@Test
public void testAnnotationConfig2(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
//從Spring容器中獲取到的對象默認是單實例的
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
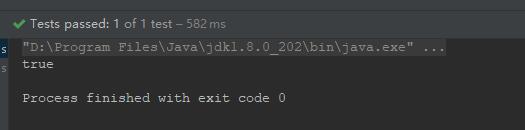
System.out.println(person1 == person2);
}
由於對象在Spring容器中默認是單實例的,所以,Spring容器在啟動時就會將實例對象加載到Spring容器中,之後,每次從Spring容器中獲取實例對象,直接將對象返回,而不必在創建新對象實例,所以,此時testAnnotationConfig2()方法會輸出true。如下所示。
這也驗證了我們的結論:對象在Spring容器中默認是單實例的,Spring容器在啟動時就會將實例對象加載到Spring容器中,之後,每次從Spring容器中獲取實例對象,直接將對象返回,而不必在創建新對象實例。
修改Spring容器中組件的作用域,我們需要藉助於@Scope註解,此時,我們將PersonConfig2類中Person對象的作用域修改成prototype,如下所示。
@Configuration
public class PersonConfig2 {
@Scope("prototype")
@Bean("person")
public Person person(){
return new Person("binghe002", 18);
}
}
其實,使用@Scope設置作用域就等同於在XML文件中為bean設置scope作用域,如下所示。
此時,我們再次運行SpringBeanTest類的testAnnotationConfig2()方法,此時,從Spring容器中獲取到的person1對象和person2對象還是同一個對象嗎?
通過輸出結果可以看出,此時,輸出的person1對象和person2對象已經不是同一個對象了。
接下來,我們驗證下在單實例作用域下,Spring是在什麼時候創建對象的呢?
首先,我們將PersonConfig2類中的Person對象的作用域修改成單實例,並在返回Person對象之前打印相關的信息,如下所示。
@Configuration
public class PersonConfig2 {
@Scope
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
接下來,我們在SpringBeanTest類中創建testAnnotationConfig3()方法,在testAnnotationConfig3()方法中,我們只創建Spring容器,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
}
此時,我們運行SpringBeanTest類中的testAnnotationConfig3()方法,輸出的結果信息如下所示。
從輸出的結果信息可以看出,Spring容器在創建的時候,就將@Scope註解標註為singleton的組件進行了實例化,並加載到Spring容器中。
接下來,我們運行SpringBeanTest類中的testAnnotationConfig2(),結果信息如下所示。
說明,Spring容器在啟動時,將單實例組件實例化之後,加載到Spring容器中,以後每次從容器中獲取組件實例對象,直接返回相應的對象,而不必在創建新對象。
如果我們將對象的作用域修改成多實例,那什麼時候創建對象呢?
此時,我們將PersonConfig2類的Person對象的作用域修改成多實例,如下所示。
@Configuration
public class PersonConfig2 {
@Scope("prototype")
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,輸出的結果信息如下所示。
可以看到,終端並沒有輸出任何信息,說明在創建Spring容器時,並不會實例化和加載多實例對象,那多實例對象是什麼時候實例化的呢?接下來,我們在SpringBeanTest類中的testAnnotationConfig3()方法中添加一行獲取Person對象的代碼,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
從結果信息中,可以看出,當向Spring容器中獲取Person實例對象時,Spring容器實例化了Person對象,並將其加載到Spring容器中。
那麼,問題來了,此時Spring容器是否只實例化一個Person對象呢?我們在SpringBeanTest類中的testAnnotationConfig3()方法中再添加一行獲取Person對象的代碼,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
從輸出結果可以看出,當對象的Scope作用域為多實例時,每次向Spring容器獲取對象時,都會創建一個新的對象並返回。此時,獲取到的person1和person2就不是同一個對象了,我們也可以打印結果信息來進行驗證,此時在SpringBeanTest類中的testAnnotationConfig3()方法中打印兩個對象是否相等,如下所示。
@Test
public void testAnnotationConfig3(){
ApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig2.class);
Object person1 = context.getBean("person");
Object person2 = context.getBean("person");
System.out.println(person1 == person2);
}
此時,我們再次運行SpringBeanTest類中的testAnnotationConfig3()方法,結果信息如下所示。
可以看到,當對象是多實例時,每次從Spring容器中獲取對象時,都會創建新的實例對象,並且每個實例對象都不相等。
單例bean是整個應用共享的,所以需要考慮到線程安全問題,之前在玩springmvc的時候,springmvc中controller默認是單例的,有些開發者在controller中創建了一些變量,那麼這些變量實際上就變成共享的了,controller可能會被很多線程同時訪問,這些線程併發去修改controller中的共享變量,可能會出現數據錯亂的問題;所以使用的時候需要特別注意。
多例bean每次獲取的時候都會重新創建,如果這個bean比較複雜,創建時間比較長,會影響系統的性能,這個地方需要注意。
如果Spring內置的幾種sope都無法滿足我們的需求的時候,我們可以自定義bean的作用域。
自定義Scope主要分為三個步驟,如下所示。
(1)實現Scope接口
我們先來看下Scope接口的定義,如下所示。
package org.springframework.beans.factory.config;
import org.springframework.beans.factory.ObjectFactory;
import org.springframework.lang.Nullable;
public interface Scope {
/**
* 返回當前作用域中name對應的bean對象
* name:需要檢索的bean的名稱
* objectFactory:如果name對應的bean在當前作用域中沒有找到,那麼可以調用這個ObjectFactory來創建這個對象
**/
Object get(String name, ObjectFactory<?> objectFactory);
/**
* 將name對應的bean從當前作用域中移除
**/
@Nullable
Object remove(String name);
/**
* 用於註冊銷毀回調,如果想要銷毀相應的對象,則由Spring容器註冊相應的銷毀回調,而由自定義作用域選擇是不是要銷毀相應的對象
*/
void registerDestructionCallback(String name, Runnable callback);
/**
* 用於解析相應的上下文數據,比如request作用域將返回request中的屬性。
*/
@Nullable
Object resolveContextualObject(String key);
/**
* 作用域的會話標識,比如session作用域將是sessionId
*/
@Nullable
String getConversationId();
}
(2)將Scope註冊到容器
需要調用org.springframework.beans.factory.config.ConfigurableBeanFactory#registerScope的方法,看一下這個方法的聲明
/**
* 向容器中註冊自定義的Scope
*scopeName:作用域名稱
* scope:作用域對象
**/
void registerScope(String scopeName, Scope scope);
(3)使用自定義的作用域
定義bean的時候,指定bean的scope屬性為自定義的作用域名稱。
例如,我們來實現一個線程級別的bean作用域,同一個線程中同名的bean是同一個實例,不同的線程中的bean是不同的實例。
這裏,要求bean在線程中是共享的,所以我們可以通過ThreadLocal來實現,ThreadLocal可以實現線程中數據的共享。
此時,我們在io.mykit.spring.plugins.register.scope包下新建ThreadScope類,如下所示。
package io.mykit.spring.plugins.register.scope;
import org.springframework.beans.factory.ObjectFactory;
import org.springframework.beans.factory.config.Scope;
import org.springframework.lang.Nullable;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* 自定義本地線程級別的bean作用域,不同的線程中對應的bean實例是不同的,同一個線程中同名的bean是同一個實例
*/
public class ThreadScope implements Scope {
public static final String THREAD_SCOPE = "thread";
private ThreadLocal<Map<String, Object>> beanMap = new ThreadLocal() {
@Override
protected Object initialValue() {
return new HashMap<>();
}
};
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
Object bean = beanMap.get().get(name);
if (Objects.isNull(bean)) {
bean = objectFactory.getObject();
beanMap.get().put(name, bean);
}
return bean;
}
@Nullable
@Override
public Object remove(String name) {
return this.beanMap.get().remove(name);
}
@Override
public void registerDestructionCallback(String name, Runnable callback) {
//bean作用域範圍結束的時候調用的方法,用於bean清理
System.out.println(name);
}
@Nullable
@Override
public Object resolveContextualObject(String key) {
return null;
}
@Nullable
@Override
public String getConversationId() {
return Thread.currentThread().getName();
}
}
在ThreadScope類中,我們定義了一個常量THREAD_SCOPE,在定義bean的時候給scope使用。
接下來,我們在io.mykit.spring.plugins.register.config包下創建PersonConfig3類,並使用@Scope(“thread”)註解標註Person對象的作用域為Thread範圍,如下所示。
package io.mykit.spring.plugins.register.config;
import io.mykit.spring.bean.Person;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
/**
* @author binghe
* @version 1.0.0
* @description 測試@Scope註解設置的作用域
*/
@Configuration
public class PersonConfig3 {
@Scope("thread")
@Bean("person")
public Person person(){
System.out.println("給容器中添加Person....");
return new Person("binghe002", 18);
}
}
最後,我們在SpringBeanTest類中創建testAnnotationConfig4()方法,在testAnnotationConfig4()方法中創建Spring容器,並向Spring容器中註冊ThreadScope對象,接下來,使用循環創建兩個Thread線程,並分別在每個線程中獲取兩個Person對象,如下所示。
@Test
public void testAnnotationConfig4(){
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(PersonConfig3.class);
//向容器中註冊自定義的scope
context.getBeanFactory().registerScope(ThreadScope.THREAD_SCOPE, new ThreadScope());
//使用容器獲取bean
for (int i = 0; i < 2; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread() + "," + context.getBean("person"));
System.out.println(Thread.currentThread() + "," + context.getBean("person"));
}).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
此時,我們運行SpringBeanTest類的testAnnotationConfig4()方法,輸出的結果信息如下所示。
從輸出中可以看到,bean在同樣的線程中獲取到的是同一個bean的實例,不同的線程中bean的實例是不同的。
注意:這裏,我將Person類進行了相應的調整,去掉Lombok的註解,手動寫構造函數和setter與getter方法,如下所示。
package io.mykit.spring.bean;
import java.io.Serializable;
/**
* @author binghe
* @version 1.0.0
* @description 測試實體類
*/
public class Person implements Serializable {
private static final long serialVersionUID = 7387479910468805194L;
private String name;
private Integer age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
好了,咱們今天就聊到這兒吧!別忘了給個在看和轉發,讓更多的人看到,一起學習一起進步!!
項目工程源碼已經提交到GitHub:https://github.com/sunshinelyz/spring-annotation
如果覺得文章對你有點幫助,請微信搜索並關注「 冰河技術 」微信公眾號,跟冰河學習Spring註解驅動開發。公眾號回復“spring註解”關鍵字,領取Spring註解驅動開發核心知識圖,讓Spring註解驅動開發不再迷茫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
摘錄自2020年5月27日中央社報導
「每日晨報」(Daily Sabah)報導,博斯普魯斯海峽(Bosporus)水色自26日起轉變成「土耳其藍」。伊斯坦堡科技大學(Istanbul Technical University)教授托羅斯(Huseyin Toros)認為,東北風是導致「海水變色」主要原因。
托羅斯指出:「單細胞生物被東北風曳引進入博斯普魯斯海峽,海水表面經過折射,轉變成土耳其藍色。在此一大氣環境下的氣流、海平面下的活動、不同微生物、白天陽光變化等因素也可能導致海水顏色產生變化。」他表示,海水將於幾天內恢復「本色」。
美國國家航空暨太空總署(NASA)的衛星於當年5月29日首度補捉到黑海浮游生物激增的圖像。漁夫們相信,海中出現大量浮游生物意味當年鯷魚產量將會大增。但是浮游生物也會消耗水中大量氧氣,從而對其他海洋生物造成傷害。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準

《SpringBoot-2.3容器化技術》系列,旨在和大家一起學習實踐2.3版本帶來的最新容器化技術,讓咱們的Java應用更加適應容器化環境,在雲計算時代依舊緊跟主流,保持競爭力;
全系列文章分為主題和輔助兩部分,主題部分如下:
為了讓應用更適應容器化環境,SpringBoot2.3版本推出了新的探針技術,《掌握SpringBoot-2.3的容器探針》系列旨在與您一起學習和實踐這些新技術,分為三個階段:
如下圖紅框所示,2.3版本的容器探針特性早在預覽版(v2.3.0.M4)就已經發布:
如今v2.3.0.RELEASE已發布,可以放心的學習和使用該特性了,首先把基礎知識點列出來,確保準備工作OK;
下面是掌握探針技術所需的基礎知識,也是本文的主要內容:
接下來逐個學習,有了這些知識積累,我們才能更好的閱讀官方資料,開發適合自己業務場景的探針;
首先,SpringBoot為kubernetes提供了兩個actuator項,但是那些並未部署在kubernetes的SringBoot應用呢?用不上這兩項也要對外暴露這兩個服務地址嗎?
其次,就緒探針是什麼時候開始返回200返回碼的?應用啟動階段,業務服務可能需要一段時間才能正常工作,就緒探針要是提前返回了200,那k8s就認為容器可以正常工作了,這時候把外部請求調度過來是無法正常響應的,所以搞清楚就緒探針的狀態變化邏輯很重要;
最後,也是最重要的一點:有的場景下,例如外部依賴服務異常、本地全局異常等情況下,業務不想對外提供服務,等到問題解決后業務又可以對外提供服務了,如果此時我們能自己寫代碼控制就緒探針的返回碼,那就做到了控制kubernetes是否將外部請求調度到此容器上,這可是個很實用的功能!
面對上述三個問題您是否會感慨:看似簡單的容器探針技術,想要用好還需掌握更多知識,接下來的文章中咱們一起努力吧,從知識覆蓋到實戰操練,終究會掌握這門實用技術;
https://github.com/zq2599/blog_demos
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準
3禁左即是禁止掉頭左轉與掉頭是有一定關係的,因為大多數情況下掉頭需要佔用左轉車道,所以禁止左轉意味着不能掉頭,除非該路口除了有“禁止左轉”的標誌外,還同時有“允許掉頭”的標誌,則可掉頭。下面這些情況可以掉頭1路口有掉頭標誌的可掉頭按照信號燈的指示進行掉頭,如果沒有信號燈,則根據路況有左轉標誌的,在不影響其他車輛通行或阻礙行人的情況進行掉頭,在這裏得提醒一下,有些掉頭車道是在最右側的。
今天小編開心的開着五菱宏光去兜風,準備右轉的時候在一個紅燈路口停了下來,後方的車輛不停的按着喇叭來催前面第一輛車輛,看來又是一個新手,不知道沒方向指示的紅燈是允許掉頭的。
但是今天我們討論的是紅燈能否掉頭的問題,有禁止標誌的路口大夥都看得懂,但是沒明確指示的就不一定了,一起來學習一下吧,剛拿到駕照的朋友再也不擔心給人家嗶嗶的催個不停了。
車輛掉頭規定
一開始我們先來看一下違章掉頭將會受到什麼樣的處罰,駕駛機動車違反禁令標誌、禁止、標線指示的,將一次記3分,部分地區還將罰200元。
禁止掉頭的九種情況
1
斑馬線處禁止掉頭
有些道路上設有斑馬線,雖然這一塊地方沒有明確禁止掉頭標識,但是機動車是不允許在斑馬線上掉頭的,就算在允許掉頭的路口,也要越過斑馬線才可以掉頭。
2
黃色實線禁止掉頭
在行至無“禁止掉頭”標誌的路口,是允許掉頭的,但是要注意道路中心線的虛實,如果是單黃實線或者雙黃實線都是禁止掉頭的。
3
禁左即是禁止掉頭
左轉與掉頭是有一定關係的,因為大多數情況下掉頭需要佔用左轉車道,所以禁止左轉意味着不能掉頭,除非該路口除了有“禁止左轉”的標誌外,還同時有“允許掉頭”的標誌,則可掉頭。
下面這些情況可以掉頭
1
路口有掉頭標誌的可掉頭
按照信號燈的指示進行掉頭,如果沒有信號燈,則根據路況有左轉標誌的,在不影響其他車輛通行或阻礙行人的情況進行掉頭,在這裏得提醒一下,有些掉頭車道是在最右側的。
2
黃色網格線可掉頭
黃色網格線大家可能都很清楚,就是嚴禁停車的意思,但在該區域內,只要沒有設置中間隔離護欄,是可以掉頭的,等同於“允許掉頭”的意思。
3
黃色虛實線可掉頭
如果是一虛一實的黃色線,是可以掉頭的,虛線一側車輛可向實線一側通行,實線一側的車輛是不允許向虛線一邊通行的。
總結:考試背得滾瓜爛熟的交規一畢業就給回教練了,加上一些馬路上交通標支模糊指引不明確,很容易造成新手犯錯,還會被後面車輛“嗶”個不停,希望通過這篇文章學習后,大家可以對掉頭的情況了如指掌。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※回頭車貨運收費標準