Vuex是一個專為Vue.js設計的狀態管理庫,適用於多組件共享狀態的場景。Vuex能集中式的存儲和維護所有組件的狀態,並提供相關規則保證狀態的獨立性、正確性和可預測性,這不僅讓調試變得可追蹤,還讓代碼變得更結構化且易維護。本文所使用的Vuex,其版本是3.1.1。
一、基本用法
首先需要引入Vue和Vuex兩個庫,如果像下面這樣在Vue之後引入Vuex,那麼Vuex會自動調用Vue.use()方法註冊其自身;但如果以模塊的方式引用,那麼就得顯式地調用Vue.use()。注意,因為Vuex依賴Promise,所以對於那些不支持Promise的瀏覽器,要使用Vuex的話,得引入相關的polyfill庫,例如es6-promise。
<script src="js/vue.js"></script>
<script src="js/vuex.js"></script>
然後創建Vuex應用的核心:Store(倉庫)。它是一個容器,保存着大量的響應式狀態(State),並且這些狀態不能直接修改,需要顯式地將修改請求提交到Mutation(變更)中才能實現更新,因為這樣便於追蹤每個狀態的變化。在下面的示例中,初始化了一個digit狀態,並在mutations選項中添加了兩個可將其修改的方法。
const store = new Vuex.Store({
state: {
digit: 0
},
mutations: {
add: state => state.digit++,
minus: state => state.digit--
}
});
接着創建根實例,並將store實例注入,從而讓整個應用都能讀寫其中的狀態,在組件中可通過$store屬性訪問到它,如下所示,以計算屬性的方式讀取digit狀態,並通過調用commit()方法來修改該狀態。
var vm = new Vue({
el: "#container",
store: store,
computed: {
digit() {
return this.$store.state.digit;
}
},
methods: {
add() {
this.$store.commit("add");
},
minus() {
this.$store.commit("minus");
}
}
});
最後將根實例中的方法分別註冊到兩個按鈕的點擊事件中,如下所示,每當點擊這兩個按鈕時,狀態就會更新,並在頁面中显示。
<div id="container">
<p>{{digit}}</p>
<button @click="add">增加</button>
<button @click="minus">減少</button>
</div>
二、主要組成
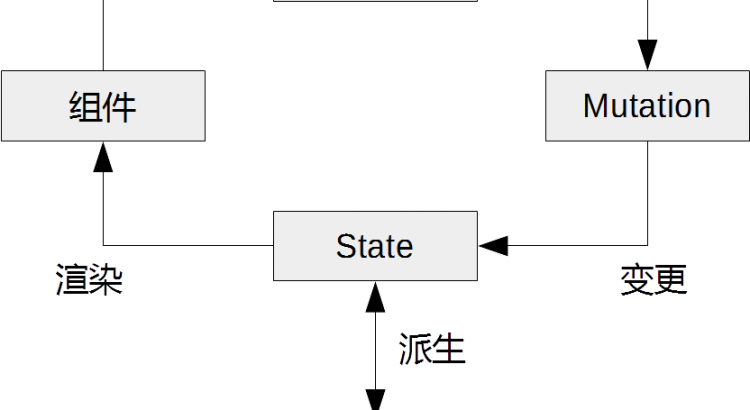
Vuex的主要組成除了上一節提到的Store、State和Mutation之外,還包括Getter和Action,本節會對其中的四個做重點講解,它們之間的關係如圖2所示。
圖2 四者的關係
1)State
State是一個可存儲狀態的對象,在應用的任何位置都能被訪問到,並且作為單一數據源(Single Source Of Truth)而存在。
當組件需要讀取大量狀態時,一個個的聲明成計算屬性會顯得過於繁瑣而冗餘,於是Vuex提供了一個名為mapState()的輔助函數,用來將狀態自動映射成計算屬性,它的參數既可以是數組,也可以是對象。
當計算屬性的名稱與狀態名稱相同,並且不需要做額外處理時,可將名稱組成一個字符串數組傳遞給mapState()函數,在組件中可按原名調用,如下所示。
var vm = new Vue({
computed: Vuex.mapState([ "digit" ])
});
當計算屬性的名稱與狀態名稱不同,或者計算屬性讀取的是需要處理的狀態時,可將一個對象傳遞給mapState()函數,其鍵就是計算屬性的名稱,而其值既可以是函數,也可以是字符串,如下代碼所示。如果是函數,那麼它的第一個參數是state,即狀態對象;如果是字符串,那麼就是從state中指定一個狀態作為計算屬性。
var vm = new Vue({
computed: Vuex.mapState({
digit: state => state.digit,
alias: "digit" //相當於state => state.digit
})
});
因為mapState()函數返回的是一個對象,所以當組件內已經包含計算屬性時,可以對其應用擴展運算符(…)來進行合併,如下所示,這是一種極為簡潔的寫法。
var vm = new Vue({
computed: {
name() {},
...Vuex.mapState([ "digit" ])
}
});
2)Getter
Getter是從State中派生出的狀態,當多個組件要對同一個狀態進行相同的處理時,就需要將狀態轉移到Getter中,以免產生重複的冗餘代碼。
Getter相當於Store的計算屬性,它能接收兩個參數,第一個是state對象,第二個是可選的getters對象,該參數能讓不同的Getter之間相互訪問。Getter的返回值會被緩存,並且只有當依賴值發生變化時才會被重新計算。不過當返回值是函數時,其結果就不會被緩存,如下所示,其中caculate返回的是個数字,而sum返回的是個函數。
const store = new Vuex.Store({
state: {
digit: 0
},
getters: {
caculate: state => {
return state.digit + 2;
},
sum: state => right => {
return state.digit + right;
}
}
});
在組件內可通過this.$store.getters訪問到Getter中的數據,如下所示,讀取了上一個示例中的兩個Getter。
var vm = new Vue({
methods: {
add() {
this.$store.getters.caculate;
this.$store.getters.sum(1);
}
}
});
Getter也有一個輔助函數,用來將Getter自動映射為組件的計算屬性,名字叫mapGetters(),其參數也是數組或對象。但與之前的mapState()不同,當參數是對象時,其值不能是函數,只能是字符串,如下所示,為了對比兩種寫法,聲明了兩個computed選項。
var vm = new Vue({
computed: Vuex.mapGetters([ "caculate" ]),
computed: Vuex.mapGetters({
alias: "caculate"
})
});
3)Mutation
更改狀態的唯一途徑是提交Mutation,Vuex中的Mutation類似於事件,也包含一個類型和回調函數,在函數體中可進行狀態更改的邏輯,並且它能接收兩個參數,第一個是state對象,第二個是可選的附加數據,叫載荷(Payload)。下面這個Mutation的類型是“interval”,接收了兩個參數。
const store = new Vuex.Store({
state: {
digit: 0
},
mutations: {
interval: (state, payload) => state.digit += payload.number
}
});
在組件中不能直接調用Mutation的回調函數,得通過this.$store.commit()方法觸發更新,如下所示,採用了兩種提交方式,第一種是傳遞type參數,第二種是傳遞包含type屬性的對象。
var vm = new Vue({
methods: {
interval() {
this.$store.commit("interval", { number: 2 }); //第一種
this.$store.commit({ type: "interval", number: 2 }); //第二種
}
}
});
當多人協作時,Mutation的類型適合寫成常量,這樣更容易維護,也能減少衝突。
const INTERVAL = "interval";
Mutation有一個名為mapMutations()的輔助函數,其寫法和mapState()相同,它能將Mutation自動映射為組件的方法,如下所示。
var vm = new Vue({
methods: Vuex.mapMutations(["interval"])
//相當於
methods: {
interval(payload) {
this.$store.commit(INTERVAL, payload);
}
}
});
注意,為了能追蹤狀態的變更,Mutation只支持同步的更新,如果要異步,那麼得使用Action。
4)Action
Action類似於Mutation,但不同的是它可以包含異步操作,並且只能用來通知Mutation,不會直接更新狀態。Action的回調函數能接收兩個參數,第一個是與Store實例具有相同屬性和方法的context對象(注意,不是Store實例本身),第二個是可選的附加數據,如下所示,調用commit()方法提交了一個Mutation。
const store = new Vuex.Store({
actions: {
interval(context, payload) {
context.commit("interval", payload);
}
}
});
在組件中能通過this.$store.dispatch()方法分發Action,如下所示,與commit()方法一樣,它也有兩種提交方式。
var vm = new Vue({
methods: {
interval() {
this.$store.dispatch("interval", { number: 2 }); //第一種
this.$store.dispatch({type: "interval", number: 2}); //第二種
}
}
});
注意,由於dispatch()方法返回的是一個Promise對象,因此它能以一種更優雅的方式來處理異步操作,如下所示。
var vm = new Vue({
methods: {
interval() {
this.$store.dispatch("interval", { number: 2 }).then(() => {
console.log("success");
});
}
}
});
Action有一個名為mapActions()的輔助函數,其寫法和mapState()相同,它能將Action自動映射為組件的方法,如下所示。
var vm = new Vue({
methods: Vuex.mapActions([ "interval" ])
});
三、模塊
當應用越來越大時,為了避免Store變得過於臃腫,有必要將其拆分到一個個的模塊(Module)中。每個模塊就是一個對象,包含屬於自己的State、Getter、Mutation和Action,甚至還能嵌套其它模塊。
1)局部狀態
對於模塊內部的Getter和Mutation,它們接收的第一個參數是模塊的局部狀態,而Getter的第三個參數rootState和Action的context.rootState屬性可訪問根節點狀態(即全局狀態),如下所示。
const moduleA = {
state: { digit: 0 },
mutations: {
add: state => state.digit++
},
getters: {
caculate: (state, getter, rootState) => {
return state.digit + 2;
}
},
actions: {
interval(context, payload) {
context.commit("add", payload);
}
}
};
2)命名空間
默認情況下,只有在訪問State時需要帶命名空間,而Getter、Mutation和Action的調用方式不變。將之前的moduleA模塊註冊到Store實例中,如下所示,modules選項的值是一個子模塊對象,其鍵是模塊名稱。
const store = new Vuex.Store({
modules: {
a: moduleA
}
});
如果要訪問模塊中的digit狀態,那麼可以像下面這樣寫。
store.state.a.digit;
當模塊的namespaced屬性為true時,它的Getter、Mutation和Action也會帶命名空間,在使用時,需要添加命名空間前綴,如下代碼所示,此舉大大提升了模塊的封裝性和復用性。
const moduleA = {
namespaced: true
};
var vm = new Vue({
el: "#container",
store: store,
methods: {
add() {
this.$store.commit("a/add");
},
caculate() {
this.$store.getters["a/caculate"];
}
}
});
如果要在帶命名空間的模塊中提交全局的Mutation或分發全局的Action,那麼只要將{root: true}作為第三個參數傳給commit()或dispatch()就可實現,如下所示。
var vm = new Vue({
methods: {
add() {
this.$store.dispatch("add", null, { root: true });
this.$store.commit("add", null, { root: true });
}
}
});
如果要在帶命名空間的模塊中註冊全局的Action,那麼需要將其修改成對象的形式,然後添加root屬性並設為true,再將Action原先的定義轉移到handler()函數中,如下所示。
const moduleA = {
actions: {
interval: {
root: true,
handler(context, payload) {}
}
}
};
3)輔助函數
當使用mapState()、mapGetters()、mapMutations()和mapActions()四個輔助函數對帶命名空間的模塊做映射時,需要顯式的包含命名空間,如下所示。
var vm = new Vue({
computed: Vuex.mapState({
digit: state => state.a.digit
}),
methods: Vuex.mapMutations({
add: "a/add"
})
});
這四個輔助函數的第一個參數都是可選的,用於綁定命名空間,可簡化映射過程,如下所示。
var vm = new Vue({
computed: Vuex.mapState("a", {
digit: state => state.digit
}),
methods: Vuex.mapMutations("a", {
add: "add"
})
});
Vuex還提供了另一個輔助函數createNamespacedHelpers(),可創建綁定命名空間的輔助函數,如下所示。
const { mapState, mapMutations } = Vuex.createNamespacedHelpers("a");
四、動態註冊
在創建Store實例后,可通過registerModule()方法動態註冊模塊,如下代碼所示,調用了兩次registerModule()方法,第一次註冊了模塊“a”,第二次註冊了嵌套模塊“a/b”。
const store = new Vuex.Store();
store.registerModule("a", moduleA);
store.registerModule(["a", "b"], moduleAB);
通過store.state.a和store.state.a.b可訪問模塊的局部狀態。如果要卸載動態註冊的模塊,那麼可以通過unregisterModule()方法實現。
registerModule()方法的第三個參數是可選的配置對象,當preserveState屬性的值為true時(如下所示),在註冊模塊時會忽略模塊中的狀態,即無法在store中讀取模塊中的狀態。
store.registerModule("a", moduleA, { preserveState: true });
五、表單處理
表單默認能直接修改組件的狀態,但是在Vuex中,狀態只能由Mutation觸發更新。為了能更好的追蹤狀態的變化,也為了能更符合Vuex的思維,需要讓表單控件與狀態綁定在一起,並通過input或change事件監聽狀態更新的行為,如下所示。
<div id="container">
<input :value="digit" @input="add" />
</div>
然後在Store實例中初始化digit狀態,並添加更新狀態的Mutation,如下所示。
const store = new Vuex.Store({
state: {
digit: 0
},
mutations: {
add: (state, value) => {
state.digit = value;
}
}
});
最後在創建根實例時,將digit狀態映射成它的計算屬性,在事件處理程序add()中調用commit()方法,並將控件的值作為第二個參數傳入,如下所示。
var vm = new Vue({
el: "#container",
store: store,
computed: Vuex.mapState(["digit"]),
methods: {
add(e) {
this.$store.commit("add", e.target.value);
}
}
});
還有一個方法也能實現相同的功能,那就是在控件上使用v-model指令,但需要與帶setter的計算屬性配合,如下所示(只給出了關鍵部分的代碼)。
<div id="container">
<input v-model="digit" />
</div>
<script>
var vm = new Vue({
computed: {
digit: {
get() {
return this.$store.state.digit;
},
set(value) {
this.$store.commit("add", value);
}
}
}
});
</script>
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※台灣寄大陸海運貨物規則及重量限制?
※大陸寄台灣海運費用試算一覽表
※台中搬家,彰化搬家,南投搬家前需注意的眉眉角角,別等搬了再說!